DESCRIPCIÓN DE RSTUDIO
Objetivos
- Instalar R y RStudio
- Familiarizarse con el entorno de RStudio
- Introducir, almacenar e importar datos
- Funciones en RStudio.
Descripción e instalación de R
RStudio es una interfaz que permite acceder de manera sencilla a toda la potencia de R, para utilizar RStudio se requiere haber instalado R previamente.
R es un lenguaje orientado a objetos, es un lenguaje para el cálculo estadístico y la generación de gráficos, que ofrece una gran variedad de técnicas estadísticas y gráficas. Es un entorno de análisis y programación estadísticos que, en su aspecto externo, es similar a S. Es un lenguaje de programación completo con el que se añaden nuevas técnicas mediante la definición de funciones.
Aunque comenzar a trabajar con R es más complejo que hacerlo con programas como SPSS, Statgraphics,…, sin embargo tiene muchas ventajas sobre ellos una de la más importante es que es un software libre en el que colaboran muchos usuarios para ampliar sus funciones.
A lo largo del texto veremos cómo utilizar R para realizar análisis convencionales, como los que se encuentran en BMDP, SAS, SPSS o Statgraphics, y dejaremos patente en algunos momentos sus posibilidades de análisis más complejos, como GLIM o GENSTAT, así como el desarrollo de nuevos análisis. R se distribuye de acuerdo a GNU GENERAL PUBLIC LICENSE.
R se puede conseguir gratuitamente en varias direcciones de internet, una de ellas, es http://www.r-project.org
En el sitio web: http://cran.es.project.org se encuentra todo el proyecto R. Este proyecto incluye las fuentes para construir R, lo que permite saber cómo está construido el programa, así como las direcciones donde se pueden conseguir las herramientas necesarias para hacerlo.
Para instalar R, en el sistema operativo Windows, elegir Dowload R for Windows. La instalación se encuentra en un ejecutable. Descargar el archivo de instalación y se muestra la siguiente pantalla
La instalación sólo realiza cambios mínimos en windows y copia los archivos necesarios en un directorio. Su desinstalación es sencilla y completa.
El directorio habitual donde realiza la instalación es C:/Archivos de programa. El programa crea en él un subdirectorio, R, y por cada versión un subdirectorio de este último donde copia todos los archivos, por ejemplo R-3.0.2. para la versión 3.0.2. En la instalación es conveniente seleccionar todas las opciones que se ofrecen, de tal modo que siempre se disponga de todas las ayudas posibles.
El programa de instalación puede crear en el directorio un acceso directo al programa, que se encuentra en el directorio de instalación, en bin/Rgui.s. También se encuentra allí otro programa, bin/Rterm.s, utilizado para ejecución asíncrona del programa.
Resumen: En el sitio web: http://www.r-project.org: Ir a “Download”, elegir país de descarga (España) y seleccionar la versión correspondiente a nuestro sistema operativo (Linus, Windows o Mac) y seguir las instrucciones de instalación.
Descripción e instalación de RStudio
RStudio es una interfaz que permite acceder de manera sencilla a toda la potencia de R. Para utilizar RStudio se requiere haber instalado R previamente. Al igual que R-project, RStudio es software libre.
El objetivo de los creadores de RStudio es desarrollar una herramienta potente que soporte los procedimientos y las técnicas requeridas para realizar análisis de calidad y dignos de confianza. Al mismo tiempo, pretenden que RStudio sea tan sencillo e intuitivo como sea posible para proporcionar un entorno amigable, tanto para los ya experimentados como para los nuevos usuarios
La instalación de RStudio se puede realizar desde la página oficial del programa http://www.rstudio.org
Pinchar en Download now y se muestra la siguiente pantalla
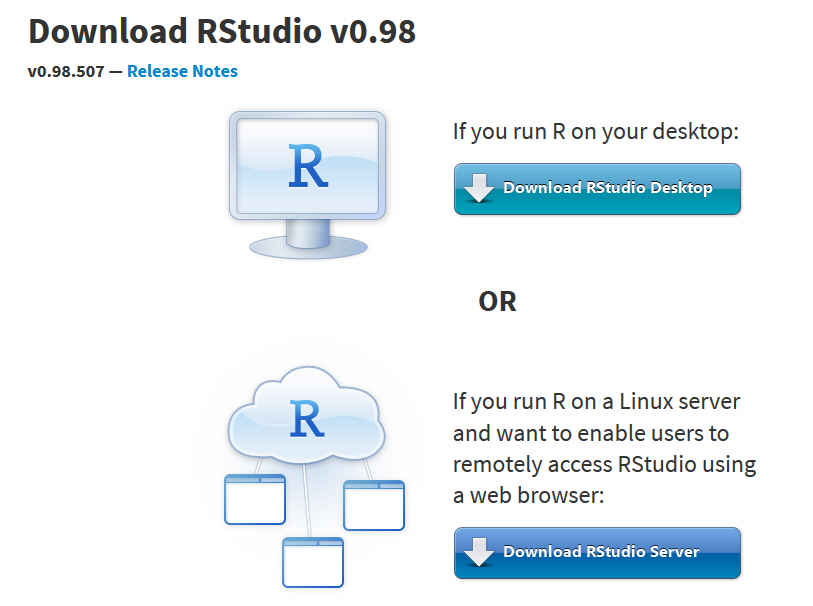
Seleccionar Download RStudio Desktop
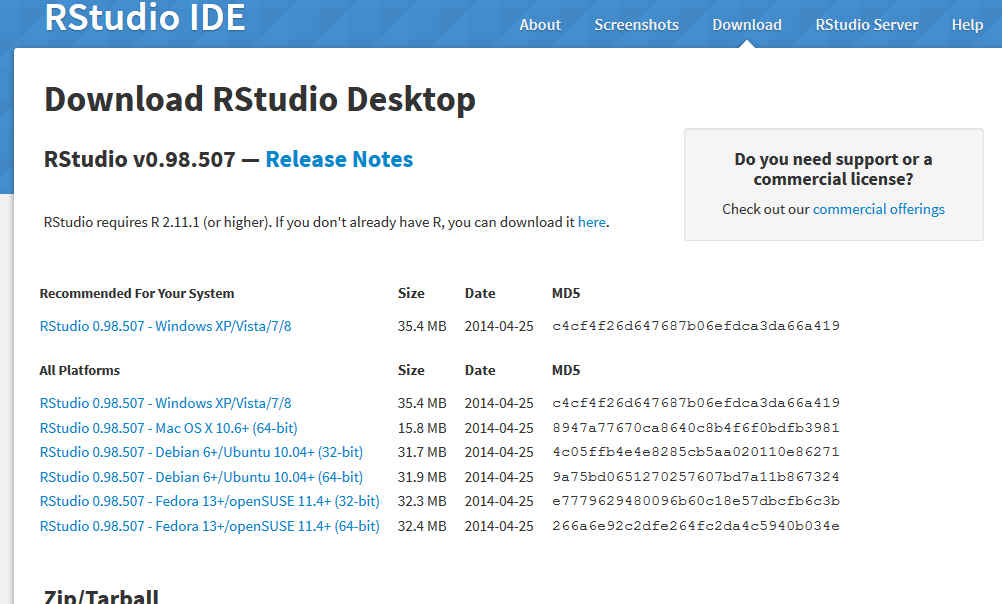
Elegir la versión correspondiente a nuestro sistema operativo (Linux, Windows o Mac)
y seguir las instrucciones de instalación.
Resumen: En el sitio web: http:// www.rstudio.org, seleccionar Download now y a continuación seleccionar Download RStudio Desktop, elegir la versión correspondiente a nuestro sistema operativo (Linus, Windows o Mac) y seguir las instrucciones de instalación.
Introducción a RStudio
Una vez instalados R y RStudio procedemos a ejecutar el programa RStudio desde cualquiera de los iconos que genera y se mostrará la siguiente pantalla
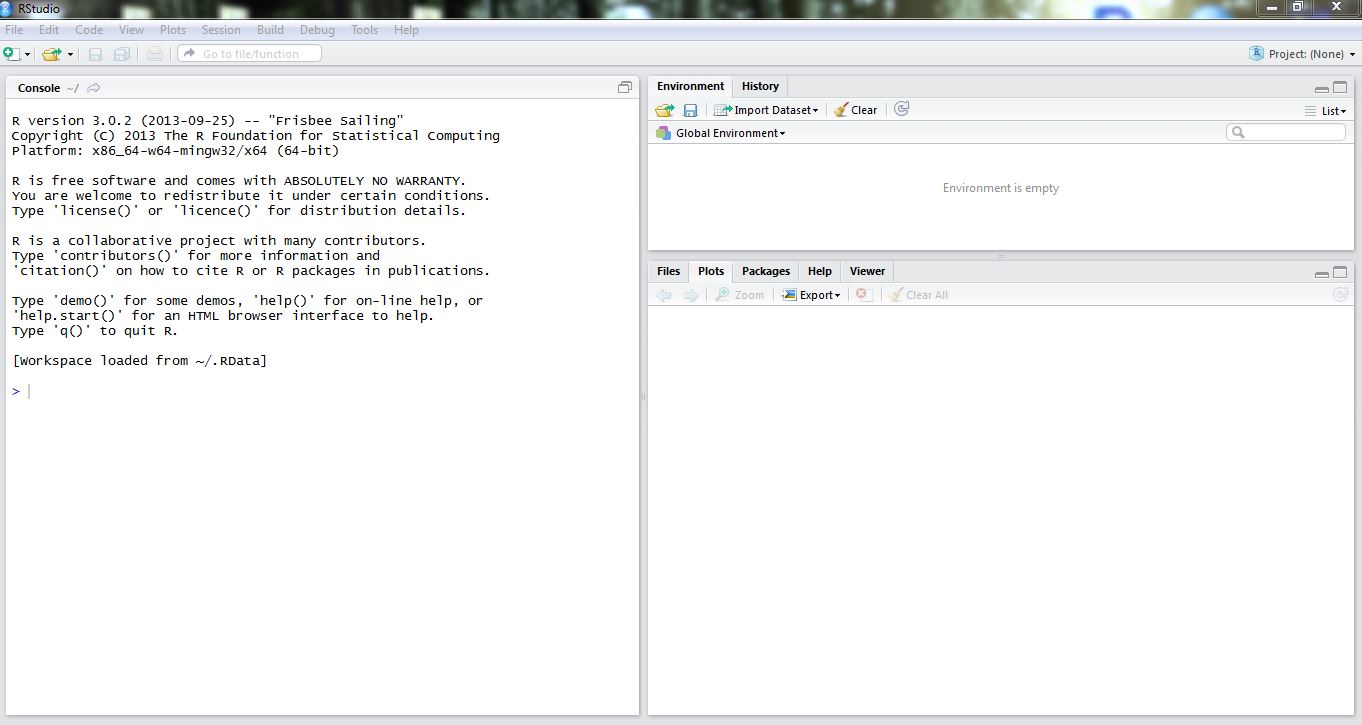
Esta pantalla está dividida en tres partes:
- La ventana de la izquierda donde está el prompt “>” , llamada Consola, es el espacio de trabajo
- La ventana de la derecha se divide en dos:
- En la ventana superior derecha se encuentra el historial de objetos almacenados en memoria. Desde esta ventana también podemos:
- Limpiar nuestro historial

- Importar datos

- Muestra los comandos y funciones implementadas de los informes con los que se han trabajado

- En la ventana inferior de la derecha RStudio muestra el directorio de trabajo, los gráficos que se van generando, paquetes para cargarlos e instalarlos directamente, ayuda y un visor HTML. Estas pestañas se irán describiendo a lo largo del documento.
Barra del menú principal: Opciones
Desde la barra del Menú principal se puede acceder a todos los menús de RStudio. Los primeros menús: Archivo, Edición, Ver y Ayuda son habituales en los programas bajo Windows. El resto de menús son específicos de RStudio estos permiten realizar cambios en los datos, obtener resultados estadísticos, numéricos, gráficos……A continuación se muestran los distintos menús desplegables, así como la finalidad de alguna de las opciones.

Cada uno de estos menús contiene distintas opciones que se muestran pulsando en cada una de ellos.
El menú FILE
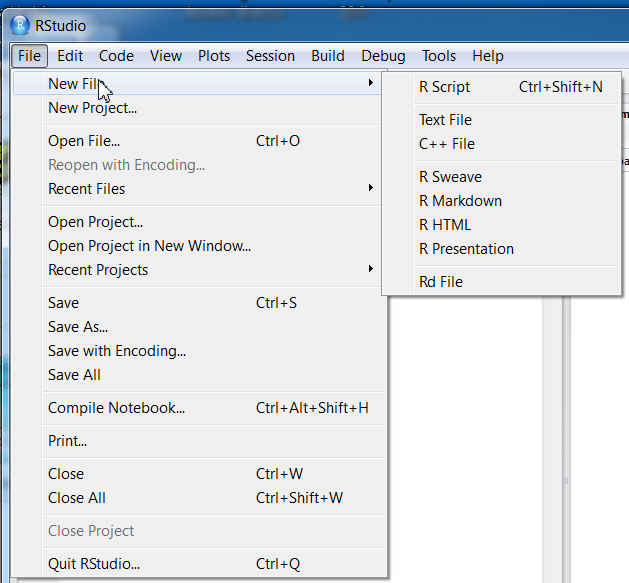
Este menú contiene las opciones más generales que suelen tener todos los programas como abrir un archivo, guardar, cerrar…
Unas de las principales características de RStudio es la flexibilidad para trabajar con diferentes archivos que podemos generar desde New file.
- New File->R Script: Permite abrir una nueva ventana en la interfaz de RStudio, la ventana de Edición. Aunque se puede desarrollar todo el trabajo en el espacio de trabajo, en la consola, esta no es la forma más eficiente de trabajar en RStudio. Es muy útil tener un entorno donde manipular (corregir, repetir, guardar, …) las entradas de código que solicitemos a R. Este entorno de trabajo es el Editor de R.
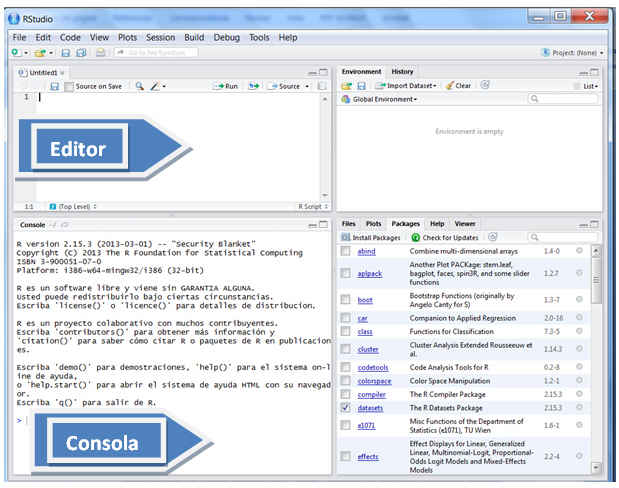
En la ventana de edición se escriben las instrucciones y para ejecutar estas instrucciones se pulsa (Ctrl+Intro); (Ctrl+r) o pinchando en el icono Run (en la parte superior derecha de la ventana de edición).
- New File->Text File: Permite abrir la ventana de texto, en los archivos tipo texto no se pueden ejecutar ninguna función a menos que se copien y se peguen en el espacio de trabajo.
- New File->C++ File: Permite compilar funciones de C++ en R.
- New File->R Sweave: Crea un archivo que permite trabajar con LaTeX.
- New File->R Markdown y New File->R HTML: Herramientas de RStudio para la creación de informes web. Markdown es un lenguaje simple de marcas diseñado para hacer que el contenido web sea fácil. En lugar de escribir el código HTML y CSS, Markdown permite el uso de una sintaxis mucho más cómoda (leer más).
- New File->R Presentation. Herramientas de RStudio para hacer presentaciones sencillas. El objetivo de las presentaciones es hacer diapositivas que hacen uso del código R y ecuaciones LaTeX lo más sencillo posible.
- New File->Rd File. Uno de los requisitos básicos para los paquetes de R es que todas las funciones exportadas, objetos y conjuntos de datos tienen la documentación completa. RStudio también incluye un amplio soporte para la edición de documentación de R, (Los archivos Rd utilizan un formato simple de marcas que se asemeja sintácticamente LaTeX).
- New Project: Permite crear proyectos que hacen que sea más fácil dividir el trabajo en múltiples contextos, cada uno con su propio directorio de trabajo, espacio de trabajo, historial y los documentos de origen. Los proyectos de RStudio están asociados a los directorios de trabajo.
Al crear un proyecto RStudio:
- Se crea un archivo de proyecto (con una extensión Rproj.) dentro del directorio del proyecto. Este archivo contiene diversas opciones de proyecto.
- Se crea un directorio oculto (nombrado Rproj.user) donde se almacenan los archivos específicos de un proyecto de carácter temporal (por ejemplo, los documentos originales guardados automáticamente, estado de la ventana, etc.). Este directorio también se agrega automáticamente a Rbuildignore, Gitignore, etc, si es necesario.
- Se carga el proyecto en RStudio y se muestra su nombre en la barra de herramientas de Proyectos.
Seleccionando File/New Project se muestra la siguiente ventana con las siguientes opciones:
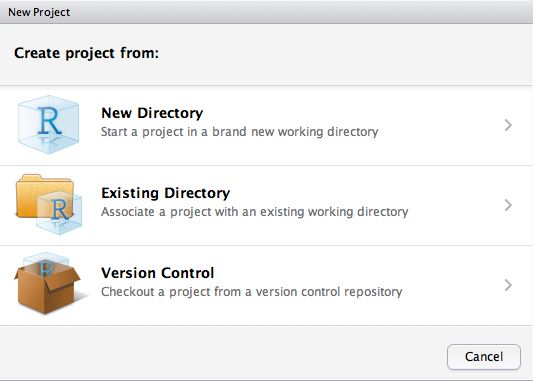
- Open Proyect…: Permite buscar y seleccionar un archivo de un proyecto existente.
- Open Project in New Window…: Permite trabajar con varios proyectos RStudio simultaneamente. También se puede hacer abriendo varios archivos de proyecto a través de la shell del sistema (es decir, doble clic en el archivo de proyecto).
- Recent Project: Permire seleccionar un proyecto de la lista de proyectos abiertos recientemente.
El menú EDIT
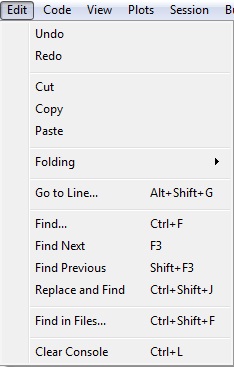
- Undo/Redo: Deshace/Rehace la última acción realizada/rechazada en la ventana del editor.
- Cut/Copy/Paste: Corta/ copia/pega cualquiere conjunto de texto de la ventana del editor.
- Folding: Permite mostrar y ocultar fácilmente los bloques de código para que sea más fácil navegar por el archivo del código fuente.
- Folding/Collapse: Permite duplicar una selección arbitraria de códigoLas regiones plegadas se conservan durante la edición de un documento, sin embargo cuando un archivo se cierra y se vuelve a abrir todas las regiones plegables son por defecto regiones no plegables.
- Go to line…: Permite ir rápidamente a una línea concreta del texto que se esté utilizando en la ventana del editor.
- Find…: Permie buscar alguna palabra o conjunto de palabras del texto que se esté utilizando en la ventana del editor.
- Find Next/Find Previous: Encuentra el siguiente/anterior conjunto de letras idéntico al buscado anteriormente en la misma ventana del editor.
- Replace and Find: Busca alguna palabra o conjunto de palabras del texto que se esté utilizando en la ventana del editor, y además reemplaza el conjunto de texto buscado por otro que elijamos.
- Find in Files…: Permite buscar de forma recursiva todos los archivos para cada ocurrencia de una cadena dada en un directorio específico.
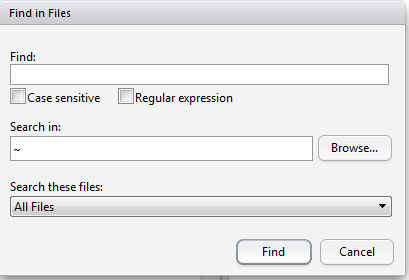
Se puede personalizar aún más la búsqueda con expresiones regulares y filtros para tipos de archivos específicos. El resultado de la búsqueda se mostrará en el panel junto a la consola (por defecto).
- Clear Console: Limpia por completo la consola, pero no borra los objetos que se hayan almacenado anteriormente en la memoria.
El menú CODE

En este menú están las opciones más directas con el espacio de trabajo.
- Back/Fordward: Rehacer/Deshacer una acción hecha en el script de trabajo.
- Insert Section…: Escribe un comentario en el script con el título de la sección (útil para ir directamente a una parte del trabajo).
- Jump To...: Permite ir directamente a una función creada anteriormente en el script de trabajo o ir a una sección.
- Go To File Function: Permite acceder rápidamente a cualquier archivo o función creada con RStudio.
- Go To Help: Muestra la ayuda del objeto donde esté situado el cursor.
- Go To Function Definition: Muestra la definición interna de la función que utiliza el programa para la ejecución de ésta.
- Extract Function: Permite crear funciones, para ello se tiene que seleccionar el texto que se quiere incluir en ésta.
- Reident Lines: Lleva el cursor al principio de la línea siguiente.
- Coment/Uncoment Lines: Permite transformar líneas de código en comentarios.
- Run Line(s): Ejecuta la línea donde está situado el cursor o un trozo de código que se seleccione.
- Re-Run Previous: Ejecuta de nuevo todo el código ejecutado por última vez.
- Run Region: Permite ejecutar una sección de código.
- Source: Almacena en la memoria los objetos definidos en la ventana de edición.
- Source with Echo: Ejecuta en la consola los objetos definidos en la ventana de edición.
- Source File: Almacena en la memoria los objetos definidos de cualquier archivo creado con RStudio aunque no estén abiertos.
El menú VIEW
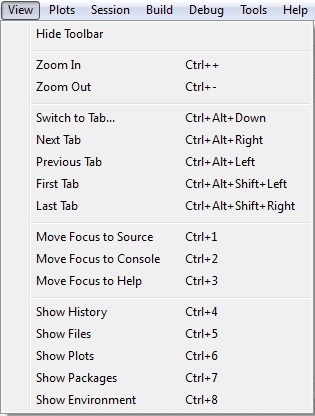
- Hide/Show Toolbar: Muestra/Oculta la barra de herramientas.
- Zoom In/Zoom Out: Realiza un zoom sobre cada una de las ventanas aumentando/disminuyendo el tamaño de su contenido.
- Switch To Tab: Permite cambiar de pestaña para visualizar cualquier hoja de edición.
- Next Tab/Previous Tab: Permite cambiar a la pestaña siguiente/anterior para visualizar la hoja de edición siguiente/anterior.
- First Tab/Last Tab: Permite cambiar a la primera/última pestaña para visualizar la primera/última hoja de edición.
- Move Focus To Source/Move Focus To Console: Mueve el cursor a la ventana de edición/consola de trabajo desde cualquier otra ventana.
- Move Focus To Help: Mueve el cursor a la pestaña de ayuda que por defecto se muestra en la ventana auxiliar número 2.
- Show History: Muestra todo el código que se ha ejecutado en la consola desde la última vez que se eliminó el historial. Por defecto el historial se muestra en la ventana auxiliar número 1.
- Show Files/Show Plots/ Show Packages: Muestra el conjunto de ficheros existentes en el directorio de trabajo/conjunto de gráficos que se han generado/conjunto de paquetes que el programa tiene instalados hasta el momento. Por defecto se muestra en la ventana auxiliar número 2.
- Show Environment: Muestra el conjunto de objetos que se han guardado en la memoria del programa. Por defecto se muestra en la ventana auxiliar número 1.
El menú PLOTS
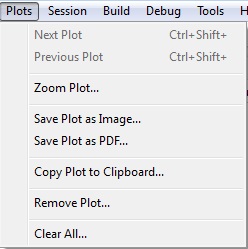
- Next Plot/ Previous Plot: Muestra el gráfico siguiente/anterior.
- Zoom Plot…: Abre una nueva ventana en la que se muestra el gráfico seleccionado.
- Save Plot as Image…/Save Plot as PDF…: Guarda el gráfico seleccionado como una imagen (.png, .jpg, .tiff, .bmp, .metafile, .svg, .eps)/en pdf
- Copy Plot to Clipboard: Copia el gráfico en un portapapeles.
- Remove Plo…t: Elimina el gráfico seleccionado
- Clear All…: Elimina todos los gráficos creados.
El menú SESSION
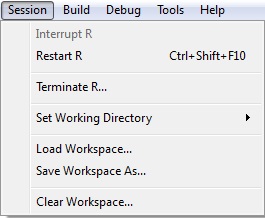
- Interrupt R: Permite interrumpir algún proceso interno que no queremos que finalice.
- Restart R: Permite actualizar la sesión en la que estemos trabajando.
- Terminate R: Permite eliminar toda la información creada en una sesión, pero sin eliminar lo escrito en la ventana de edición.
- Set Working Directory: Permite configurar el directorio de trabajo.
- Load Workspace/Save Workspace As/Clear Workspace: Permite cargar/guardar/eliminar un determinado espacio de trabajo. Por defecto los objetos contenidos en un espacio de trabajo se visualizan en la ventana auxiliar número 1.
El menú BUILD 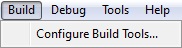
- Configure Build Tools: Permite construir paquetes y herramientas dentro de un proyecto creado por el usuario.
El menú DEBUG
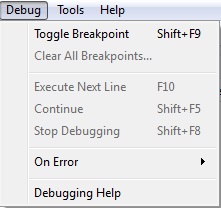
- Toggle Breakpoint: Permite introducir un punto de interrupción en el texto de la ventana de edición con la finalidad de averiguar si, hasta la línea donde se coloca dicho punto, la ejecución del texto es correcta.
- Clear All Breakpoints: Permite eliminar todos los puntos de interrupción que se hayan utilizado hasta el momento.
- Execute Next Line: Permite ejecutar texto colocado después de la línea donde se ha introducido un punto de interrupción.
- Continue: Permite continuar con la ejecución una vez que se ha detenido dicha ejecución en el punto de interrupción.
- Stop Debugging: Detiene la depuración.
- On Error: En caso de error, permite elegir entre que sólo salga un mensaje de aviso, que se inspeccione el error o que no ejecute más código a partir del error.
- Debugging Help: Muestra la página web del programa con la ayuda sobre la depuración de errores.
El menú TOOLS
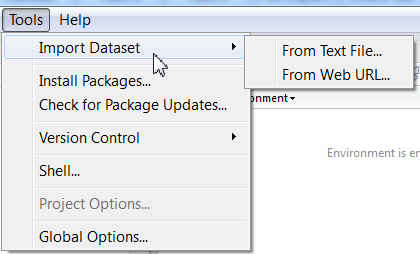
- Import Dataset: Importa un conjunto de datos desde un archivo .txt guardado en nuestro directorio (From Text File…) o desde cualquier página web (From Web URL…).
- Install Packages…: Permite instalar paquetes. Es importante que dentro de esta opción esté marcada la opción de Install dependencies.
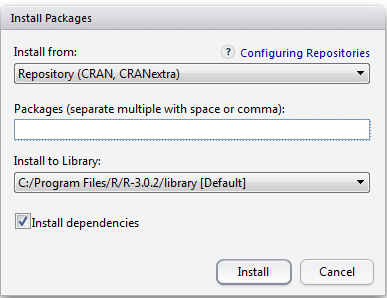
- Check for Packages Updates…: Permite actualizar los paquetes seleccionados.
- Version Control: Permite controlar varios proyectos a la vez, hacer copias de seguridad de los proyectos…
- Shell…: Es una interfaz para las operaciones más comunes de control de versiones.
- Global Options…: Muestra las opciones generales de RStudio
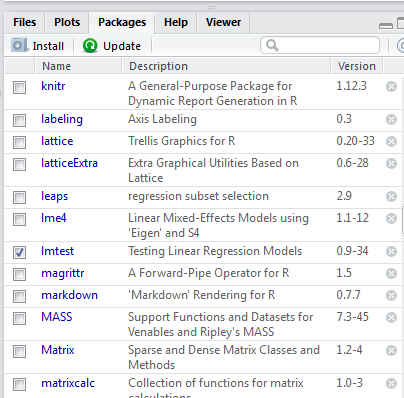
Nota: Una vez instalado el paquete hay que cargar dicho paquete, para ello desde el panel de paquetes simplemente se selecciona dicho paquete
El menú HELP
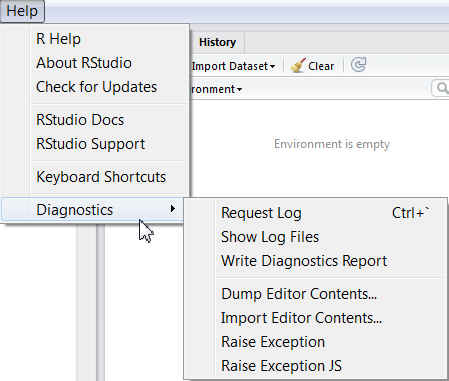
- R Help: Muestra la ayuda del programa. Por defecto se puede visualizar en la ventana auxiliar número 2.
- About RStudio: Muestra información sobre RStudio.
- Check For Updates: Permite realizar una búsqueda en la última versión con la finalidad de obtener la última actualización de dicho programa.
- RStudio Docs: Muestra la página web del programa en la que se explica la documentación con la que se puede trabajar en RStudio.
- RStudio Support: Muestra la página web del programa en la que hay un soporte de ayuda para cualquier duda sobre RStudio.
- Keyboard Shortcuts: Muestra la página web del programa, en la que se puede consultar todas los posibles métodos abreviados de teclado (combinaciones de teclas) para ejecutar los comandos en RStudio.
- Diagnostics: Permite realizar algunas opciones sobre diagnósticos del programa.
Conceptos de interés
- demo(): Abre una ventana con funciones de R para que se observe cómo se ejecutan y el resultado que devuelve
- help():Para una información más detallada utilizamos la función help() (ayuda). RStudio no necesita conectarse a la web para mostrar la ayuda, mientras que R sí.
- apropos(” “): Si no nos acordamos del nombre exacto de una función podemos usar la función apropos(” “) y entre paréntesis algunas letras de la función entre comillas.
- example(): Muestra un ejemplo práctico de una función.
> demo()

> help()
> apropos(“med”)
[1] “.__C__namedList” “.rs.emptyNamedList”
[3] “.rs.namedVectorAsList” “elNamed”
[5] “elNamed<-” “median”
[7] “median.default” “medpolish”
[9] “runmed”
> example(median)
> example(median)
median> median(1:4) # = 2.5 [even number]
[1] 2.5
median> median(c(1:3, 100, 1000)) # = 3 [odd, robust]
[1] 3
Estructura de datos fundamentales
-
Variables
La siguiente instrucción asigna el valor 25 a la variable años
> años=25
También se puede utilizar el símbolo “<-”
> años <- 25
Si el valor asignado es alfanumérico, se especifica entre comillas
> ciudad = “Granada”
> ciudad
[1] “Granada”
-
Vectores
El primer tipo de objeto que vamos a introducir es el vector.
* Se puede crear un vector utilizando la función c(), que concatena todos los elementos que recibe como argumentos.
>c(2,7,1,6)
[1] 2 7 1 6
>c(1:10)
[1] 1 2 3 4 5 6 7 8 9 10
>c(1:10,2,7,1,6,2:-5)
[1] 1 2 3 4 5 6 7 8 9 10 2 7 1 6 2 1 0 -1 -2 -3 -4 -5
>c()
NULL
En el último caso, el resultado es el objeto NULL.
En el caso de vectores alfanuméricos, los elementos van entrecomillados
>nombre.mes=c(“Enero”,”Febrero”,”Marzo”,”Abril”,”Mayo”,”Junio”,”Julio”,”Agosto”,”Septiembre”,”Octubre”,”Noviembre”,”Diciembre”)
>nombre.mes
[1] “Enero” “Febrero” “Marzo” “Abril”
[5] “Mayo” “Junio” “Julio” “Agosto”
[9] “Septiembre” “Octubre” “Noviembre” “Diciembre”
>c(“Hola”, “Uno”, “Dos”)
[1] “Hola” “Uno” “Dos”
Un vector está formado por elementos del mismo tipo. Si se mezclan números y cadenas de caracteres, se obtendrá un vector alfanumérico. Si se mezclan números reales y complejos, se obtendrá un vector de números complejos.
* Para acceder a los elementos de unvector se utilizan los corchetes
> nombre.mes[3]
[1] “Marzo”
> nombre.mes[6]
[1] “Junio”
> nombre.mes[2:6]
[1] “Febrero” “Marzo” “Abril” “Mayo” “Junio”
> nombre.mes[c(1, 4, 6, 8)]
[1] “Enero” “Abril” “Junio” “Agosto”
* El símbolo de dos puntos, situado entre dos números, construye un vector de modo sencillo, tanto en orden ascendente como descendente.
>1:10
[1] 1 2 3 4 5 6 7 8 9 10
>1:3.5
[1] 1 2 3
>1.9:3.5
[1] 1.9 2.9
El vector comienza en el primer número suministrado y finaliza en el segundo o en un número anterior sin sobrepasarlo, tanto en orden ascendente como descendente.
♦ Algunas funciones de utilidad sobre los vectores
* Names()
Mediante la función names() podemos asignar nombre a los elementos de un vector. De hecho, esta función permite dar nombre a los elementos de cualquier objeto. Aplicada a un vector se hace de la siguiente forma:
> x<-1:5
>x
[1] 1 2 3 4 5
>names(x)<-c(“I”,”II”,”III”,”IV”,”V”)
>x
I II III IV V
* Seq()
La función seq() permite construir vectores que son sucesiones equiespaciadas, esta función posee los siguientes argumentos:
- from Valor inicial de la sucesión
- to Valor final de la sucesión
- by Espaciado entre los elementos
- length Longitud del valor resultante
- along Un objeto cuya longitud se usará para el objeto a construir.
Si no se indica algún argumento, por defecto vale 1
> seq(1, 100, length = 5)
[1] 1.00 25.75 50.50 75.25 100.00
> x <- c (1: 7)
> x [seq (1, 7, by = 2)]
[1] 1 3 5 7
* Mode()
La función mode() devuelve o modifica el tipo de un objeto.
> x = 1:5
>mode(x)
[1] “numeric”
♦ Operaciones básicas con vectores
Las operaciones básicas que podemos realizar con vectores las podemos resumir en la siguiente tabla.
 Esta tabla se puede visualizar ejecutando la función demo(plotmath)
Esta tabla se puede visualizar ejecutando la función demo(plotmath)
> demo(plotmath)
-
Factor
La función “factor” crea un vector de variables cualitativas, donde el atributo levels indica los valores numéricos posibles.Un factor corresponde a una variable nominal u ordinal, dividida en categorías, y que se utiliza, por ejemplo, para dividir una población en grupos. Esta función será de vital importancia en las próximas prácticas.
factor (x, levels =, labels =, exclude = , ordered = )
Siendo sus argumentos los siguientes:
- x son los datos a partir de los cuales se genera el factor
- levels es un vector de niveles opcional. Los valores de x que no correspondan a uno de los indicados se sustituyen por NA. El valor predeterminado de este parámetro es la lista ordenada de valores distintos de x
- labels es un vector de valores que se utiliza como etiqueta de los niveles. El valor predeterminadoes as.character(levels)
- exclude es un vector de valores que deben excluirse de la formación de niveles y sustituirse por NA
- ordered es un valor lógico que indica si lo es el factor.
> sexo <- c (“Hombre”, “Mujer”, “Mujer”,”Hombre”, “Hombre” ,”Mujer”, “Hombre”)
> nombre <-c (“Pedro”, “Alicia”, “Ana”, “Manolo”, “Germán”, “María”, “Juan”)
> sexo <- factor (sexo)
> sexo
[1] Hombre Mujer Mujer Hombre Hombre Mujer Hombre
Levels: Hombre Mujer
-
Matrices
En R hay varias formas de crear una matriz:
♦ Mediante la función matrix(), cuyos parámetros son:
♦ data Vector que contiene los valores que formarán la matriz. Debe tener en cuenta que si no es suficientemente grande, se repetirá las veces que sea necesario
♦ nrow Número de filas.Si no especifica, se toma nrow =1
♦ ncol Número de columnas
♦ byrow Variable lógica que indica si la matriz debe construirse por filas o por columnas. El valor predeterminado es F
♦ dimnames Lista de longitud 2 con los nombres de las filas y las columnas.
♦ Mediante los operadores rbind() (para pegar vectores por filas) y cbind() (para pegar vectores por columnas)
matriz = rbind (x1, x2,…)
matriz = cbind (x1, x2…)
donde en la función rbind(), x1 y x2, son las filas de la matriz, y en la función cbind() las columnas.
> M = matrix( 1: 9, nrow = 3, byrow = TRUE) # la matriz se rrellena por filas
> M
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
[3,] 7 8 9
> N = matrix( 1: 9, nrow = 3, byrow = FALSE) # la matriz se rrellena por columnas
> N
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
> matrix(1:10, 5, 2, dimnames = list (c (“fila1”, “fila2”, “fila3”, “fila4”, “fila5”), c(“columna1”, “columna2”)))
columna1 columna2
fila1 1 6
fila2 2 7
fila3 3 8
fila4 4 9
fila5 5 10
> matrix(1:15, 3, 5)
[,1] [,2] [,3] [,4] [,5]
[1,] 1 4 7 10 13
[2,] 2 5 8 11 14
[3,] 3 6 9 12 15
Nota: Cuando la longitud del vector no coincide con el número de filas y columnas, los elementos de la matriz se repiten, por lo que R te da un warning advirtiendo que las salidas pueden no ser las deseadas.
> matrix( 1:15, 4, 6)
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 5 9 13 2 6
[2,] 2 6 10 14 3 7
[3,] 3 7 11 15 4 8
[4,] 4 8 12 1 5 9
Warning message
In matrix(1:15, 4, 6) :
data length [15] is not a sub-multiple or multiple of the number of rows [4]
También podemos utilizar las funciones cbind y rbind para construir matrices:
> v1 = c(1,2,3,4)
> v2 = c(5,6,7,8)
> v3= c(9,10,11,12)
> FA = rbind(v1,v2,v3)
> FA
[,1] [,2] [,3] [,4]
v1 1 2 3 4
v2 5 6 7 8
v3 9 10 11 12
>QA = cbind (v1, v2, v3)
> QA
v1 v2 v3
[1,] 1 5 9
[2,] 2 6 10
[3,] 3 7 11
[4,] 4 8 12
> matriz= rbind (c(1,2,3), c(4,5,6), c(7,8,9))
> matriz
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
[3,] 7 8 9
> matriz = cbind (c(1,2,3), c(4,5,6), c(7,8,9))
>matriz
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
◊ Seleccionar los ementos de una matriz
- Seleccionar el término que ocupa la posición primera fila, segunda columna, [1, 2] de la matriz N:
La matriz N es la siguiente
> N
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
> N[1, 2]
[1] 4
- Para seleccionar sólo una fila (columna), dejamos en blanco la posición de la columna (fila)
Por ejemplo: Seleccionar
La segunda fila de la matriz N
> N[2, ]
[1] 2 5 8
La tercera columna de la matriz N
> N[ , 3 ]
[1] 7 8 9
- Seleccionar la segunda y tercera fila
> N[2:3, ]
[,1] [,2] [,3]
[1,] 2 5 8
[2,] 3 6 9
- Seleccionar la segunda y tercera fila de las dos primeras columnas
> N[2:3, 1:2]
[,1] [,2]
[1,] 2 5
[2,] 3 6
Ejemplos
Construir una matriz de 14×3 donde los nombres de las columnas son las variables peso, altura y edad
> datos= c (77, 58, 89, 55,47,60,54,58,75,65,82,85,75,65,1.63,1.63,1.85,1.62,1.60,1.63,1.70,1.65,1.78,1.70,1.77,1.83,1.74,1.65,23,23,26,23,26,26,22,23,26,24,28,42,25,26)
> matriz = matrix(datos, 14, 3, dimnames = list(c(), c(“Peso”,”Altura”,”Edad”)))
>matriz
Peso Altura Edad
[1,] 77 1.63 23
[2,] 58 1.63 23
[3,] 89 1.85 26
[4,] 55 1.62 23
[5,] 47 1.60 26
[6,] 60 1.63 26
[7,] 54 1.70 22
[8,] 58 1.65 23
[9,] 75 1.78 26
[10,] 65 1.70 24
[11,] 82 1.77 28
[12,] 85 1.83 42
[13,] 75 1.74 25
[14,] 65 1.65 26
- Seleccionar la primera columna
> matriz[ ,1]
[1] 77 58 89 55 47 60 54 58 75 65 82 85 75 65
También
> matriz [ ,”Peso”]
[1] 77 58 89 55 47 60 54 58 75 65 82 85 75 65
- Seleccionar un elemento
> matriz[4 , 2]
Altura
1.62
- Seleccionar una fila
> matriz[9, ]
Peso Altura Edad
75.00 1.78 26.00
- Añadir a la matriz la variable sexo.
>sexo<-factor(c(“H”,”M”,”H”,”H”,”M”,”M”,”H”,”M”,”M”,”H”,”H”,”H”,”M”,”M”))
>sexo
[1] H M H H M M H M M H H H M M
Levels: H M
>matriz<-c(matriz,sexo)
>matriz
[1] 77.00 58.00 89.00 55.00 47.00 60.00 54.00 58.00 75.00 65.00 82.00 85.00 75.00 65.00 1.63 1.63 1.85 1.62 1.60
[20] 1.63 1.70 1.65 1.78 1.70 1.77 1.83 1.74 1.65 23.00 23.00 26.00 23.00 26.00 26.00 22.00 23.00 26.00 24.00
[39] 28.00 42.00 25.00 26.00 1.00 2.00 1.00 1.00 2.00 2.00 1.00 2.00 2.00 1.00 1.00 1.00 2.00 2.00
>matriz<-matrix(matriz,14,4,dimnames=list(c(),c(“Peso”,”Altura”,”Edad”,”Sexo”)))
>matriz
Peso Altura Edad Sexo
[1,] 77 1.63 23 1
[2,] 58 1.63 23 2
[3,] 89 1.85 26 1
[4,] 55 1.62 23 1
[5,] 47 1.60 26 2
[6,] 60 1.63 26 2
[7,] 54 1.70 22 1
[8,] 58 1.65 23 2
[9,] 75 1.78 26 2
[10,] 65 1.70 24 1
[11,] 82 1.77 28 1
[12,] 85 1.83 42 1
[13,] 75 1.74 25 2
[14,] 65 1.65 26 2
-
Hoja de datos
La adaptación de la matriz de datos al uso habitual en Estadística es el objeto data.frame().
- La diferencia fundamental con la matrix() de datos es que data.frame() no tiene por qué estar compuesto de elementos del mismo tipo. Los objetos pueden ser vectores, factores, matrices, listas e incluso hojas de datos.
- Las matrices, listas y hojas de datos, contribuyen con tantas variables como columnas tengan.
- Los vectores numéricos y los factores se incluyen directamente y los vectores no numéricos se fuerzan como factores.
- Para referirnos a cualquier elemento de la hoja de datos utilizaremos dos índices, de modo similar a una matriz.
En el ejemplo anterior, al añadirle a la matrix() la variable sexo, la transforma en tipo numérico asignándole el valor 1 para hombre 2 para mujeres.
>mode(matriz)
[1] “numeric”
Vamos a transformar la matriz en un data.frame().
>dataframe<-data.frame(matriz)
>dataframe
Peso Altura Edad Sexo
1 77 1.63 23 1
2 58 1.63 23 2
3 89 1.85 26 1
4 55 1.62 23 1
5 47 1.60 26 2
6 60 1.63 26 2
7 54 1.70 22 1
8 58 1.65 23 2
9 75 1.78 26 2
10 65 1.70 24 1
11 82 1.77 28 1
12 85 1.83 42 1
13 75 1.74 25 2
14 65 1.65 26 2
De esta forma, hemos convertido la matriz de tipo numérico en un conjunto de datos con 4 variables y cada una con 14 observaciones.
Para añadir una variable de tipo carácter, como por ejemplo los nombres de los individuos, en el data.frame, se puede hacer de la siguiente forma:
> Nombres = c (“Pepe”,”Ana”,”Manolo”,”Rafa”,”María”,”Auxi”,”Germán”,”Celia”,”Carmen”,”Juan”,”Dani”,”Antonio”,”Belinda”,”Sara”)
>Nombres
[1] “Pepe” “Ana” “Manolo” “Rafa” “María” “Auxi” “Germán” “Celia” “Carmen”
[10] “Juan” “Dani” “Antonio” “Belinda” “Sara”
> dataframe1 <- data.frame(dataframe, Nombres)
> dataframe1
Peso Altura Edad Sexo Nombres
1 77 1.63 23 1 Pepe
2 58 1.63 23 2 Ana
3 89 1.85 26 1 Manolo
4 55 1.62 23 1 Rafa
5 47 1.60 26 2 María
6 60 1.63 26 2 Auxi
7 54 1.70 22 1 Germán
8 58 1.65 23 2 Celia
9 75 1.78 26 2 Carmen
10 65 1.70 24 1 Juan
11 82 1.77 28 1 Dani
12 85 1.83 42 1 Antonio
13 75 1.74 25 2 Belinda
14 65 1.65 26 2 Sara
-
Listas
Una lista es un objeto formado por objetos de varias clases. Una colección de elementos que pueden ser de distintos tipos y que generalmente están identificados por un nombre. Para crear una lista se utiliza la función list()
> milista = list(números = 1:5, A = matrix(1:6, nrow =3), B = matrix(1:8, ncol = 2), ciudades = c(“Sevilla”, “Granada”, “Málaga”))
> milista
$números
[1] 1 2 3 4 5
$A
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
$B
[,1] [,2]
[1,] 1 5
[2,] 2 6
[3,] 3 7
[4,] 4 8
$ciudades
[1] “Sevilla” “Granada” “Málaga”
◊ Seleccionar elementos de una lista
Se puede acceder a los elementos de una lista de varias formas:
> milista$números
[1] 1 2 3 4 5
> milista[[“números”]]
[1] 1 2 3 4 5
> milista[[1]]
[1] 1 2 3 4 5
> milista[c(1,3,4)] # Acceder a una sublista NombreDeLaLista[c(Posicion1, Posicion2, …)]
$números
[1] 1 2 3 4 5
$B
[,1] [,2]
[1,] 1 5
[2,] 2 6
[3,] 3 7
[4,] 4 8
$ciudades
[1] “Sevilla” “Granada” “Málaga”
> milista[c(-1,-3,-4)] # Índices negativos que indican los elementos que no se obtienen. NombreDeLaLista[c(-Posicion1, -Posicion2,…)]
$A
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
Ejemplo
Dada la siguiente lista
> ejem.lista = list(nom.alumno1=”Manolo”, nom.alumno2=”German”, nom.profesora=”Ana”, ProyectoInnovacionDocente=TRUE, NumeroDeAlumnos = 2, EdadAlumnos = c(21, 23))
>ejem.lista
$nom.alumno1
[1] “Manolo”
$nom.alumno2
[1] “German”
$nom.profesora
[1] “Ana”
$ProyectoInnovacionDocente
[1] TRUE
$NumeroDeAlumnos
[1] 2
$EdadAlumnos
[1] 21 23
Obtener elementos de la lista utilizando diferentes procedimientos
a) Utilizando el operador $ de la siguiente forma
> ejem.lista$nom.alumno1
[1] “Manolo”
> ejem.lista$nom.alumno2
[1] “German”
>ejem.lista$nom.profesora
[1] “Ana”
>ejem.lista$EdadAlumnos
[1] 21 23
b) Indicando entre dobles corchetes la posición del elemento. NombreDeLaLista[[PosiciónDelElemento]]
> ejem.lista[[2]]
[1] “German”
>ejem.lista[[4]]
[1] TRUE
c) Indicando entre dobles corchetes y comillas el nombre del elemento. NombreDeLaLista[[“Nombre”]]
> ejem.lista[[“nom.profesora”]]
[1] “Ana”
>ejem.lista[c(1,2,4,5)] # Acceder a una sublista NombreDeLaLista[c(Posicion1, Posicion2, …)]
$nom.alumno1
[1] “Manolo”
$nom.alumno2
[1] “German”
$ProyectoInnovacionDocente
[1] TRUE
$NumeroDeAlumnos
[1] 2
Por último podemos poner índices negativos para no obtener elementos no deseados. NombreDeLaLista[c(-Posicion1, -Posicion2,…)]
>ejem.lista[c(-4,-5)] # Índices negativos que indican los elementos que no se obtienen. NombreDeLaLista[c(-Posicion1, -Posicion2,…)]
$nom.alumno1
[1] “Manolo”
$nom.alumno2
[1] “German”
$nom.profesora
[1] “Ana”
$EdadAlumnos
[1] 21 23
Para describir un conjunto de datos la estructura que se debe utilizar es la lista, mientras que para devolver datos desde una función se debe utilizar la hoja de datos. Ya que esta última permite devolver datos de varios tipos y, además, de modo estructurado, lo que facilita utilizar el resultado de una función como entrada de otra.
◊ Seleccionar variables según un condicional, de forma aleatoria, según un rango o según una variable filtro
Mediante la fucnción subset() se selecciona subconjunto en vectores y en una hoja de datos
La sintaxis en vectores es: subset(x, subset, …)
La sintaxis en hojas de datos es: subset(x, subset,select, drop = FALSE, …)
donde los argumentos son:
- x El objeto al que se aplica la selección
- subset La condición que se aplica para seleccionar un subconjunto
- select Columnas que se desea conservar en una hoja de datos
- drop Este argumento se pasa al método de indexación de hojas de datos.
Recordemos los datos del ejemplo
> datos= c (77, 58, 89, 55,47,60,54,58,75,65,82,85,75,65,1.63,1.63,1.85,1.62,1.60,1.63,1.70,1.65,1.78,1.70,1.77,1.83,1.74,1.65,23,23,26,23,26,26,22,23,26,24,28,42,25,26)
> matriz = matrix(datos, 14, 3, dimnames = list(c(), c(“Peso”,”Altura”,”Edad”)))
>Sexo<-factor(c(“H”,”M”,”H”,”H”,”M”,”M”,”H”,”M”,”M”,”H”,”H”,”H”,”M”,”M”))
> matriz<-c(matriz,Sexo)
> matriz <- matrix(matriz,14,4,dimnames=list(c(),c(“Peso”,”Altura”,”Edad”,”Sexo”)))
> dataframe<-data.frame(matriz)
> Nombres = c (“Pepe”,”Ana”,”Manolo”,”Rafa”,”María”,”Auxi”,”Germán”,”Celia”,”Carmen”,”Juan”,”Dani”,”Antonio”,”Belinda”,”Sara”)
> dataframe1 <- data.frame(dataframe, Nombres)
♦ Seleccionar variables
> subset(dataframe1,select=c(Sexo,Nombres))
Sexo Nombres
1 1 Pepe
2 2 Ana
3 1 Manolo
4 1 Rafa
5 2 María
6 2 Auxi
7 1 Germán
8 2 Celia
9 2 Carmen
10 1 Juan
11 1 Dani
12 1 Antonio
13 2 Belinda
14 2 Sara
> subset(dataframe1, select = c(Peso,Altura))
Peso Altura
[1,] 77 1.63
[2,] 58 1.63
[3,] 89 1.85
[4,] 55 1.62
[5,] 47 1.60
[6,] 60 1.63
[7,] 54 1.70
[8,] 58 1.65
[9,] 75 1.78
[10,] 65 1.70
[11,] 82 1.77
[12,] 85 1.83
[13,] 75 1.74
[14,] 65 1.65
♦ Seleccionar un subconjunto de variable
> subset(dataframe1, Altura > 1.70)
Peso Altura Edad Sexo
3 89 1.85 26 1 Manolo
9 75 1.78 26 2 Carmen
11 82 1.77 28 1 Dani
12 85 1.83 42 1 Antonio
13 75 1.74 25 2 Belinda
>subset(dataframe1, Altura > 1.71 & Peso > 60)
Peso Altura Edad Sexo Nombres
3 89 1.85 26 1 Manolo
9 75 1.78 26 2 Carmen
11 82 1.77 28 1 Dani
12 85 1.83 42 1 Antonio
13 75 1.74 25 2 Belinda
>subset(dataframe1, Altura > 1.71 & Peso> 60 & Sexo==”1″)
Peso Altura Edad Sexo Nombres
3 89 1.85 26 1 Manolo
11 82 1.77 28 1 Dani
12 85 1.83 42 1 Antonio
>subset(dataframe1, Altura>1.71 & Peso>60 & Sexo==”1″,select=Nombres)
Nombres
3 Manolo
11 Dani
12 Antonio
>subset(dataframe1, Altura>1.71 & Peso >60 & Sexo==”1″, select=c(Edad,Nombres))
Edad Nombres
3 26 Manolo
11 28 Dani
12 42 Antonio
♦ Seleccionar variables usando una variable auxiliar filtro.
> filtro = dataframe1[,”Altura”] < 1.80
> filtro
[1] TRUE TRUE FALSE TRUE TRUETRUETRUETRUETRUETRUETRUE FALSE TRUE TRUE
>dataframe1[filtro,”Altura”] = NA
>dataframe1
Peso Altura Edad Sexo Nombres
1 77 NA 23 1 Pepe
2 58 NA 23 2 Ana
3 89 1.85 26 1 Manolo
4 55 NA 23 1 Rafa
5 47 NA 26 2 María
6 60 NA 26 2 Auxi
7 54 NA 22 1 Germán
8 58 NA 23 2 Celia
9 75 NA 26 2 Carmen
10 65 NA 24 1 Juan
11 82 NA 28 1 Dani
12 85 1.83 42 1 Antonio
13 75 NA 25 2 Belinda
14 65 NA 26 2 Sara
Comparamos con el comando anterior (subset) para ver que los resultados coinciden.
>subset(dataframe1, Altura>1.80)
Peso Altura Edad Sexo Nombres
3 89 1.85 26 1 Manolo
12 85 1.83 42 1 Antonio
◊ Creción de variables a partir de otras existentes
>transform(dataframe1,logPeso=log(Peso))
Peso Altura Edad Sexo Nombres logPeso
1 77 1.63 23 1 Pepe 4.343805
2 58 1.63 23 2 Ana 4.060443
3 89 1.85 26 1 Manolo 4.488636
4 55 1.62 23 1 Rafa 4.007333
5 47 1.60 26 2 María 3.850148
6 60 1.63 26 2 Auxi 4.094345
7 54 1.70 22 1 Germán 3.988984
8 58 1.65 23 2 Celia 4.060443
9 75 1.78 26 2 Carmen 4.317488
10 65 1.70 24 1 Juan 4.174387
11 82 1.77 28 1 Dani 4.406719
12 85 1.83 42 1 Antonio 4.442651
13 75 1.74 25 2 Belinda 4.317488
14 65 1.65 26 2 Sara 4.174387
Nota: Ver también Estructura de datos con R en la Práctica 1 de la Guía R
Lectura de datos desde ficheros externos
♦ readtable()
Para leer un fichero .txt en R se emplea la función read.table
read.table (file, header, sep, quote, dec , row.names, col.names, as.is, na.strings, skip)
- file: Nombre del archivo a leer, que debe tener una línea por individuo
- header: Es un valor lógico. Si es TRUE, la primera línea del archivo contiene los nombres de las variables. Es conveniente especificar este campo explícitamente
- sep: Separador entre campos. El valor predeterminado es uno o varios espacios en blanco
- dec: Separador decimal
- quote: Conjunto de caracteres que delimitan cadenas de caracteres
- row.names: Especifica los nombres para las filas. Se puede especificar de dos formas: Con un vector de cadenas de caracteres de la misma longitud que el número de filas o mediante un nombre o número que indica un campo del archivo que contiene los nombres.Si se deja en blanco, los nombres dependen de la existencia o no de un campo de caracteres con valores distintos. Si lo hay, los utiliza como nombres, en caso contrario utiliza como nombres los números de orden de cada fila. Esta última opción puede forzarse dando a este parámetro el valor NULL.
- col.names: Especifica los nombres para las columnas o variables. Si no los indica aquí, ni están incluidos en la primera fila del archivo, se construyen con la letra V y el número de columna.
- as.is:Vector de valores lógicos que indica cómo tratar los campos no numéricos. El valor predeterminado es FALSE con el cual dichos campos se transforman en factores, salvo que se utilicen como nombres de filas. Si este vector es de longitud inferior al número de campos no numéricos se repetirá las veces necesarias. También puede ser un vector numérico que indica que columnas deben conservarse como caracteres.
- na.strings: Vector de caracteres y controla con qué valor se indica un valor NA. Así, podrá utilizar * para leer este tipo de datos procedentes de BMDP.
- colClasses: Vector de caracteres que indica la clase de cada columna.
- nrows:Número máximo de filas que se leerán.
- skip:Indica el número de líneas del principio del archivo que deben saltarse sin leer.
- check.names: De tipo lógico, si es TRUE se comprueba que los nombres de variables son correctos y que no hay duplicados.
- fill: De tipo lógico, si es TRUE se completan las filas con blancos si es necesario.
- strip.white: De tipo lógico, si es TRUE y se ha definido un separador, se eliminan los espacios.
- blank.lines.skip: De tipo lógico, si es TRUE se ignoran las líneas en blanco.
- comment.char:Indica un carácter a partir del cual no se lee la línea, interpretándose comoun comentario.
♦ write()
La función write permite escribir un vector o una matriz en un archivo. La matriz debe ser traspuesta para que coincida con la representación internade R.
write(x, file, ncolumns, append)
- x: Objeto (vector o matriz)
- file: Nombre del archivo
- ncolumns:Número de columnas
- append:Valor lógico que indica si los datos deben añadirse a los existentes en el archivo.
♦ Paquete “foreign”
Este paquete permite leer y escribir archivos existentes de otros formatosde EpiInfo, Minitab, S, SAS, SPSS, Stata, Systat y Weka. Algunas funciones que permite hacer con esta librería son:
◊ read.spss
Exporta una hoja de datos en formato .sav para poder abrirlo y trabajar con él en SPSS. Sus argumentos son:
read.spss(file, use.value.labels = TRUE, to.data.frame = FALSE, max.value.labels = Inf, trim.factor.names = FALSE, trim_values = TRUE, reencode = NA, use.missings = to.data.frame)
- file: Cadena de caracteres, el nombre del archivo o la dirección donde está guardado
- use.value.labels: Convierte variables con etiquetas de valor a factores con esos niveles
- to.data.frame: Devuelve una hoja de datos
- max.value.label: Si value.labels = TRUE, entonces convierte en factores las variables con etiquetas de valor, utilizando
- trim.factor.names: Valor lógico, recorta los espacios finales de los niveles de factor
- reencode: valor lógico, cadenas de caracteres se vuelven a codificar a la localización actual.
Otras funciones de este paquete son read.dbf, read.dta, read.octave, write.dbf, write.dta, ect. Para más información de este paquete consultar http://cran.r-project.org/web/packages/foreign/foreign.pdf
Nota: Ver también Lectura de datos desde ficheros externos con R en la Práctica 1 de la Guía R
Funciones en RStudio
Las funciones permiten realizar las diferentes acciones. Existen muchas funciones ya definidas, algunas incluso pueden ser modificadas, pero una de las capacidades más interesante es la posibilidad de crear nuevas funciones que realicen tareas que no estaban definidas en el momento de instalar el programa.Estas nuevas funciones se incorporan al lenguaje y, desde ese momento, se utilizan como las previamente existentes.
Una función se define asignando a un objeto la palabra function seguida de los argumentos, escritos entre paréntesis y separados por comas y seguida de la orden, entre llaves si son varias órdenes, que se quiera asignar.
♦ Elementos de una función
NombreFuncion = funtion (argumentos función) {órdenes de la función return(Valor que ha de devolver la función) }
- NombreFuncion: Nombre que le daremos a la función
- Argumentos función: Parámetros que debe de tener la función
- órdenes de la función: Las líneas de órdenes que van a llevar a cabo que la función dé el resultado deseado. Pueden ser condicionales, operadores lógicos, bucles, ect.
- return( ): Es el valor que devuelve la función. Normalmente suele ser una lista.
Operadores de relación
- ! : Indica la negación
- &: Indica la conjunción
- | : Indica la disyunción
- <,>, <= , >= , == son respectivamente los símbolos de menor, mayor, menor o igual, mayor o igual, e igual.
Condicionales
if (condición) acción1 [else acción2]
Esta estructura es escalar, ya que si la condición está formada por más de un elemento, sólo considera el primero. En R y RStudio la función para los condicionales es
ifelse(parámetro1, parámetro2, parámetro3)
- parámetro1 es la condición que se quiere avaluar
- parámetro2 es la acción que se quiere hacer en el caso de que se cumpla la condición
- parámetro3 es la acción se que realiza en el caso en que no se cumpla la condición.
> ejemplo = function(x){
+ suma = sum(x)
+ resultado = ifelse(suma < 100, TRUE, FALSE)
+ return(resultado)
+ }
> x = c(1:50)
> y = c(1:10)
> ejemplo(x)
[1] FALSE
> ejemplo(y)
[1] TRUE
Esta función devuelve el valor lógico TRUE si la suma de los elementos del vector es menor que 100 y FALSE en caso contrario.
Bucles
- for: Contador (recorre cada elemento del vector o matriz y efectúa una operación con dicho elemento)
- while: Condición (evalúa la condición y mientras esta es cierta se evalúa la acción)
- repeat: Repetición (evalúa la acción indefinidamente)
> x <- c(1:5)
> for (i in 1: length (x) ) {
+ cat ( ‘El cuadrado de ‘, i, ‘ es: ‘, i^2, ‘\n’ )
+ }
El cuadrado de 1 es: 1
El cuadrado de 2 es: 4
El cuadrado de 3 es: 9
El cuadrado de 4 es: 16
El cuadrado de 5 es: 25
Este ejemplo imprime los cuadrados del vector x formado por los elementos del 1 al 5.
> x = 1
> while (x <= 10 ){
+ cat (‘El cuadrado de ‘, x, ‘ es: ‘, x^2, ‘\n’)
+ x = x + 1
+ }
El cuadrado de 1 es: 1
El cuadrado de 2 es: 4
El cuadrado de 3 es: 9
El cuadrado de 4 es: 16
El cuadrado de 5 es: 25
El cuadrado de 6 es: 36
El cuadrado de 7 es: 49
El cuadrado de 8 es: 64
El cuadrado de 9 es: 81
El cuadrado de 10 es: 100
¿POR QUÉ UTILIZAR RStudio?
- Respeta la filosofía tradicional de la consola de R.
- Muestra los objetos del workspace.
- Muestra el historial de comandos.
- Tiene un visor de gráficos que unifica entornos.
- Integra un visor de paquetes instalados y/o cargados (library).
- Permite ejecutar trozos de código con sólo marcarlo en los scripts.
- Dispone de autocompletado de código.
- Presentaciones en HTML5
- Presentaciones con Sweave.
- Facilidad para trabajar con varios proyectos a la vez.
Autores: Manuel Hidalgo Arjona y Ana María Lara Porras. Universidad de Granada. (2016)