MÉTODOS DE ANÁLISIS MULTIVARIANTE: ANÁLISIS CLÚSTER
Objetivos
- Identificar grupos de objetos homogéneos.
- Determinar el criterio de similitud.
- Distinguir los Métodos de clasificación Jerárquicos y los Métodos de clasificación No-Jerárquicos o Repartición.
- Plantear y aplicar el Análisis Clúster Jerárquico.
- Distinguir los Métodos Jerárquicos Aglomerativos y los Métodos Jerárquicos Divisivos.
- Entender y aplicar el proceso algorítmico del Análisis Clúster Jerárquico Aglomerativo.
- Saber construir una matriz de distancias.
- Representar e Interpretar un dendograma.
- Plantear y aplicar el Análisis Clúster de K medias.
- Entender y aplicar el proceso algorítmico del Análisis Clúster de K medias.
- Plantear y aplicar el Análisis Clúster en dos etapas o bietápico.
Introducción al Análisis Clúster
El análisis clúster es una técnica multivariante cuya idea básica es clasificar objetos formando grupos/conglomerados (clúster) que sean lo más homogéneos posible dentro de sí mismos y heterogéneos entre sí.
Surge ante la necesidad de diseñar una estrategia que permita definir grupos de objetos homogéneos. Este agrupamiento se basa en la idea de distancia o similitud entre las observaciones y la obtención de dichos clústeres depende del criterio o distancia considerados, por ejemplo, una baraja de carta española se podría dividir de distintas formas: en dos clústeres (figuras y números), en cuatro clústeres (los cuatro palos), en ocho clústeres (los cuatro palos y según sean figuras o números). Es decir, el número de clústeres depende de lo que consideremos como similar.
El análisis clúster es una tarea de clasificación. Por ejemplo,
-
Clasificar grupos de consumidores respecto a sus preferencias en nuevos productos
-
Clasificar las entidades bancarias donde sería más rentable invertir
-
Clasificar las estrellas del cosmos en función de su luminosidad
-
Identificar si hay grupos de municipios en una determinada comunidad con una tendencia similar en el consumo de agua con el fin de identificar buenas prácticas para la sostenibilidad y zonas problemáticas por alto consumo.
Como se puede comprender fácilmente el análisis clúster tiene una extraordinaria importancia en la investigación científica, en cualquier rama del saber. La clasificación es uno de los objetivos fundamentales de la Ciencia y en la medida en que el análisis clúster nos proporciona los medios técnicos para realizarla, se nos hará imprescindible en cualquier investigación.
Planteamiento del problema
Consideremos una muestra \( X \) formada por n individuos sobre los que se miden p variables, \( X_1,X_2, \cdots, X_p \) (p variables numéricas observadas en n objetos o individuos). Sea \( x_{ij} \) el valor de la variable \( X_{j} \) en el i -ésimo objeto \( i= 1,2, \cdots, n \); \( j=1,2, \cdots, p \).
Este conjunto X de valores numéricos se pueden ordenar en una matriz
\( X = \left( \begin{matrix} x_{11} & x_{12} & \dots & x_{1j} & \dots & x_{1p} \\ x_{21} & x_{22} & \dots & x_{2j} & \dots & x_{2p} \\ \vdots & \vdots & \vdots & \vdots & \vdots & \vdots \\ x_{i1} & x_{i2} & \dots & x_{ij} & \dots & x_{ip} \\ \vdots & \vdots & \vdots & \vdots & \vdots & \vdots \\ x_{n1} & x_{n2} & \dots & x_{nj} & \dots & x_{np} \end{matrix} \right) \)
La i-ésima fila de la matriz X contiene los valores de cada variable para el i-ésimo individuo, mientras que la j-ésima columna muestra los valores pertenecientes a la j-ésima variable a lo largo de todos los individuos de la muestra.
Se trata, fundamentalmente, de resolver el siguiente problema: Dado un conjunto de n individuos caracterizados por la información de p variables \( X_{j} \), \( ( j=1,2, \cdots, p) \), nos planteamos clasificarlos de manera que los individuos pertenecientes a un grupo (clúster) (y siempre con respecto a la información disponible de las variables) sean lo más similares posibles entre sí y los distintos grupos sean entre ellos tan disimilares como sea posible.
El proceso completo puede estructurarse de acuerdo con el siguiente esquema:
-
Partimos de un conjunto de n individuos de los que se dispone de una información cifrada por un conjunto de p variables (una matriz de datos de n individuos y p variables).
-
Establecemos un criterio de similaridad y construimos una matriz de similaridades que nos permita relacionar la semejanza de los individuos entre sí. Para medir lo similares (o disimilares) que son los individuos existe una gran cantidad de índices de similaridad y de disimilaridad o divergencia. Todos ellos tienen propiedades y utilidades distintas y habrá que ser consciente de ellas para su correcta aplicación.
-
Elegimos un algoritmo de clasificación para determinar la estructura de agrupación de los individuos.
-
Especificamos esa estructura mediante diagramas arbóreos.
El análisis clúster: Técnica de agrupación de variables y de casos
-
Como técnica de agrupación de variables, el análisis clúster es similar al análisis factorial. Pero, mientras que el análisis factorial es poco flexible en algunos de sus supuestos (linealidad, normalidad, variables cuantitativas, etc.) y estima de la misma manera la matriz de distancias, el análisis clúster es menos restrictivo en sus supuestos (no exige linealidad, ni simetría, permite variables categóricas, etc.) y admite varios métodos de estimación de la matriz de distancias.
-
Como técnica de agrupación de casos, el análisis clúster es similar al análisis discriminante. Pero mientras que el análisis discriminante se centra en la agrupación de variables, es decir, efectúa la clasificación tomando como referencia un criterio o variable dependiente (los grupos de clasificación), el análisis clúster se centra en agrupar objetos, es decir permite detectar el número óptimo de grupos y su composición únicamente a partir de la similaridad existente entre los casos; además, el análisis de clúster no asume ninguna distribución específica para las variables.
Inconvenientes del Análisis Clúster: Es un análisis descriptivo, ateórico y no inferencial. Habitualmente se utiliza como una técnica exploratoria que no ofrece soluciones únicas, las soluciones dependen de las variables consideradas y del método de análisis clúster utilizado.
Aplicabilidad: Las técnicas de análisis clúster han sido tradicionalmente utilizadas en muchas disciplinas, por ejemplo, Astronomía (Clúster = galaxia, súper galaxias, etc.), Marketing (segmentación de mercados, investigación de mercados), Psicología, Biología (Taxonomía. Microarrays), Ciencias Ambientales (Clasificación de ríos para establecer tipologías según la calidad de las aguas), Sociología, Economía, Ingeniería,…
JAIN and DUBES (1988) definen el Análisis de Clúster como una herramienta de exploración de datos que se complementa con técnicas de visualización de los mismos.
Resumiendo
-
El objetivo del Análisis Clúster es obtener grupos de objetos de forma que, por un lado, los objetos pertenecientes a un mismo grupo sean muy semejantes entre sí y, por el otro, los objetos pertenecientes a grupos diferentes tengan un comportamiento distinto con respecto a las variables analizadas.
-
Es una técnica exploratoria puesto que la mayor parte de las veces no utiliza ningún tipo de modelo estadístico para llevar a cabo el proceso de clasificación.
-
Conviene estar siempre alerta ante el peligro de obtener, como resultado del análisis, no una clasificación de los datos sino una disección de los mismos en distintos grupos. El conocimiento que el analista tenga acerca del problema decidirá que grupos obtenidos son significativos y cuáles no.
-
Una vez establecidas las variables y los objetos a clasificar el siguiente paso consiste en establecer una medida de proximidad o de distancia entre ellos que cuantifique el grado de similaridad entre cada par de objetos.
- Las medidas de proximidad, similitud o semejanza miden el grado de semejanza entre dos objetos de forma que, cuanto mayor (menor) es su valor, mayor (menor) es el grado de similaridad existente entre ellos y mayor (menor) es la probabilidad de que los métodos de clasificación los asignen en el mismo grupo.
-
Las medidas de disimilitud, desemejanza o distancia miden la distancia entre dos objetos de forma que, cuanto mayor (menor) sea su valor, más (menos) diferentes son los objetos y menor (mayor) es la probabilidad de que los métodos de clasificación los asignen en el mismo grupo.
Métodos de clasificación
-
-
Se distinguen dos grandes categorías de métodos clústeres: Métodos jerárquicos y Métodos no-jerárquicos
-
Métodos Jerárquicos: En cada paso del algoritmo sólo un objeto cambia de grupo y los grupos están anidados en los de pasos anteriores. Si un objeto ha sido asignado a un grupo ya no cambia más de grupo. La clasificación resultante tiene un número creciente de clases anidadas.
-
Métodos No jerárquico o Repartición: Comienzan con una solución inicial, un número de grupos g fijado de antemano y agrupa los objetos para obtener los g grupos.
Los métodos jerárquicos se subdividen a su vez en aglomerativos y divisivos:
-
Los métodos jerárquicos aglomerativos comienzan con tantos clústeres como objetos tengamos que clasificar y en cada paso se recalculan las distancias entre los grupos existentes y se unen los dos grupos más similares o menos disimilares. El algoritmo acaba con un clúster conteniendo todos los elementos.
-
Los métodos jerárquicos divisivos comienzan con un clúster que engloba a todos los elementos y en cada paso se divide el grupo más heterogéneo. El algoritmo acaba con tantos clústeres (de un elemento cada uno) como objetos se hayan clasificado.
Independientemente del proceso de agrupamiento, hay diversos criterios para ir formando los clústeres; todos estos criterios se basan en una matriz de distancias o similitudes. Por ejemplo, dentro de los métodos:
-
-
-
Jerárquicos aglomerativos:
- Método del Linkage Simple, Enlace Simple o Vecino más próximo
- Método del Linkage Completo, Enlace Completo o Vecino más alejado
- Método del Promedio entre grupos
- Método del Centroide
- Método del la Mediana
- Método de Ward
-
Jerárquicos divisivos o disociativos
- Método del Linkage Simple
- Método del Linkage Completo
- Método del Promedio entre grupos
- Método del Centroide
- Método del la Mediana
- Análisis de Asociación
Proceso que se debe seguir en un análisis clúster
-
Paso 1: Selección de variables
La clasificación dependerá de las variables elegidas. Introducir variables irrelevantes aumenta la posibilidad de errores. Hay que utilizar algún criterio de selección:
- Seleccionar sólo aquellas variables que caracterizan los objetos que se van agrupando, y referentes a los objetivos del análisis clúster que se va a realizar
- Si el número de variables es muy grande se puede realizar previamente un Análisis de Componentes Principales y resumir el conjunto de variables.
Paso 2: Detección de valores atípicos. El análisis clúster es muy sensible a la presencia de objetos muy diferentes del resto (valores atípicos).
Paso 3. Seleccionar la forma de medir la distancia/disimilitud entre objetos dependiendo de si los datos con cuantitativos o cualitativos
- Datos métricos: Medidas de correlación y medidas de distancia
- Datos no métricos: Medidas de asociación.
Paso 4: Estandarización de los datos (Decidir si se trabaja con los datos según se miden o estandarizados). El orden de las similitudes puede cambiar bastante con sólo un cambio de escala de una de las variables por lo que sólo se realizará una tipificación cuando resulte necesario.
Paso 5: Obtención de los clusters y valoración de la clasificación realizada
- Elegir el algoritmo para la formación de clúster (Procedimientos jerárquicos o procedimientos no jerárquicos)
- Número de clusters: Regla de parada. Existen diversos métodos de determinación del número de clusters, algunos están basados en reconstruir la matriz de distancias original, otros en los coeficientes de concordancia de Kendall y otros realizan análisis de la varianza entre los grupos obtenidos. No existe un criterio universalmente aceptado. Dado que la mayor parte de los paquetes estadísticos proporciona las distancias de aglomeración, es decir, las distancias a las que se forma cada clúster, una forma de determinar el número de grupos consiste en localizar en qué iteraciones del método utilizado dichas distancias dan grandes saltos
- Adecuación del modelo. Comprobar que el modelo no ha definido clúster con un solo objeto, clúster con tamaños desiguales,…
Análisis clúster en R-Commander
En R-Commander tenemos 2 tipos de análisis clúster:
- Agrupación por K-medias
- Agrupación jerárquica
- Análisis de conglomerados de K medias. Es un método de clasificación No Jerárquico (Repartición). El número de clústeres que se van a formar es fijado de antemano (requiere conocer el número de clústeres a priori) y se agrupan los objetos para obtener esos grupos. Comienzan con una solución inicial y los objetos se reagrupan de acuerdo con algún criterio de optimalidad. El clúster no jerárquico sólo puede ser aplicado a variables cuantitativas. Este procedimiento puede analizar archivos de datos grandes.
-
Análisis de conglomerados jerárquicos. En el método de clasificación Jerárquico en cada paso del algoritmo sólo un objeto cambia de grupo y los grupos están anidados en los pasos anteriores. Si un objeto ha sido asignado a un grupo ya no cambia más de grupo.
El método jerárquico es idóneo para determinar el número óptimo de conglomerados existente en los datos y el contenido de los mismos. Se utiliza cuando no se conoce el número de clústeres a priori y cuando el número de objetos no es muy grande. Permite trabajar conjuntamente con variables de tipo mixto (cualitativas y cuantitativas). Siempre que todas las variables sean del mismo tipo, el procedimiento Análisis de Conglomerados Jerárquico podrá analizar variables de intervalo (continuas), de recuento o binarias.
Los dos métodos de análisis que vamos a estudiar son de tipo aglomerativo, en el sentido de que, partiendo del análisis de los casos individuales, intentan ir agrupando casos hasta llegar a la formación de grupos o conglomerados homogéneos.
Todos los métodos de análisis clúster son métodos exploratorios de datos
- Para cada conjunto de datos podemos tener diferentes agrupaciones, dependiendo del método
- Lo importante es identificar una solución que nos enseñe cosas relevantes de los datos.
En esta práctica vemos en primer lugar el Análisis clúster Jerárquico, y posteriormente el Análisis Clúster de K medias.
Análisis clúster jerárquico
Este procedimiento intenta identificar grupos relativamente homogéneos de casos (o de variables) basándose en las características seleccionadas. Permite trabajar conjuntamente con variables de tipo mixto (cualitativas y cuantitativas), siendo posible analizar las variables brutas o elegir de entre una variedad de transformaciones de estandarización. Se utiliza cuando no se conoce el número de clústeres a priori y cuando el número de objetos no es muy grande. Como hemos dicho anteriormente, los objetos de análisis de agrupamiento jerárquico pueden ser casos o variables, dependiendo de si desea clasificar los casos o examinar las relaciones entre las variables.
Al trabajar con variables que pueden ser cuantitativas, binarias o datos de recuento (frecuencias), el escalamiento de las variables es un aspecto importante, ya que las diferentes escalas en que están medidas las variables pueden afectar a las soluciones de conglomeración. Si las variables muestran grandes diferencias en el escalamiento (por ejemplo, una variable se mide en dólares y la otra se mide en años), se debe considerar la posibilidad de estandarizarlas. Esto puede llevarse a cabo automáticamente mediante el propio procedimiento Análisis de conglomerados jerárquico.
Estudiaremos fundamentalmente los Métodos Jerárquicos Aglomerativos. En estos métodos se utilizan diversos criterios para determinar, en cada paso del algoritmo, qué grupos se deben unir.
-
Enlace simple o vecino más próximo: Mide la proximidad entre dos grupos calculando la distancia entre sus objetos más próximos o la similitud entre sus objetos más semejantes
-
Enlace completo o vecino más alejado: Mide la proximidad entre dos grupos calculando la distancia entre sus objetos más lejanos o la similitud entre sus objetos menos semejantes
-
Enlace medio entre grupos: Mide la proximidad entre dos grupos calculando la media de las distancias entre objetos de ambos grupos o la media de las similitudes entre objetos de ambos grupos
-
Enlace medio dentro de los grupos: Mide la proximidad entre dos grupos con la distancia media existente entre los miembros del grupo unión de los dos grupos
-
Métodos del centroide y de la mediana: Ambos métodos miden la proximidad entre dos grupos calculando la distancia entre sus centroides. Los dos métodos difieren en la forma de calcular los centroides:
-
El método del centroide utiliza las medias de todas las variables
-
En el método de la mediana, el nuevo centroide es la media de los centroides de los grupos que se unen
-
-
Método de Ward:
Comparación de los diversos métodos aglomerativos
- El enlace simple conduce a clusters encadenados
- El enlace completo conduce a clusters compactos
- El enlace completo es menos sensible a outliers que el enlace simple
- El método de Ward y el método del enlace medio son los menos sensibles a outliers
- El método de Ward tiene tendencia a formar clusters más compactos y de igual tamaño y forma en comparación con el enlace medio
- Todos los métodos salvo el método del centroide satisfacen la desigualdad ultramétrica
\( d_{t} \leq min (d_{r}, d_{s} ) \hspace {.2cm}; \hspace{.2cm}t =r \cup s \)
Decisiones que hay que tomar para hacer un clúster
- Elegir el método clúster que se va a utilizar
- Decidir si se estandarizan los datos
- Seleccionar la forma de medir la distancia/disimilitud entre los individuos
- Elegir un criterio para unir grupos, distancia entre grupos.
Proceso que se debe seguir en un Análisis Clúster Jerárquico Aglomerativo
Paso 1: Selección de las variables. Se recomienda que las variables sean del mismo tipo (continuas, categóricas,..)
Paso 2: Detección de valores atípicos. El análisis clúster es muy sensible a la presencia de objetos muy diferentes del resto (valores atípicos).
Paso 3: Elección de una medida de similitud entre objetos y obtención de la matriz de distancias. Mediante estas medidas se determinan los clústeres iniciales.
Paso 4: Buscar los clústeres más similares
Paso 5: Unir estos dos clústeres en un nuevo clúster que tenga al menos dos objetos, de forma que el número de clúster decrece en una unidad.
Paso 6: Calcular la distancia entre este clúster y el resto. Los distintos métodos para el cálculo de las distancias entre los clústeres producen distintas agrupaciones, por lo que no existe una agrupación única.
Paso 7: Repetir desde el paso 4 hasta que todos los objetos estén en un único clúster.
El proceso de agrupación jerárquico se puede resumir gráficamente mediante una representación gráfica en forma de árbol que recibe el nombre de Dendograma. Los objetos similares se enlazan y su posición en el diagrama está determinada por el nivel de similitud/disimilitud entre los objetos.
Vamos a realizar el proceso descrito y para ello utilizamos un ejemplo sencillo. Dicho ejemplo está formado por 5 objetos (A, B, C, D, E) y 2 variables \( (X_1, X_2 ) \). Los datos se presentan en la siguiente tabla
\( \begin{array} {|c|c|c|} \hline Objetos/individuos & X_1 & X_2 \\ \hline A & 1 & 1 \\ \hline B & 2 & 1 \\ \hline C & 4 & 5 \\ \hline D & 7 & 7 \\ \hline E & 5 & 7 \\ \hline \end{array} \)
Paso 1 y 2: Para detectar valores atípicos podemos representar los puntos en el plano
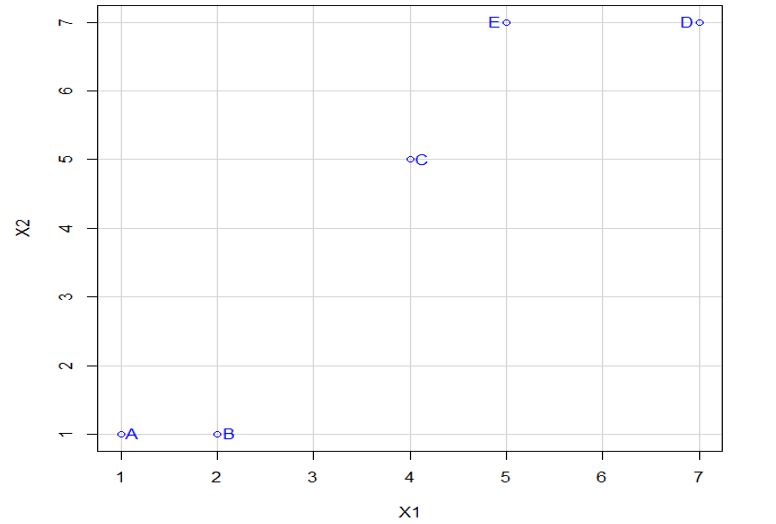
En este caso no detectamos valores atípicos, no hay ningún valor que sea muy distinto de los demás.
Paso 3: La medida de distancia que vamos a tomar entre los objetos va a ser la distancia euclídea cuya expresión es:
\( d(P_1, P_2) = \displaystyle \sqrt {(x_2-x_1)^{2} + (y_2-y_1)^{2} } \)
Así, por ejemplo, la distancia entre el clúster A y el clúster B es:
\( d(A, B) = \displaystyle \sqrt {(2-1)^{2} + (1-1)^{2}} = 1 \)
Realizamos la distancia euclídea entre todos los puntos y obtenemos la siguiente matriz de distancias euclídeas entre los objetos
\( \begin{array} {|c|c|c|c|c|c|} \hline & A & B & C & D & E \\ \hline A & 0 & & & & \\ \hline B & 1 & 0 & & & \\ \hline C & 5 & 4.5 & 0 & & \\ \hline D & 8.5 & 7.8 & 3.6 & 0 & \\ \hline E & 7.2 & 6.7 & 2.2 & 2 & 0 \\ \hline \end{array} \)
Nota: Estamos realizando el método jerárquico aglomerativo, por lo que inicialmente tenemos 5 clusters, uno por cada uno de los objetos a clasificar.
Paso 4: Observamos en la matriz de distancias cuales son los objetos más similares, en nuestro ejemplo son el A y B que tienen la distancia menor (1).
Paso 5: Fusionamos los clústeres más similares construyendo un nuevo clúster que contiene A y B. Se han formado los clústeres: AB, C, D y E.
Paso 6: Calculamos la distancia entre el clúster AB y los objetos C, D y E. Para medir esta distancia tomamos como representante del clúster AB el centroide, es decir, el punto que tiene como coordenadas las medias de los valores de las componentes de las variables, es decir, las coordenadas de AB son: ((1+2)/2 , (1+1)/2) = (1.5, 1). La tabla de datos es la siguiente
\( \begin{array} {|c|c|c|} \hline Cluster & X_1 & X_2 \\ \hline AB & 1.5 & 1 \\ \hline C & 4 & 5 \\ \hline D & 7 & 7 \\ \hline E & 5 & 7 \\ \hline \end{array} \)
Paso 7: Repetimos desde el paso 4 hasta que todos los objetos estén en un único clúster
Paso 4: A partir de estos datos calculamos de nuevo la matriz de distancias
\( \begin{array} {|c|c|c|c|c|} \hline & AB & C & D & E \\ \hline AB & 0 & & & \\ \hline C & 4.7 & 0 & & \\ \hline D & 8.1 & 3.6 & 0 & \\ \hline E & 6.9 & 2.2 & 2 & 0 \\ \hline \end{array} \)
Paso 5: Los clústeres más similares son el D y E con una distancia de 2, que se fusionan en un nuevo clúster DE. Se han formado tres clústeres AB, C, DE
Paso 6: Calculamos el centroide del nuevo clúster que es el punto (6,7) y formamos de nuevo la tabla de datos
\( \begin{array} {|c|c|c|} \hline Cluster & X_1 & X_2 \\ \hline AB & 1.5 & 1 \\ \hline C & 4 & 5 \\ \hline DE & 6 & 7 \\ \hline \end{array} \)
Paso 4: A partir de estos datos calculamos de nuevo la matriz de distancias
\( \begin{array} {|c|c|c|c|} \hline & AB & C & DE \\ \hline AB & 0 & & \\ \hline C & 4.7 & 0 & \\ \hline DE & 7.5 & 2.8 & 0 \\ \hline \end{array} \)
Paso 5: Los clusters más similares son el C y DE con una distancia de 2.8, que se fusionan en un nuevo clúster CDE. Se han formado dos clusters AB y CDE
Paso 6. Calculamos el centroide del nuevo clúster ((4+5+7)/3 , (5+7+7)/3) = (5.3, 6.3) y formamos de nuevo la tabla de datos
\( \begin{array} {|c|c|c|} \hline Cluster & X_1 & X_2 \\ \hline AB & 1.5 & 1 \\ \hline CDE & 5.3 & 6.3 \\ \hline \end{array} \)
Paso 4 : A partir de estos datos calculamos de nuevo la matriz de distancias
\( \begin{array} {|c|c|c|} \hline & AB & CDE \\ \hline AB & 0 & \\ \hline CDE & 6.4 & 0 \\ \hline \end{array} \)
En este último paso tenemos solamente dos clusters con distancia 6.4 que se fusionarán en un único clúster en el paso siguiente terminando el proceso.
A continuación vamos a representar gráficamente el proceso de fusión mediante un dendograma
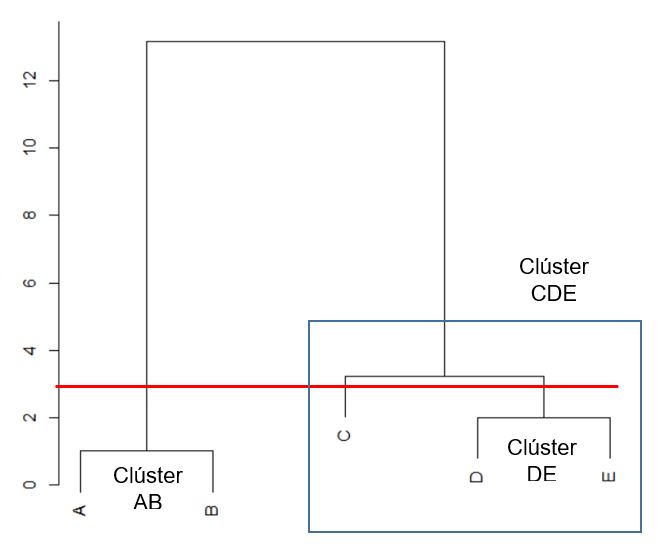
En esta figura la línea de corte nos muestra 3 clústeres: AB, C y DE
El número de clústeres depende del sitio donde cortemos el dendograma, por lo tanto la decisión sobre el número óptimo de clústeres es subjetiva. Es conveniente elegir un número de clústeres que sepamos interpretar. Para interpretar los clúster podemos utilizar: ANOVA, Análisis factorial, Análisis discriminante, sentido común, etc.
Para decidir el número de clústeres nos puede ser de gran utilidad representar los distintos pasos del algoritmo y las distancias a la que se produce la fusión de los clústeres. En los primeros pasos el salto de las distancias es pequeño, mientras que esas diferencias van aumentando en los sucesivos pasos. Podemos elegir como punto de corte aquel donde comienzan a producirse saltos más bruscos. En nuestro ejemplo, el salto brusco se produce entre etapas 3 y 4, por lo tanto son dos el número de clústeres óptimo.
Consideraciones sobre el clúster jerárquico
- Realizar el clúster jerárquico en conjunto de datos grande es problemático ya que un árbol con más de 50 individuos es difícil de representar e interpretar.
- Una desventaja general es la imposibilidad de reasignar los individuos a los clústeres en los casos en que la clasificación haya sido dudosa en las primeras etapas del análisis.
- Debido a que el análisis clúster implica la elección entre diferentes medidas y procedimientos, con frecuencia es difícil juzgar la veracidad de los resultados.
- Se recomienda comparar los resultados con diferentes métodos de conglomerados. Soluciones similares generalmente indican la existencia de una estructura en los datos. Soluciones muy diferentes probablemente indican una estructura pobre.
- En último caso, la validez de los clústeres se juzga mediante una interpretación cualitativa que puede ser subjetiva.
- El número de clústeres depende del sitio donde cortemos el dendograma.
Supuesto práctico 1
Los fabricantes de automóviles deben adaptar sus estrategias de desarrollo de productos y de marketing en función de cada grupo de consumidores para aumentar las ventas y el nivel de fidelidad a la marca. La tarea de agrupación de los coches según variables que describen los hábitos de consumo, sexo, edad, nivel de ingresos, etc. de los clientes puede ser en gran medida automática utilizando el análisis de clúster.
Se desea hacer un estudio de mercado sobre las preferencias de los consumidores al adquirir un vehículo, para ello disponemos una base de datos, ventas_vehículos.txt, de automóviles y camiones en los que figura una serie de variables como el fabricante, modelo, ventas, etc.
El archivo de datos ventas_vehículos.txt, contiene 157 datos y está formado por las siguientes variables:
- Variables tipo cadena: marca (Fabricante); modelo
- Variables tipo numérico: ventas (en miles); reventa (Valor de reventa en 4 años); tipo (Tipo de vehículo: Valores: {0, Automóvil; 1, Camión}); precio (en miles); motor (Tamaño del motor); CV (Caballos); pisada (Base de neumáticos); ancho (Anchura); largo (Longitud); peso_neto (Peso neto); depósito (Capacidad de combustible); mpg (Consumo).
Para resolver el supuesto recordemos que:
En primer lugar cargamos el paquete R-Commander, para ello en la ventana de comandos de R se escribe la orden
> library(Rcmdr)
Una vez cargado el paquete aparecerá la siguiente pantalla
Una vez activado R Commander, pasamos a importar datos de archivo de texto
Seleccionamos en el menú principal de R-Commander: Datos/Importar datos/desde archivo de texto, portapapeles o URL…
Se muestra la siguiente pantalla
En la ventana correspondiente al nombre del conjunto de datos introducir: Auto
Pulsar Aceptar
Seleccionamos el archivo ventas_vehículos.txt
El estudio de mercado lo queremos realizar sólo en automóviles de mayor venta. Para ello, en primer lugar restringiremos el archivo de datos sólo a los automóviles de los que se vendieron al menos 100.000 unidades. Para ello seleccionamos los casos que cumplan esa condición eligiendo en los menús Datos, Conjunto de datos activos, Filtrar el conjunto de datos activos, como se muestra en la siguiente figura:
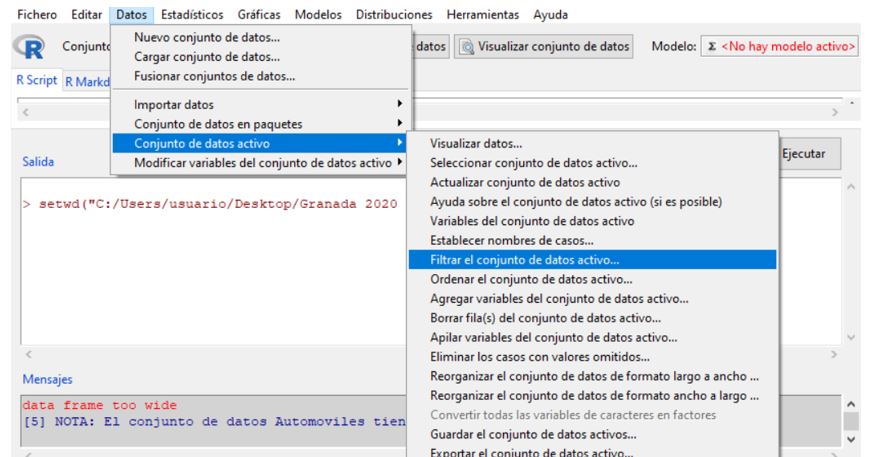
En el menú Filtrar, dejamos la opción marcada Incluir todas las variables. En Expresión de selección ponemos: 100.000<ventas&tipo==”Automóvil”. Los valores de las variables deben de aparecer escritos de la misma manera que aparecen en el fichero de datos.
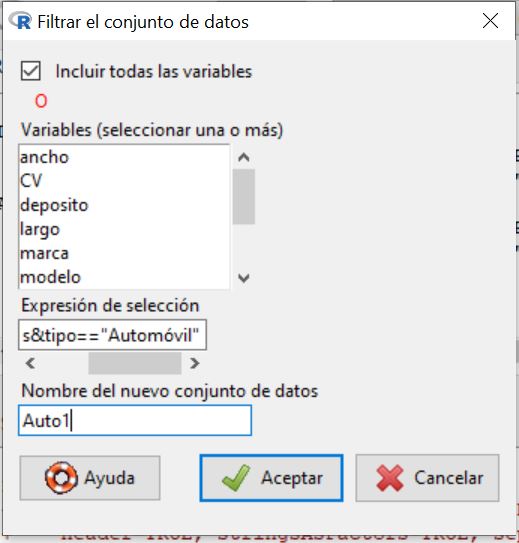
Le damos un nuevo nombre al conjunto de datos, Auto1, para que no sobrescriba el fichero con el que estamos trabajando, como se muestra a continuación:
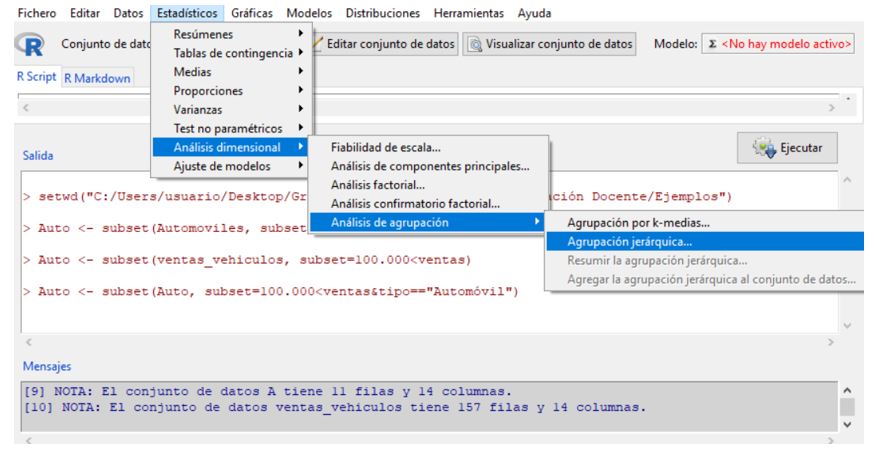
Una vez seleccionada la muestra con la que vamos a trabajar, utilizamos el Análisis de Conglomerados Jerárquicos para agrupar los automóviles de mayor venta en función de sus precios, fabricante, modelo y propiedades físicas. Para ejecutar este análisis clúster se elige en los menús: Estadísticos/Análisis dimensional/Análisis de agrupación/Agrupación jerárquica.
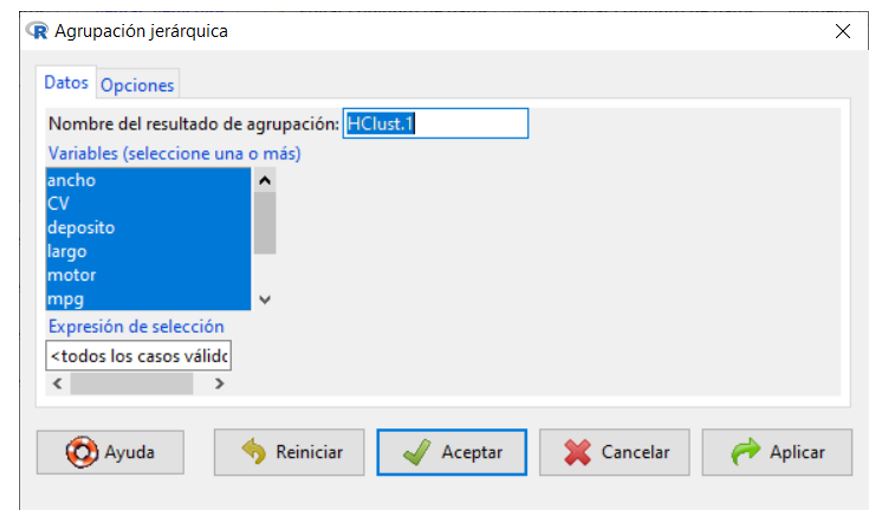
En agrupación jerárquica, tenemos primero la pestaña Datos dónde vamos a seleccionar las variables con las que queremos trabajar, en este caso: precio (en miles); motor (Tamaño del motor); CV (Caballos); pisada (Base de neumáticos); ancho (Anchura); largo (Longitud); peso_neto (Peso neto); depósito (Capacidad de combustible) y mpg (Consumo). Además podemos darle un nombre al resultado de nuestra agrupación, en este caso dejamos el que aparece por defecto: HClust.1.
En la pestaña Opciones, tenemos los métodos de agrupación, así como las medidas de la distancias y la posibilidad de obtener el dendograma:
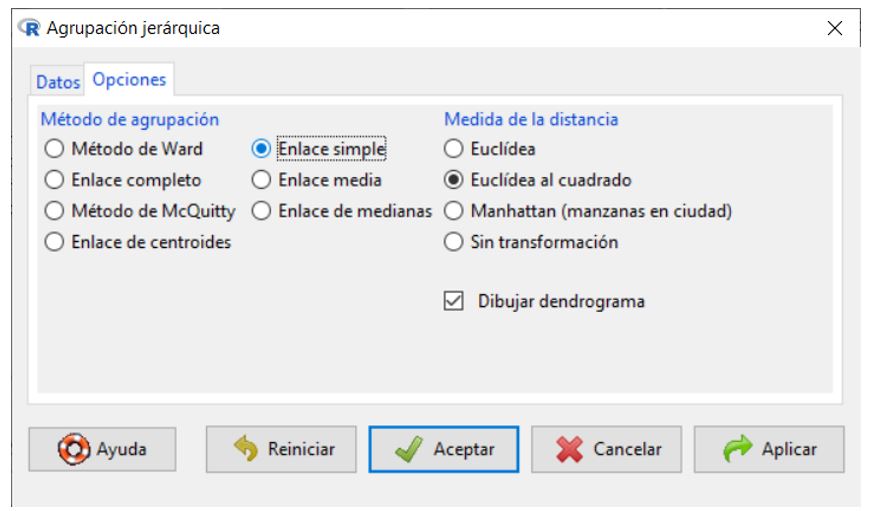
Método de agrupación. Los métodos de enlace (linkage) utilizan la proximidad entre pares de individuos para unir grupos de individuos. Existen diversas formas de medir la distancia entre clúster que producen diferentes agrupaciones y diferentes dendogramas. No hay un criterio para seleccionar cual es el algoritmo mejor. La decisión es normalmente subjetiva y depende del método que mejor refleje los propósitos de cada estudio en particular. Las opciones disponibles en R Commander son:
- Método de Ward. Tiene tendencia a formar clústeres más compactos y de igual tamaño y forma, en comparación con el enlace medio.
- Enlace completo (O vecino más lejano). Utiliza la máxima distancia/disimilitud entre dos individuos de cada grupo. Conduce a clústeres compactos.
- Método de McQuitty. Forma los enlaces considerando el promedio no ponderado entre grupos.
- Enlace simple. (O vecino más próximo). Mide la proximidad entre dos grupos calculando la distancia entre sus objetos más próximos o la similitud entre sus objetos más semejantes.
- Enlace media. Utiliza el promedio ponderado entre grupos.
- Enlace de centroides. Utiliza la distancia/disimilitud entre los centros de los grupos.
- Enlace de medianas. Utiliza la mediana de las distancias/disimilitud entre todos los individuos de los dos grupos
El método de Ward y el método de la media (enlace medio) son los menos sensibles a outliers.
Medida de la distancia (disimilaridad o similaridad) entre objetos: esta medida nos permite establecer el grado de semejanza entre dichos objetos. Mediante esta opción seleccionamos la medida que vamos a utilizar para ver el parecido entre individuos con distintas distancias dependiendo si la variable es binaria, frecuencia o de intervalo. La elección inicial del conjunto de medidas que describan a los elementos a agrupar es fundamental para establecer los posibles clústeres. Las medidas de distancia o similaridad que utilizamos en la aglomeración se deben seleccionar dependiendo del tipo de datos. R dispone de las siguientes medidas:
- Euclídea. No es una distancia invariante por cambios de escala. Se usa cuando las variables son de tipo intervalo.
- Euclídea al cuadrado. Se usa cuando las variables son de tipo intervalo.
- Manhattan. Se usa cuando las variables son de tipo intervalo.
- Sin transformación
Dendrograma. Es una representación gráfica en forma de árbol, en el que los clústeres están representados mediante trazos verticales (horizontales) y las etapas de fusión mediante trazos horizontales (verticales). La separación entre las etapas de fusión es proporcional a la distancia a la que están los grupos que se funden en esa etapa. Los dendrogramas pueden emplearse para evaluar la cohesión de los conglomerados que se han formado y proporcionar información sobre el número adecuado de conglomerados que deben conservarse.
En nuestro ejemplo, hemos seleccionado, elegimos una medida de intercalo, la Distancia euclídea al cuadrado, dado que las variables en el análisis son variables de escala. Elegimos como método de clúster Enlace simple, apropiado cuando se desea examinar los grados de similitud pero es pobre en la construcción de distintos grupos. Por lo tanto, después de examinar los resultados con este método deberíamos realizar de nuevo el estudio con un método distinto del clúster.
Al pulsar Aceptar se obtiene el siguiente dendograma:
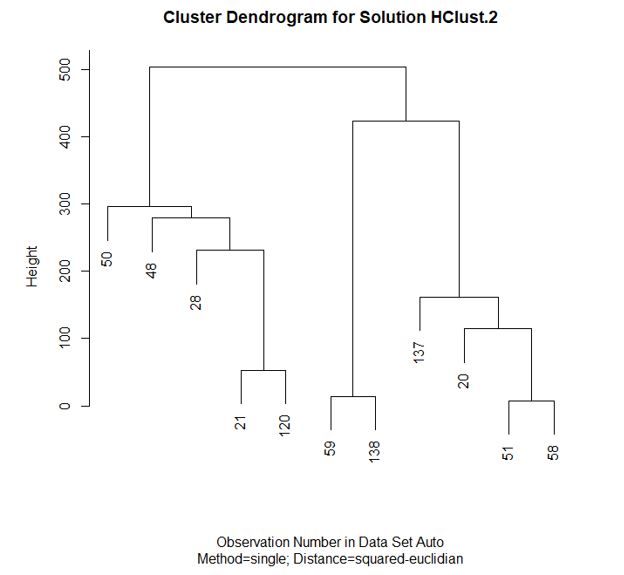
El dendrograma es un resumen gráfico de la solución de clúster. Los casos se encuentran en el eje horizontal. El eje vertical muestra la distancia entre los grupos cuando se unieron.
Analizar el árbol de clasificación para determinar el número de grupos es un proceso subjetivo. En general, se comienza por buscar “huecos” entre uniones a lo largo del eje vertical. De arriba abajo se encuentra el primer hueco a una altura cercana a 400. En este punto se dividen los coches en 2 grupos:
- Un grupo está formado por los modelos: Taurus (50), Mustang (48), Impala (28), Malibu (21) y Grand Am (120).
- El otro grupo está formado por los modelos: Accord (59), Camry (138), Corolla (137), Cavalier (20), Focus (51), Civic (58).
El siguiente hueco se encuentra a una altura de aproximadamente 300 y proporciona 3 clústeres (50, 48, 28, 21, 120); (59, 138) ; (137, 20, 51, 59).
Por debajo de 300 se encuentra la división en 4 clústeres (50); (48, 28, 21, 120); (59, 138) (137, 20, 51, 58).
Continuamos hasta que cada modelo forma su propio clúster. Por ejemplo, en torno a 150 nos encontramos con una división en 6 clústeres: (50); (48); (28); (21, 120); (59, 138) (137, 20, 51, 58)
Mirando a las soluciones proporcionadas no parece que este método nos proporcione una solución con sentido, por ejemplo en la solución de 3 clústeres aparece un coche pequeño y barato con los más grandes y caros.
El dendograma es la única salida que obtenemos en este menú.
Si deseamos obtener la matriz de distancias debemos introducir las siguientes órdenes en la ventana de comandos de R Commander:
> d = dist(model.matrix(~-1 + ancho + CV + deposito + largo + motor + mpg + peso_neto + pisada + precio, Auto))^2
> d
La matriz de distancias viene dada por:
20 21 28 48 5 0 5 1 58 59 120 137
21 3142.076250
28 4697.715269 231.120269
48 5747.857729 525.273729 484.903496
50 1958.659489 295.982989 645.930466 1498.472850
51 114.575569 4282.105569 6126.811250 7132.258346 2967.811316
58 147.464194 4424.509444 6275.522525 7320.502121 3078.978841 7.395525
59 488.293636 1238.848386 2184.650449 3147.407541 504.606321 1040.416649 1111.577874
120 3691.973825 53.085825 239.717704 279.198144 541.943954 4870.571754 5022.182729 1634.212181
137 161.918640 2957.322490 4585.310485 5207.389393 2067.898433 215.369585 238.596290 611.758708 3404.708785
138 423.684248 1394.369098 2383.475265 3337.079789 602.271589 943.159565 1012.378970 13.694580 1793.357453 542.082184
Recordemos que la matriz de distancias proporciona las distancias o similaridades entre los casos.
Además, podemos obtener otras salidas de interés. En el menú Estadísticos, Análisis dimensional, análisis de agrupación, Resumir la agrupación jerárquica, podemos obtener los valores de los centroides para cada una de las variables seleccionadas en cada clúster
Dentro del menú Agrupación jerárquica, seleccionamos por ejemplo Número de grupos: 3, que corresponde a seleccionar 3 clústeres.
Al pulsar aceptar obtenemos la siguiente salida:
INDICES: 1
ancho CV deposito largo motor mpg peso_neto pisada precio
67.15000 112.00000 13.15000 176.20000 1.90000 30.50000 2.49975 101.82500 12.89200
——————————————————————————————————————-
INDICES: 2
ancho CV deposito largo motor mpg peso_neto pisada precio
71.7800 174.0000 15.7800 191.5000 3.3400 25.0000 3.2204 106.8600 18.9180
——————————————————————————————————————-
INDICES: 3
ancho CV deposito largo motor mpg peso_neto pisada precio
70.200 134.000 17.800 188.650 2.250 27.000 2.965 106.050 16.434
Esta tabla corresponde a los centroides dentro de cada variable, dentro de cada uno de los clústeres creados. Esto nos permite comparar las similaridades en los valores de cada variable en los distintos clústeres.
Supuesto práctico 2
Repetimos el ejemplo anterior pero cambiando el método de agrupación para poder comparar. Usamos ahora el Enlace completo.
Para ejecutar este análisis elegimos en el menu principal: Estadísticos/Análisis dimensional/Análisis de agrupación/Agrupación jerárquica.
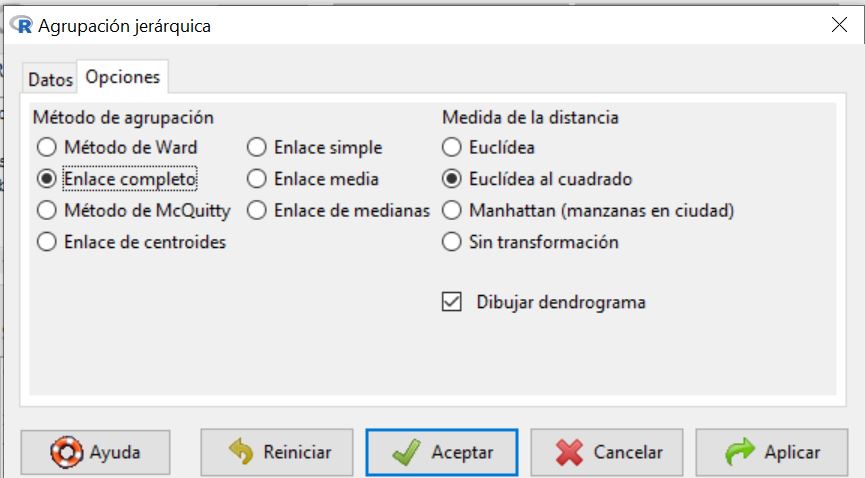
En esta ventana elegimos Enlace completo y pulsamos Aceptar. Se obtiene el siguiente dendograma:
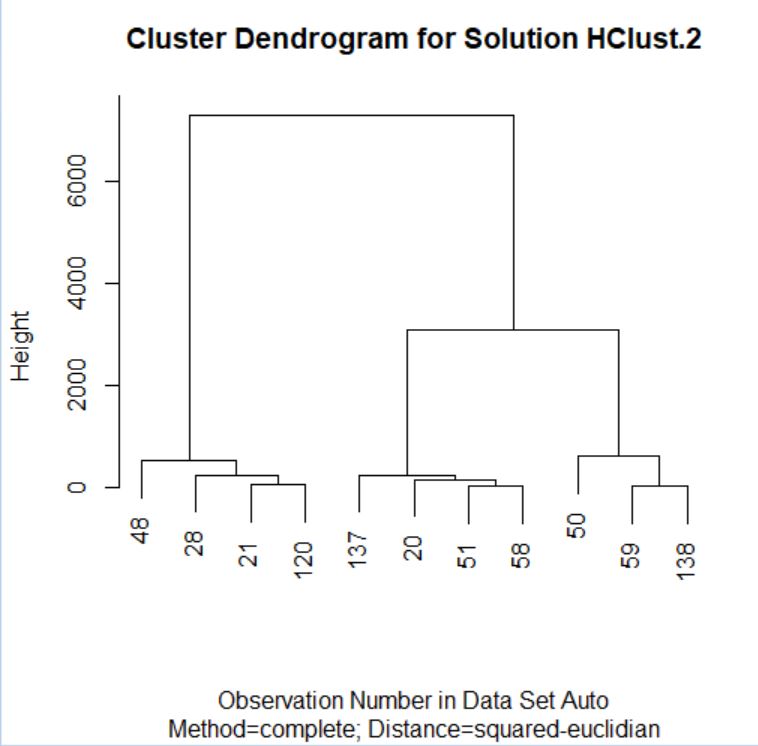
Analizando este dendograma podemos ver:
- La división inicial del árbol forma dos grupos, (48, 28, 21,120) y (137, 20, 51, 58, 50, 59, 138). El clúster primero contiene los automóviles más grandes y el segundo contiene los más pequeños.
- El grupo de coches más pequeños se puede dividir en dos subgrupos, uno de ellos formado por los coches más pequeños y más baratos. Así la división siguiente en 3 clusters: (Mustang (48), Impala (28), Malibu (21) y Grand Am (120)); (Corolla (137), Cavalier (20), Focus (51), Civic (58) este segundo grupo está formado por los coches más pequeños y baratos; (Taurus (50), Accord (59) y Camry (138).
Mirando el dendograma podemos pensar que la solución óptima dada por este método es aquella que considerar 3 clústeres. El dendograma es la única salida que obtenemos en este menú.
La matriz de distancias será la misma que hemos obtenido en el caso anterior
> d = dist(model.matrix(~-1 + ancho + CV + deposito + largo + motor + mpg + peso_neto + pisada + precio, Auto))^2
> d
La matriz de distancias viene dada por:
20 21 28 48 5 0 5 1 58 59 120 137
21 3142.076250
28 4697.715269 231.120269
48 5747.857729 525.273729 484.903496
50 1958.659489 295.982989 645.930466 1498.472850
51 114.575569 4282.105569 6126.811250 7132.258346 2967.811316
58 147.464194 4424.509444 6275.522525 7320.502121 3078.978841 7.395525
59 488.293636 1238.848386 2184.650449 3147.407541 504.606321 1040.416649 1111.577874
120 3691.973825 53.085825 239.717704 279.198144 541.943954 4870.571754 5022.182729 1634.212181
137 161.918640 2957.322490 4585.310485 5207.389393 2067.898433 215.369585 238.596290 611.758708 3404.708785
138 423.684248 1394.369098 2383.475265 3337.079789 602.271589 943.159565 1012.378970 13.694580 1793.357453 542.082184
Finalmente obtenemos el resumen de la agrupación jerárquica proporcionada por este método:
Dentro del menú Agrupación jerárquica, seleccionamos Número de grupos: 3, que corresponde a la solución óptima viendo el dendograma.
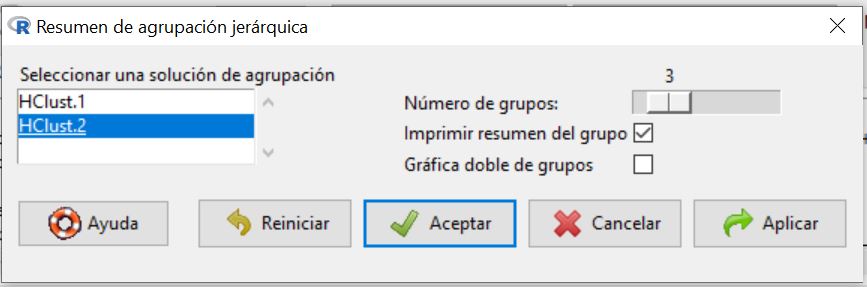
Al pulsar aceptar obtenemos la siguiente salida:
INDICES: 1
ancho CV d eposito largo motor mpg peso_neto pisada precio
67.15000 112.00000 13.15000 176.20000 1.90000 30.50000 2.49975 101.82500 12.89200
——————————————————————————————————————-
INDICES: 2
ancho CV deposito largo motor mpg peso_neto pisada precio
71.47500 178.75000 15.72500 189.97500 3.42500 25.25000 3.18350 106.45000 19.17625
——————————————————————————————————————-
INDICES: 3
ancho CV deposito largo motor mpg peso_neto pisada precio
71.133333 141.000000 17.200000 191.633333 2.500000 26.000000 3.099333 106.866667 16.917667
Resumen
La solución proporcionada por el enlace completo (vecino más lejano) es satisfactoria debido a que sus grupos son diferentes, mientras que la solución del enlace simple es menos concluyente.
Nota: RCommander no permite hacer agrupación por variables.
Análisis clúster de k-medias
Análisis clúster de K-medias es una herramienta diseñada para asignar los casos a un número fijo de grupos, cuyas características no se conocen, pero se basan en un conjunto de variables que deben ser cuantitativas. Es muy útil cuando se quiere clasificar un gran número de casos.
Es un método de agrupación de casos que se basa en las distancias existentes entre ellos en un conjunto de variables cuantitativas. Este método de aglomeración no permite agrupar variables. El objetivo de optimalidad que se persigue es “maximizar la homogeneidad dentro de los grupos.”
Es el método que se usa más habitualmente, es fácil de programar y da resultados razonables. Tiene por objetivo separar las observaciones en K clúster, de manera que cada dato pertenezca a un grupo y sólo a uno. El algoritmo busca con un método iterativo:
- Los centroides (medias, medianas,… ) de los K clusters
- Asigna cada individuo a un clúster.
El algoritmo requiere que se especifique el número de conglomerados, también se puede especificar los centros iniciales de los clusters si conoce de antemano dicha información.
En este método, la medida de distancia o de similaridad entre los casos se calcula utilizando la distancia euclídea. Es muy importante el tipo de escala de las variables, si las variables tienen diferentes escalas (por ejemplo, una variable se expresa en dólares y otra en años), los resultados podrían ser equívocos. En estos casos, se debería considerar la estandarización de las variables antes de realizar el análisis de conglomerados de k-medias.
Este procedimiento supone que se ha seleccionado el número apropiado de conglomerados y que se han incluido todas las variables relevantes. Si se ha seleccionado un número inapropiado de conglomerados o se han omitido variables relevantes, los resultados podrían ser equívocos.
Existen varias formas de implementarlo pero todas ellas siguen, básicamente, los siguientes pasos:
- Paso 1. Se toman al azar k clústeres iniciales y se calculan sus centroides (medias).
- Paso 2. Se calcula la distancia euclídea de cada observación a los centroides de los clústeres y se reasigna cada observación al grupo más próximo formando los nuevos clústeres que se toman en lugar de los primeros como una mejor aproximación de los mismos.
- Paso 3. Se calculan los centroides de los nuevos clústeres.
- Paso 4. Se repiten los pasos 2) y 3) hasta que se satisfaga un criterio de parada como, por ejemplo, no se produzca ninguna reasignación, es decir, los clústeres obtenidos en dos iteraciones consecutivas son los mismos.
El método suele ser muy sensible a la solución inicial dada por lo que es conveniente utilizar una que sea buena. Una forma de construirla es mediante una clasificación obtenida por un algoritmo jerárquico.
Como ejemplo, vamos a realizar el procedimiento para el caso de dos variables \( X_1 \) y \( X_2 \) y cuatro elementos A, B, C. D. Los datos son los siguientes:
\( \begin{array} {|c|c|c|} \hline & X_1 & X_2 \\ \hline A & 6 & 3 \\ \hline B & -2 & 1 \\ \hline C & 2 & 3 \\ \hline D & -2 & -1 \\ \hline \end{array} \)
Se quiere agrupar estas observaciones en dos clústeres (k = 2)
Paso 1. De forma arbitraria se agrupan las observaciones en dos clústeres (AB) y (CD) (solución inicial) y se calculan los centroides de cada clúster.
\( \begin{array} {|ccc|} \hline & Cluster (AB) & \\ \hline \bar {x_1} & & \bar{x_2} \\ \hline (6-2)/2=2 & & (3+1)/2=2 \\ \hline \end{array} \) \( \hspace{.3cm} \begin{array} {|ccc|} \hline & Cluster (CD) & \\ \hline \bar {x_1} & & \bar{x_2} \\ \hline (2-2)/2=0 & & (3-1)/2=1 \\ \hline \end{array} \)
Paso 2. Calculamos la distancia euclídea de cada observación a los centroides de los clústeres y reasignamos cada una de estas observaciones al clúster que esté más próximo.
\( d^{2} (A,(AB)) = (6-2)^{2} + (3-2)^{2} = 17 \hspace{2 cm} d^{2} (A,(CD)) = (6-0)^{2} + (3-1)^{2} = 40 \)
Como A está más próximo al clúster (AB) que al clúster (CD), no se reasigna
\( d^{2} (B,(AB)) = (-2-2)^{2} + (1-2)^{2} = 17 \hspace{2 cm} d^{2} (B,(CD)) = (-2-0)^{2} + (1-1)^{2} = 4 \)
Como B está más próximo al clúster (CD) que al clúster (AB), se reasigna al clúster (CD) formando el clúster (BCD).
A continuación se calculan los centroides de los nuevos clusters
\( \begin{array} {|ccc|} \hline & Cluster (A) & \\ \hline \bar {x_1} & & \bar{x_2} \\ \hline 6 & & 3 \\ \hline \end{array} \) \( \hspace{.3cm} \begin{array} {|ccc|} \hline & Cluster (BCD) & \\ \hline \bar {x_1} & & \bar{x_2} \\ \hline \displaystyle \frac{-2+2-2}{3} = -0.7 & & \displaystyle \frac{1+3-1}{3}= 1\\ \hline \end{array} \)
Paso 3. Se repite el paso 2 calculando las distancias de cada observación a los centroides de los nuevos clusters para ver si se producen cambios de nuevas reasignaciones
\( \begin{array} {|c|c|c|} \hline & Cluster (A) & Cluster (BCD) \\ \hline A & 0 & (6+0.7)^{2} + (3-1)^{2} = 48.89 \\ \hline B & (-2 -6)^{2} + (1-3)^{2} = 20 & (-2+0.7)^{2} + (1-1)^{2} = 1.69 \\ \hline C & (2-6)^{2} + (3-3)^{2} = 16 & (2+0.7)^{2} + (3-1)^{2} = 11.29 \\ \hline D & (-2-6)^{2} + (-1-3)^{2}= 32 & (-2+0.7)^{2} + (-1-1.5)^{2} = 5.69\\ \hline \end{array} \)
No se produce ninguna reasignación en este último paso. Por tanto, la solución para k=2 clusters es: Clúster 1: (A) y Clúster 2: (BCD).
Existe la posibilidad de utilizar esta técnica de manera exploratoria, clasificando los casos e iterando para encontrar la ubicación de los centroides, o sólo como técnica de clasificación, clasificando los casos a partir de centroides conocidos. Cuando se utiliza como técnica exploratoria, es habitual que se desconozca el número idóneo de conglomerados, (como el ejemplo numérico que hemos hecho), por lo que es conveniente repetir el análisis con distinto número de conglomerados y comparar las soluciones obtenidas; en estos casos también se puede utilizar el método análisis de conglomerados jerárquico con una submuestra de casos.
Por último hay que interpretar la clasificación obtenida, ello requiere, en primer lugar, un conocimiento suficiente del problema analizado. Hay que estar abierto a la posibilidad de que no todos los grupos obtenidos tienen por qué ser significativos. Algunas ideas que pueden ser útiles en la interpretación de los resultados son las siguientes:
- Realizar ANOVAS y MANOVAS para ver qué grupos son significativamente distintos y en qué variables lo son.
- Realizar Análisis Discriminante.
- Realizar un Análisis Factorial o de Componentes Principales para representar gráficamente los grupos obtenidos y observar las diferencias existentes entre ellos.
- Calcular perfiles medios por grupos y compararlos.
Conviene hacer notar, finalmente, que es una técnica eminentemente exploratoria cuya finalidad es sugerir ideas al analista a la hora de elaborar hipótesis y modelos que expliquen el comportamiento de las variables analizadas identificando grupos homogéneos de objetos. Los resultados del análisis deberían tomarse como punto de partida en la elaboración de teorías que expliquen dicho comportamiento
Un buen análisis de clúster es:
- Eficiente. Utiliza el menor número de grupos posibles.
- Efectivo. Captura todas las agrupaciones estadísticamente y comercialmente importantes. Por ejemplo, un clúster con cinco clientes puede ser estadísticamente diferente, pero no es muy rentable.
Supuesto práctico 3
Utilizamos de nuevo el archivo de datos ventas_vehículos.txt que contiene estimaciones de ventas, listas de precios y especificaciones físicas de varias marcas y modelos de vehículos. Se desea hacer un estudio de mercado para poder determinar las posibles competencias para sus vehículos, para ello agrupamos las marcas de los coches según los datos disponibles, hábitos de consumo, sexo, edad, nivel de ingresos, etc. de los clientes. Las empresas de coches adaptan sus estrategias de desarrollo de productos y de marketing en función de cada grupo de consumidores para aumentar las ventas y el nivel de fidelidad a la marca.
Recordemos que el archivo de datos ventas_vehículos.txt contiene 157 datos y está formado por las siguientes variables:
- Variables tipo cadena: marca (Fabricante); modelo
- Variables tipo numérico: ventas (en miles); reventa (Valor de reventa en 4 años); tipo (Tipo de vehículo: Valores: {0, Automóvil; 1, Camión}); precio (en miles); motor (Tamaño del motor); CV (Caballos); pisada (Base de neumáticos); ancho (Anchura); largo (Longitud); peso_neto (Peso neto); depósito (Capacidad de combustible); mpg (Consumo).
Para obtener el análisis de conglomerados de K-medias, vamos al menú Estadísticos/Análisis de agrupación/Agrupación por k-medias.
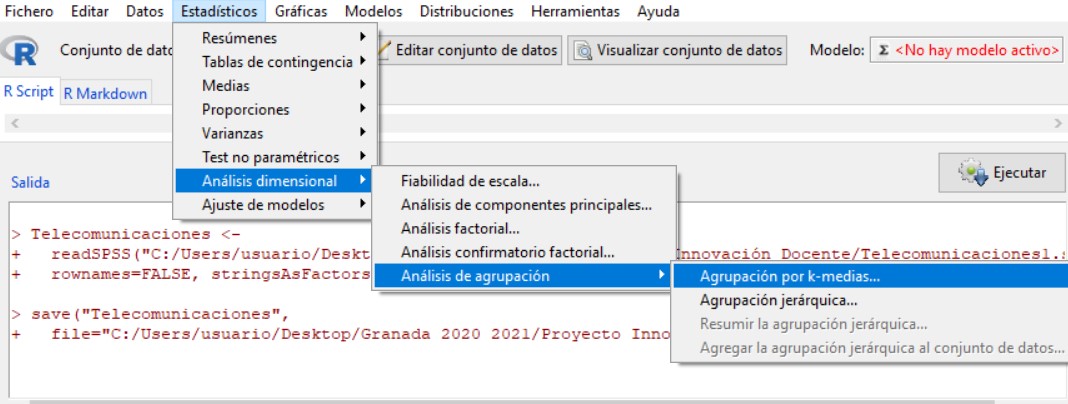
Como en el caso del Agrupación Jerárquica, en el menú Agrupación k-medias tenemos la pestaña Datos y la pestaña Opciones.
Dentro de la pestaña Datos se muestra el listado de variables cuantitativas que podemos seleccionar para diferenciar a los individuos y crear los conglomerados:
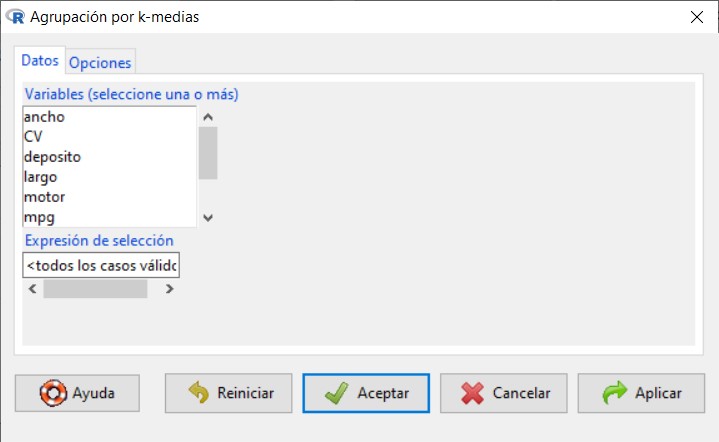
Por otro lado, en la pestaña Opciones
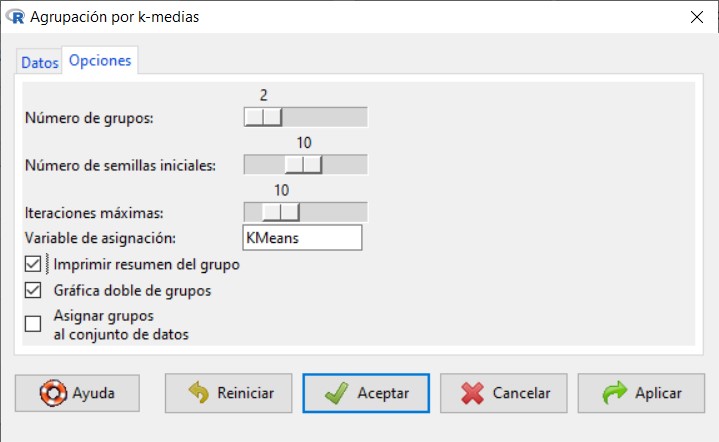
Número de grupos, que se refiere al número de Conglomerados que queremos formar, por defecto aparece 2.
Número de semillas iniciales, proporciona un número diferente de soluciones iniciales. Cada una de las soluciones iniciales resulta en una solución distinta de agrupación. Por defecto 10.
Iteraciones máximas, número máximo de iteraciones permitidas para el método. Por defecto 10.
Variable de asignación, es la variable dónde se van a guardar los resultados, por defecto aparece KMeans.
Para resolver el supuesto recordemos que:
En primer lugar cargamos el paquete R-Commander, para ello en la ventana de comandos de R se escribe la orden
> library(Rcmdr)
Una vez cargado el paquete aparecerá la siguiente pantalla
Una vez activado R Commander, pasamos a importar datos de archivo de texto
Seleccionamos en el menú principal de R-Commander: Datos/Importar datos/desde archivo de texto, portapapeles o URL…
Se muestra la siguiente pantalla
En la ventana correspondiente al nombre del conjunto de datos introducir: Auto
Pulsar Aceptar
Seleccionamos el archivo ventas_vehículos.txt
El estudio de mercado lo queremos realizar sólo en automóviles de mayor venta. Para ello, en primer lugar restringiremos el archivo de datos sólo a los automóviles de los que se vendieron al menos 100.000 unidades. Para ello, seleccionamos los casos que cumplan esa condición eligiendo en los menús Datos, Conjunto de datos activos, Filtrar el conjunto de datos activos, como se muestra en la siguiente figura:
Se selecciona Datos/Conjunto de datos activos/Filtrar el conjunto de datos activos
Para este ejemplo vamos a quedarnos con aquellos vehículos cuyas ventas superen 70.000 unidades. Recordemos que debemos a ir al menú Filtrar y en Expresión de selección ponemos: 70.000<ventas. Damos un nombre distinto a este fichero de datos para que no sobrescriba el fichero con el que estamos trabajando, como se muestra a continuación:
En primer lugar empezamos representando la distancia existente entre los casos en dos variables de interés. En este caso hemos elegido la variable peso y la variable Tamaño del motor. Para ello nos vamos al menú Gráficas, Diagrama de dispersión.
En esta opción tenemos dos pestañas, la pestaña Datos y la pestaña Opciones. En la pestaña Datos elegimos las variables con las que queremos trabajar. En este caso la variable que va en el eje de abscisas es la variable Peso, en el eje de ordenadas ponemos la variable motor.
En la pestaña Opciones podemos, entre otras cosas, dar un título al gráfico, dar una etiqueta al eje de la X y al eje de la Y, cambiar el tamaño de los puntos y el aspecto, e identificar algunos de los puntos en el gráfico. Seleccionamos la opción Identificar observaciones, Interactivamente con el ratón.
Pulsamos aceptar y obtenemos el siguiente gráfico. Hemos identificado algunos puntos presionando con el botón izquierdo del ratón sobre algunos de ellos.
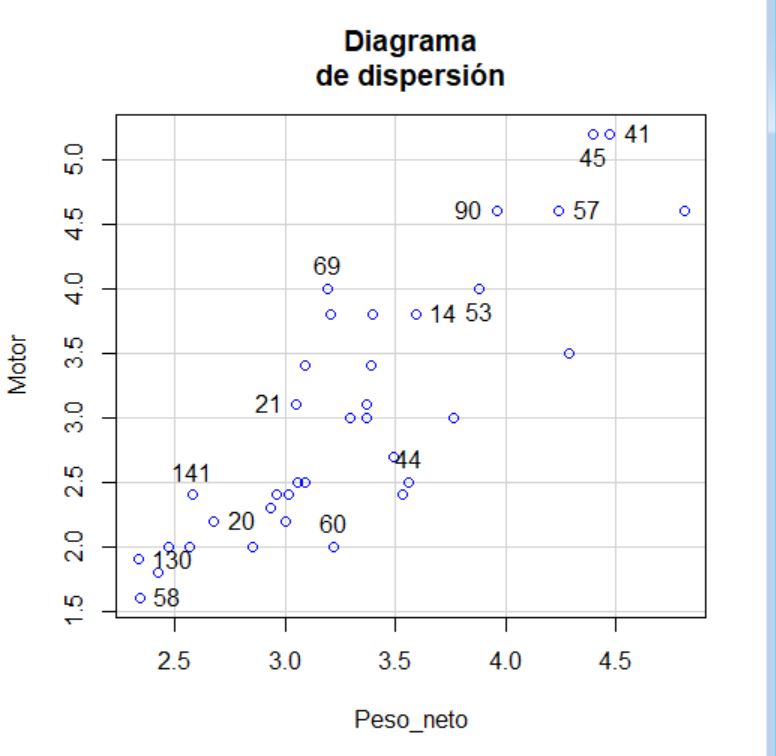
Observando el gráfico parece haber tres grupos de casos.
Procedemos ahora a la agrupación de los casos mediante el procedimiento k-medias en el menú Estadísticos/Análisis dimensional/Análisis de agrupación/ Agrupación por k-medias.
Como en el caso del Agrupación Jerárquica, en el menú Agrupación k-medias tenemos la pestaña Datos y la pestaña Opciones.
Dentro de la pestaña Datos seleccionamos las variables motor y peso_neto
En la pestaña Opciones, en Número de grupos, ponemos 3, para que cree 3 clústeres. Dejamos las opciones por defecto en Número de semillas iniciales e Iteraciones máximas. Seleccionamos las opciones Imprimir resumen del grupo y Asignar grupos al conjunto de datos.
Pulsamos aceptar y obtenemos la siguiente salida
Tamaño de los clústeres
> .cluster$size # Cluster Sizes
[1] 5 18 15
En este caso podemos ver el número de sujetos que componen cada clúster. El primero contiene 5 vehículos, que corresponden con los que se identificaron en el diagrama de dispersión como más alejados del resto. El segundo contiene 18 vehículos, los cuales están en el grupo que había al principio del diagrama de dispersión. Finalmente, el tercer clúster está compuesto por 15 vehículos, los que se encuentran en el centro del diagrama.
Además, tenemos, la suma de cuadrados dentro de cada clúster, y el total de esa suma, y la suma de cuadrados entre clústeres (distancias euclídeas).
> .cluster$withinss # Within Cluster Sum of Squares
[1] 0.8207168 3.6282282 4.3258496
> .cluster$tot.withinss # Total Within Sum of Squares
[1] 8.774795
> .cluster$betweenss # Between Cluster Sum of Squares
[1] 42.19316
> .cluster$centers # Cluster Centroids
new.x.motor new.x.peso_neto
1 4.840000 4.374200
2 2.172222 2.841778
3 3.440000 3.482600
Esta tabla nos sirve para interpretar los conglomerados pues resume los valores centrales de cada conglomerado en las variables de interés. La interpretación de los resultados de nuestro ejemplo es simple: el primer conglomerado está constituido por los vehículos de gran tamaño de motor y mayor peso, mientras el segundo conglomerado está constituido por vehículos de tamaño de motor reducido y poco peso, finalmente, el tercer conglomerado contiene los vehículos de tamaño de motor y peso moderado.
Finalmente, si visualizamos el conjunto de datos podemos ver que clúster se le ha asignado a cada vehículo.
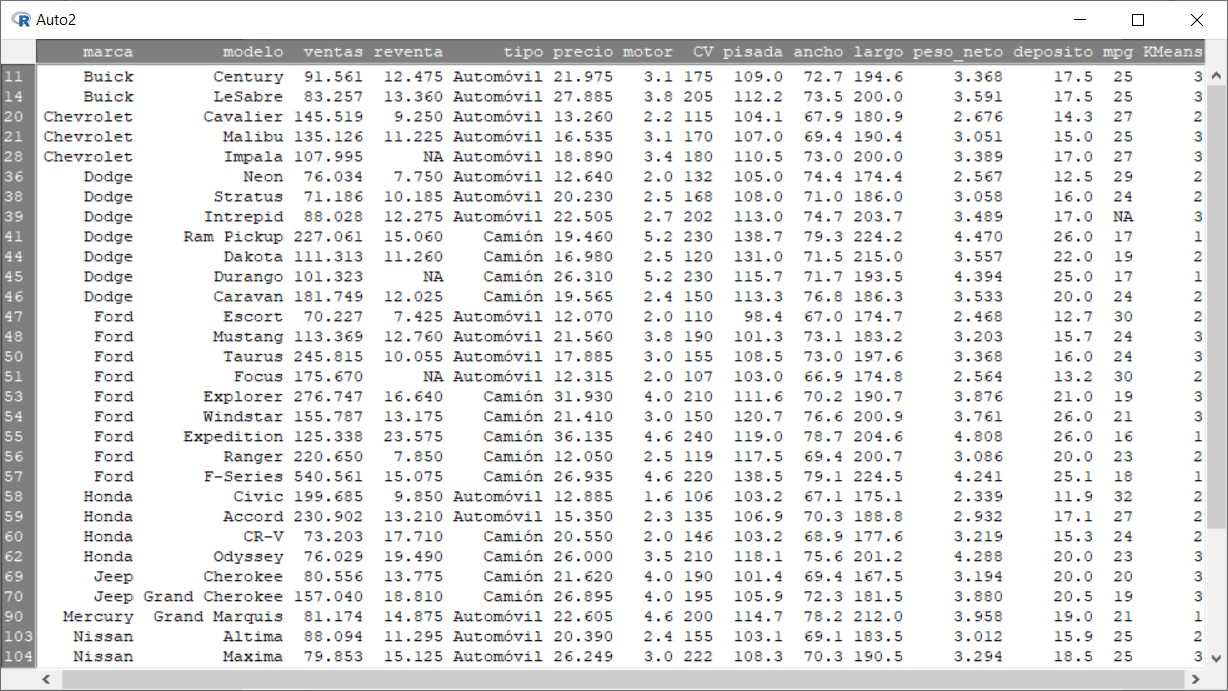
Por ejemplo, los sujetos 41 y 45 están asignados al clúster 1, dónde están los vehículos más pesados y con mayor motor. Las observaciones 47 y 59 están el clúster 2, de vehículos más pequeños. Finalmente, los sujetos 14 y 48 están asignados al clúster 3, correspondiente a un tamaño moderado. Todo esto se corresponde con lo visto en el diagrama de dispersión.
Supuesto práctico 4
Para este ejemplo utilizaremos el archivo telecomunicaciones.txt sobre una compañía de telecomunicaciones que realiza un estudio con el fin de reducir el abandono de sus clientes.
El archivo de datos telecomunicaciones.txt contiene 1000 datos y está formado por las siguientes variables: región, permanencia, edad, estado_civil, dirección, ingresos_familiares, nivel_educativo, empleo, género, n-pers_hogar, llamadas_gratuitas, alquiler_equipo, tarjeta_llamada, inalámbrico, larga_distancia_mes, llamadas_gratuitas_mes, equipo_mes, tarjeta_mes, inalámbrico_mes, líneas_múltiples, mensaje_voz, servicio_busca, internet, identificador_llamada, desvío_llamadas, llamada_a_tres, facturación_electrónica.
Es conveniente unificar la escala de las variables con las que vamos a trabajar, por ello vamos a transformar mediante logaritmo neperiano y tipificación las variables: larga_distancia_mes, llamadas_gratuitas_mes, equipo_mes, tarjeta_mes, inalámbrico_mes,
> library(Rcmdr)
En primer lugar importamos el archivo de datos: Datos/Importar datos/desde archivo de texto, portapapeles o URL…
Antes de transformar los datos, vamos a eliminar los valores perdidos, hay muchos valores perdidos debido al hecho de que la mayoría de los clientes no se suscriben a todos los servicios. Por lo tanto hay que seleccionar los casos que han solicitado los servicios, por ejemplo: llamada_gratuitas, alquiler_equipo, tarjeta_llamada e Inhalámbrico.
Para ello, hay que filtrar los datos:
Datos/ Conjunto de datos activo/ Filtrar el conjunto de datos activo.
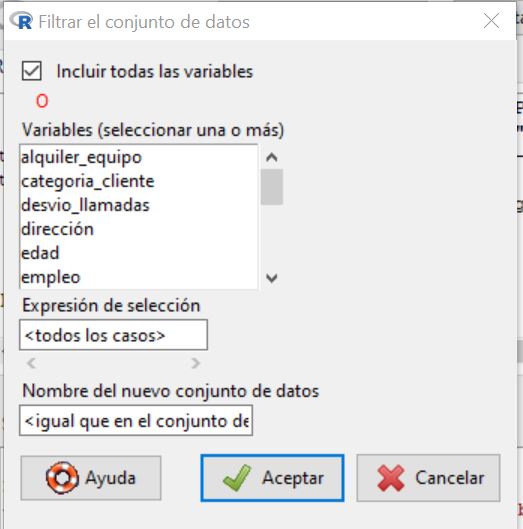
En Expresión de selección, escribir las variables que desea seleccionar, en este ejercicio lo escribimos de la siguiente manera: llamada_gratuitas==”Sí”&alquiler_equipo==”Sí”&tarjeta_llamada==”Sí”&Inhalámbrico==”Sí” y en el recuadro del Nombre del nuevo conjunto de datos, escribir Telecomunicaciones2.RData. Los datos se han filtrado porque la mayoría de los clientes no se suscriben a todos los servicios.
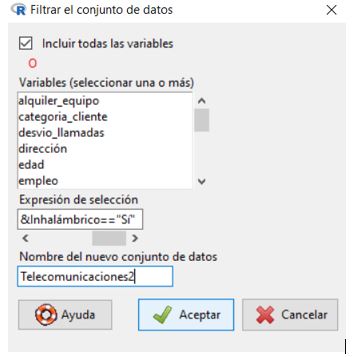
Nombre del nuevo conjunto de datos: telecomunicaciones2
En el archivo de datos datos telecomunicaciones2.RData: Transformar mediante logaritmo neperiano y tipificación las siguientes variables: larga_distancia_mes, llamadas_gratuitas_mes, equipos_mes, tarjetas_mes, inalámbrico_mes
Para ello nos vamos al menú Datos/Modificar variables del conjunto de datos activo/Calcular una nueva variable.
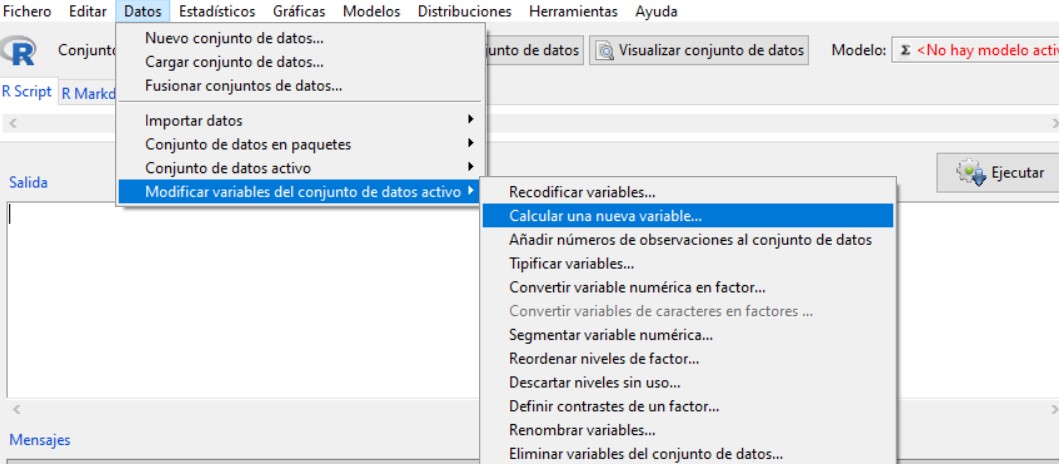
En el menú Calcular una nueva variable, hacemos doble clic sobre la variable larga_distancia_mes y se coloca en Expresión a calcular. A continuación le pedimos que haga el logaritmo neperiano de esta variable log(larga_distancia_mes). Le damos un nombre a esta variable que vamos a crear Ln_larga_distancia_mes.
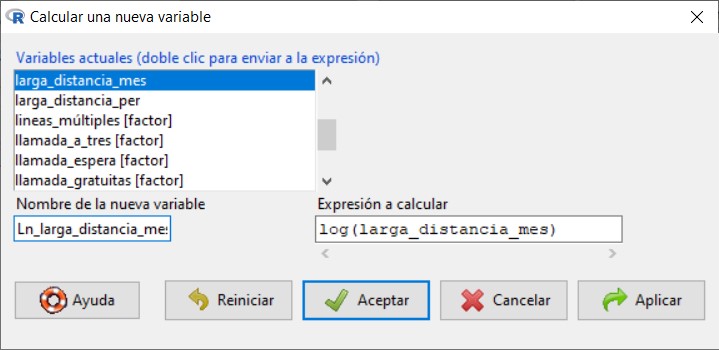
Pulsamos aceptar, si visualizamos el conjunto de datos vemos que se ha añadido una variable al final que que contiene los logaritmos neperianos de la variable larga_distancia_mes.
A continuación tipificamos los valores de esta variable. En este caso nos vamos de nuevo al menú Datos, Modificar variables del conjunto de datos activo, Tipificar variables.
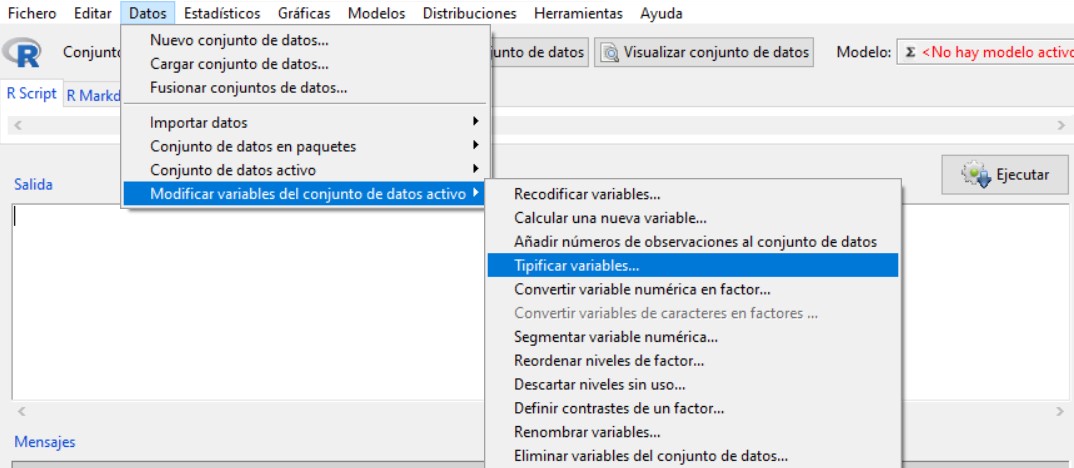
En Tipificar variables, seleccionamos la variable que acabamos de crear (Ln_larga_distancia_mes) y pulsamos Aceptar:
Si visualizamos el conjunto de datos vemos que se ha creado al final una nueva variable llamada Z.Ln_larga_distancia_mes, que contiene los valores tipificados de la variable Ln_larga_distancia_mes.
Realizamos lss mismas transformaciones con las variables: llamadas_gratuitas_mes, equipos_mes, tarjetas_mes, inalámbrico_mes
- Transformar mediante logaritmo neperiano y tipificación las siguientes variables: llamadas_gratuitas_mes, equipos_mes, tarjetas_mes, inalámbrico_mes
- Transformar mediante tipificación las siguientes variables: llamadas_gratuitas_mes, equipos_mes, tarjetas_mes, inalámbrico_mes
Para ello nos vamos al menú Datos/Modificar variables del conjunto de datos activo/Calcular una nueva variable
y a continuación: Datos/Modificar variables del conjunto de datos activo/Tipificar variables.
Comenzamos ahora a trabajar con el procedimiento k-medias.
Estadísticos/Análisis dimensional/Análisis de agrupación/Agrupación por K-medias…, en la pestaña Datos seleccionamos las variables: zln_larga_distancia, zln_llamadas_gratuitas, zln_equipos, zln_tarjetas, zln_inalámbrico, z_lineas_múltiples, z_internet.
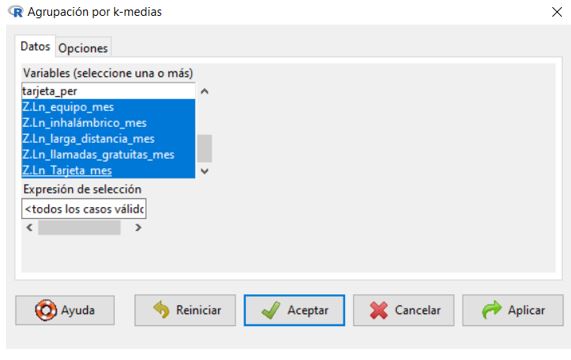
En la pestaña Opciones, especificar el Número de grupos: 3, este número no debe ser inferior a 2 ni superior al número de casos del archivo de datos. El comando de análisis de conglomerados de k-medias es eficaz principalmente porque no calcula las distancias entre todos los pares de casos, como hacen muchos algoritmos de conglomeración, como el utilizado por el comando de conglomeración jerárquica.
Ponemos como Iteraciones máximas: 20. Seleccionamos Imprimir resumen del grupo y Asignar grupos al conjunto de datos. Pulsamos aceptar.
Las salidas se muestran a continuación:
En primer lugar, el tamaño de los clústeres. Podemos observar que se han eliminado bastantes observaciones del archivo, nos hemos quedado sólo con los individuos que contratan estos servicios.
> .cluster$size # Cluster Sizes
[1] 34 50 47
A continuación tenemos los centroides de los clústeres para cada una de las variables:
> .cluster$centers # Cluster Centroids
new.x.Z.Ln_equipo_mes new.x.Z.Ln_inhalámbrico_mes new.x.Z.Ln_larga_distancia_mes new.x.Z.Ln_llamadas_gratuitas_mes new.x.Z.Ln_Tarjeta_mes
1 0.2438307 0.1670959 -0.01502926 -0.3649923 -0.92629016
2 -0.7974119 -0.8957319 -0.67495787 -0.5737591 0.01325833
3 0.6719224 0.8320284 0.72891252 0.8744190 0.65597764
Los centros de los conglomerados finales reflejan las características del caso típico de cada clúster:
- Los clientes del conglomerado 1 tienden a gastar poco, sólo compran los servicios de equipo y de inhalámbrico.
- Los clientes del conglomerado 2 tienden a gastar menos, comprado menos servicios de los mencionados, excepto la tarjeta de llamadas
- Los clientes del conglomerado 3 tienden a ser grandes consumidores que compran una gran cantidad de estos servicios.
Finalmente, tenemos las distancias euclídeas dentro de cada clúster y entre clústeres.
> .cluster$withinss # Within Cluster Sum of Squares
[1] 90.75613 120.93148 155.58579
> .cluster$tot.withinss # Total Within Sum of Squares
[1] 367.2734
> .cluster$betweenss # Between Cluster Sum of Squares
[1] 282.7266
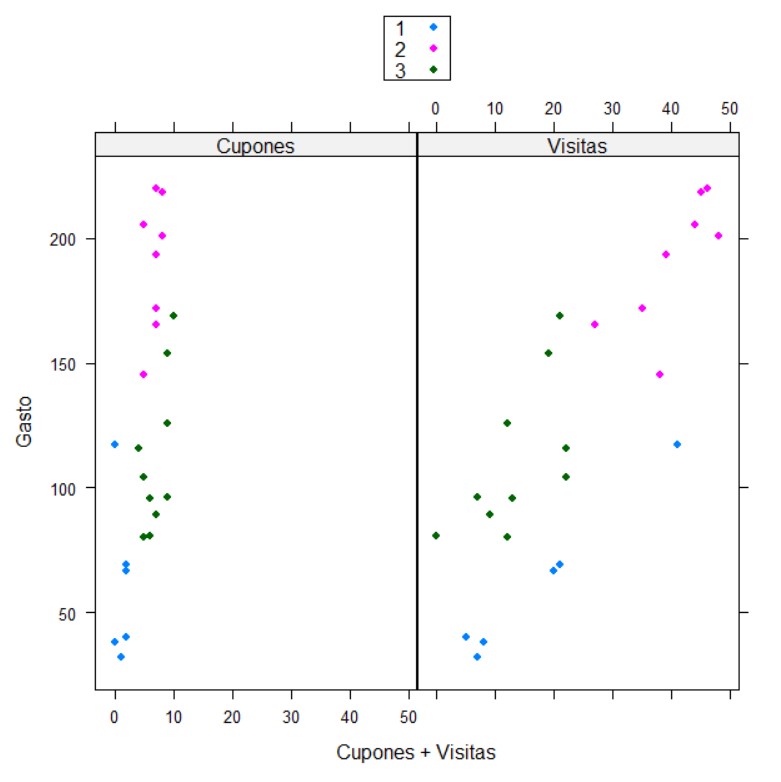
A continuación, vamos a dibujar un diagrama de dispersión dónde veamos cómo se comportan estos grupos en dos de estas variables, las variables inhalámbrico_mes y llamadas_gratuitas_mes. Para ello nos vamos al menú Diagrama de dispersión, y el la pestaña datos señalamos estas dos variables.
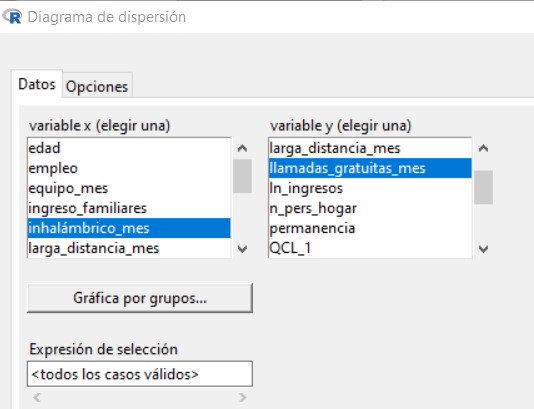
En la opción Gráfica por grupos…, seleccionamos KMeans donde le pedimos que haga la gráfica según los grupos proporcionados por KMeans.
Pulsamos Aceptar
En la pestaña opciones vamos a simplemente darle un título al gráfico y etiquetas a los ejes de la X y de la Y. Pulsamos Aceptar
Pulsamos Aceptar y se muestra el siguiente gráfico de dispersión
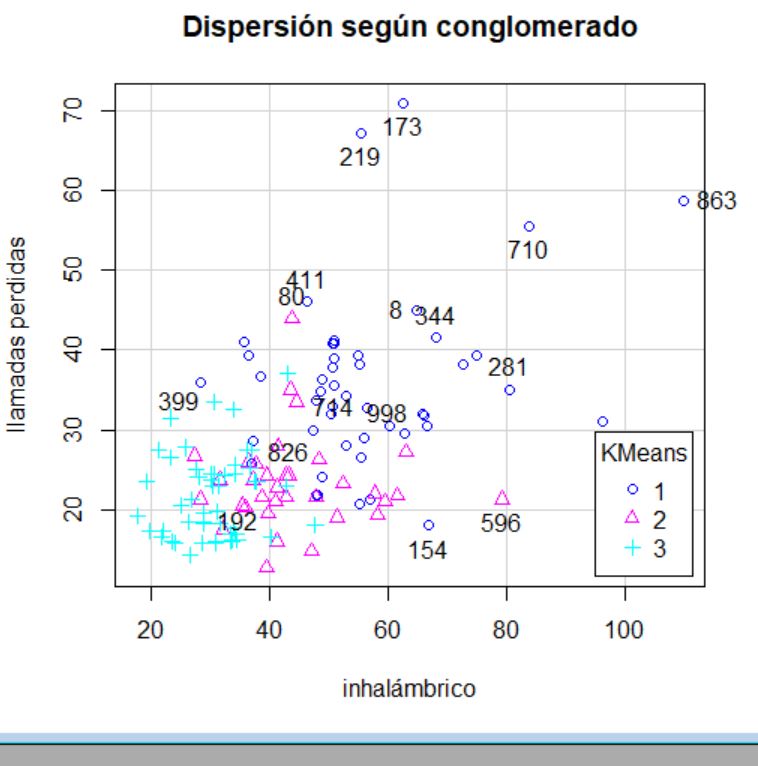
En este diagrama de dispersión no se puede observar muy bien las diferencias entre los clústeres. Al inicio se mezclan el clúster 2 y el 3 y en el centro el clúster 1 y 3, por lo que no parece que esta agrupación sea eficiente.
Probamos a formar 2 clústeres repitiendo el proceso.
Supuesto práctico 5
Vamos a repetir el análisis pero ahora con dos clústeres.
Estadísticos/Análisis dimensional/Análisis de agrupación/Agrupación por K-medias…, en la pestaña Datos seleccionamos las variables: zln_larga_distancia, zln_llamadas_gratuitas, zln_equipos, zln_tarjetas, zln_inalámbrico, z_lineas_múltiples, z_internet.
En la pestaña Opciones, especificar el Número de grupos: 2, este número no debe ser inferior a 2 ni superior al número de casos del archivo de datos. El comando de análisis de conglomerados de k-medias es eficaz principalmente porque no calcula las distancias entre todos los pares de casos, como hacen muchos algoritmos de conglomeración, como el utilizado por el comando de conglomeración jerárquica.
Ponemos como Iteraciones máximas: 20. Seleccionamos Imprimir resumen del grupo y Asignar grupos al conjunto de datos. Pulsamos aceptar.
Variable de asignación: KMeans1
Las salidas se muestran a continuación:
> .cluster$size # Cluster Sizes
[1] 56 75
Después tenemos los centroides de los clústeres para cada una de las variables:
> .cluster$centers # Cluster Centroids
new.x.Z.Ln_equipo_mes new.x.Z.Ln_inhalámbrico_mes new.x.Z.Ln_larga_distancia_mes new.x.Z.Ln_llamadas_gratuitas_mes
1 0.8094595 0.8361704 0.6059714 0.7162295
2 -0.6043964 -0.6243405 -0.4524587 -0.5347847
new.x.Z.Ln_Tarjeta_mes
1 0.3601533
2 -0.2689144
Los centros de los conglomerados finales reflejan las características del caso típico de cada clúster:
- Los clientes del conglomerado 1 tienden a ser grandes consumidores que compran una gran cantidad de estos servicios.
- Los clientes del conglomerado 2 tienden a gastar menos de los servicios comprados.
Finalmente, tenemos las distancias euclídeas dentro de cada clúster y entre clústeres.
> .cluster$withinss # Within Cluster Sum of Squares
[1] 204.3398 214.4000
> .cluster$tot.withinss # Total Within Sum of Squares
[1] 418.7397
> .cluster$betweenss # Between Cluster Sum of Squares
[1] 231.2603
Por último, vamos a dibujar un diagrama de dispersión dónde veamos cómo se comportan estos grupos en dos de estas variables, las variables inhalámbrico_mes y llamadas_gratuitas_mes. Para ello nos vamos al menú Diagrama de dispersión, y el la pestaña datos señalamos estas dos variables.
Pulsamos Gráfica por grupos… y seleccionamos KMeans1. Pulsamos Aceptar
En la pestaña Opciones seleccionamos:
Pulsamos Aceptar y se muestra la siguiente gráfica
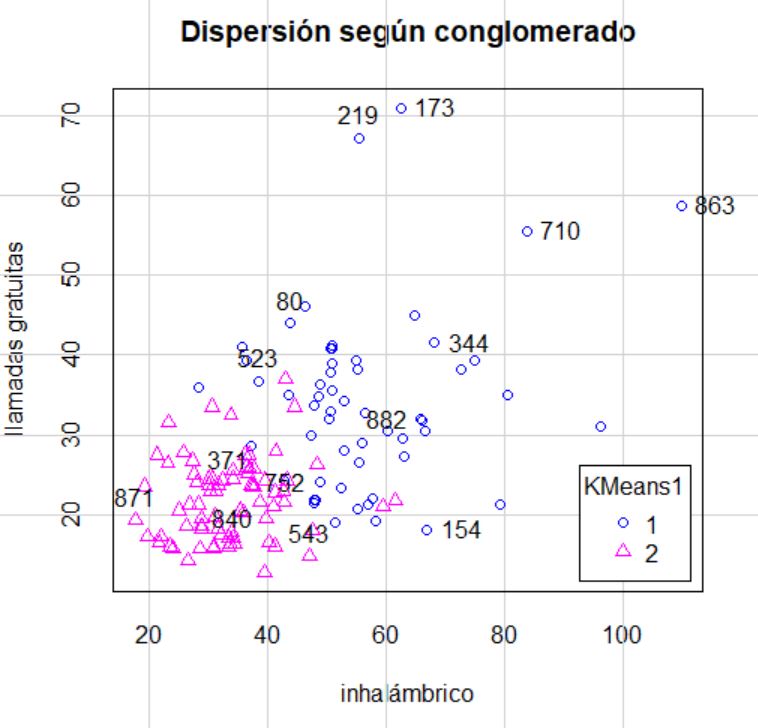
En este diagrama de dispersión se puede observar las diferencias entre los clústeres, aunque se mezclan algunos en cierta zona del gráfico, pero en su mayoría hay una clara separación entre los grupos.
Ejercicios
Ejercicios Guiados
Ejercicios Propuestos
Ejercicios Guiados
Ejercicio Guiado 1 (Clasificación de países de la UE con datos binarios)
Los datos corresponden a la situación de 6 países europeos en 1996 con respecto a los 4 criterios exigidos por la UE para entrar en la Unión Monetaria: Inflación, Interés, Déficit Público y Deuda Pública y vienen dados en la tabla siguiente:
\( \begin{array} {|c|c|c|c|c|} \hline Pais & Inflacion & Interes & Deficit & Deuda \\ \hline Alemania & 1 & 1 & 1 & 0 \\ \hline España & 1 & 1 & 1 & 0 \\ \hline Francia & 1 & 1 & 1 & 1 \\ \hline Grecia & 0 & 0 & 0 & 0 \\ \hline Italia & 1 & 1 & 0 & 0 \\ \hline Reino \hspace{.2cm} Unido & 1 & 1 & 0 & 1 \\ \hline \end{array} \)
El objetivo es encontrar grupos de países que muestren un comportamiento similar con respecto a las variables analizadas.
Este es un ejemplo en el que todas las variables son binarias de forma que, 1 significa que el país sí satisfacía el criterio exigido y 0 que no lo satisfacía.
En este caso todas las variables son binarias simétricas y se puede utilizar como medida de distancia la distancia euclídea al cuadrado.
Se pide:
- La matriz de distancias e interpretación de la misma.
- Utilizar un análisis de conglomerados jerárquico aglomerativo con enlace completo para clasificar los países de la UE según las variables Inflación, Interés, Déficit Público y Deuda Pública, con el objetivo de encontrar grupo de países con comportamiento similares.
Ejercicio Guiado 2
Se desea determinar los segmentos de mercado de un determinado producto en una ciudad pequeña basándose únicamente en la lealtad a las marcas y la lealtad a las tiendas. Para ello se selecciona una muestra de 10 encuestados sobre los que se miden las dos variables lealtad a la tienda (tienda) y lealtad a la marca (marca) en una escala de 0 a 10. Los datos se muestran en la siguiente tabla:
\( \begin{array} {|c|c|c|c|c|c|c|c|c|c|c|} \hline Variable & A & B & C & D & E & F & G & H & I & J \\ \hline Tienda & 2 & 5 & 3 & 4 & 6 & 9 & 8 & 7 & 4 & 5 \\ \hline Marca & 2 & 9 & 5 & 8 & 7 & 3 & 4 & 5 & 6 & 7 \\ \hline \end{array} \)
Se pide:
- Realizar un diagrama de dispersión y estudiar los grupos más homogéneos
- Realizar un análisis de conglomerados con distintos métodos y comparar.
Ejercicio Guiado 3
El archivo de datos jóvenes.RData contiene información sobre 14 jóvenes respecto a su edad, estudios, hábitos de lectura, fútbol, cine, teatro, concierto, tv, ámbito familiar…
Se desea clasificar a los 14 jóvenes encuestados por el número de veces que van anualmente al fútbol (fútbol), la paga semanal que reciben (paga) y el número de horas semanales que ven la televisión (tv)
Se pide:
- Realizar un diagrama de dispersión 3-D para mostrar la distribución de los datos y estudiar los posibles grupos que se pueden hacer.
- Utilizar un análisis clúster jerárquico. (Etiquetar los casos mediante Identificación personal, id )
- Método: Vecino más lejano; Medida: Intervalo- Distancia euclídea al cuadrado; Transformar valores: Estandarizar las variables (puntuaciones Z)
- Obtener la Matriz de distancia y el Dendograma
- Analizar las tablas obtenidas y sacar conclusiones
- Repetir el proceso anterior con el Método de Ward
- Repetir el proceso anterior con el Método de Conglomeración: Agrupación de medianas
- Obtener conclusiones ¿Nº de clústeres? ¿Método de conglomeración?
- Realizar un análisis clúster de K medias y comparar las clasificaciones
Nota: Para realizar el apartado 1.
- Seleccionar en el menú principal Gráficas/Gráficos 3D/Diagrama de dispersión en 3D
- Variables explicativas: paga y futbol; Variable explicada: tv
- Pestaña Opciones: Identificar Observaciones Interactivamente con el ratón
El archivo de datos jóvenes.RData contiene 14 datos y está formado por las siguientes variables:
- Variables tipo cadena: id (Identificación personal)
- Variables tipo numérico: centro (Tipo de centro de estudios {1, público}…), estudios (Estudios que cursa {1, EGB}…); estupadr (Estudios del padre {1, Sin estudios}…); estumadr (Estudios de la madre {1, Sin estudios}..); paga (Paga semanal en ptas/100); numher (Nº hermanos incluido sujeto); edad ; califest (Calificación media en estudios); lect ( Libros leídos anualmente); cine (Asistencia anual al cine); fútbol (Asistencia anual al futbol); conciert (Asistencia anual conciertos); tv (Horas semanales tv); sexo ({1, hombre}…); hábitat ({1, rural}…); lectp (Segunda tasa de lectura); univ (¿Deseas acceder a la universidad? {1, sí}…); gustcine (Te gusta ir al cine… {1, solo}…); tipocine (Tipo de película que te gusta {1, amor}…); violen (Nivel de rechazo a la violencia {1, activo}…); impdin (Importancia das al dinero {1, muy poca}..); impest (Importancia de estudios {1, muy poca}…); ingr (Ingresos mensuales {1, <100}…); físico (Importancia al físico {1, muy poca}…); depor (interés deporte {1,muy poca}…).
Ejercicio Guiado 4
Utilizamos de nuevo el archivo de datos ventas_vehículos.RData que contiene estimaciones de ventas, listas de precios y especificaciones físicas hipotéticas de varias marcas y modelos de vehículos. Se desea hacer un estudio de mercado para poder determinar las posibles competencias para sus vehículos, para ello agrupamos las marcas de los coches según los datos disponibles, hábitos de consumo, sexo, edad, nivel de ingresos, etc. de los clientes. Las empresas de coches adaptan sus estrategias de desarrollo de productos y de marketing en función de cada grupo de consumidores para aumentar las ventas y el nivel de fidelidad a la marca.
Se pide: seleccionar los vehículos cuyo precio de reventa ha sido inferior a 12.000€. Considerando las variables de interés peso neto y tamaño del motor, repetir el análisis hecho en el supuesto práctico 5, obtener el diagrama de dispersión y decidir cuántos clústeres debemos considerar. Analizar los resultados aplicando el método de k-medias.
Nota: El archivo de datos ventas_vehículos.RData contiene 157 datos y está formado por las siguientes variables:
Variables tipo cadena: marca (Fabricante); modelo
Variables tipo numérico: ventas (en miles); reventa (Valor de reventa en 4 años); tipo (Tipo de vehículo: Valores: {0, Automóvil; 1, Camión}); precio (en miles); motor (Tamaño del motor); CV (Caballos); pisada (Base de neumáticos); ancho (Anchura); largo (Longitud); peso_neto (Peso neto); depósito (Capacidad de combustible); mpg (Consumo).
Ejercicio Guiado 5
Vamos a utilizar de nuevo el archivo de datos jóvenes.RData que contiene información sobre 14 jóvenes.
Se pide:
- Tipificar las variables fútbol, paga y tv
- Realizar un análisis de conglomerados de k-medias con tres conglomerados según las variables tipificadas fútbol, paga y tv (Zpaga, Zfútbol y Ztv)
- Resumir los resultados obtenidos e interpretar la solución.
Ejercicio Guiado 1 (Resuelto)
Los datos corresponden a la situación de 6 países europeos en 1996 con respecto a los 4 criterios exigidos por la UE para entrar en la Unión Monetaria: Inflación, Interés, Déficit Público y Deuda Pública y vienen dados en la tabla siguiente:
\( \begin{array} {|c|c|c|c|c|} \hline Pais & Inflacion & Interes & Deficit & Deuda \\ \hline Alemania & 1 & 1 & 1 & 0 \\ \hline España & 1 & 1 & 1 & 0 \\ \hline Francia & 1 & 1 & 1 & 1 \\ \hline Grecia & 0 & 0 & 0 & 0 \\ \hline Italia & 1 & 1 & 0 & 0 \\ \hline Reino \hspace{.2cm} Unido & 1 & 1 & 0 & 1 \\ \hline \end{array} \)
El objetivo es encontrar grupos de países que muestren un comportamiento similar con respecto a las variables analizadas.
Este es un ejemplo en el que todas las variables son binarias de forma que, 1 significa que el país sí satisfacía el criterio exigido y 0 que no lo satisfacía.
En este caso todas las variables son binarias simétricas y se puede utilizar como medida de distancia la distancia euclídea al cuadrado.
Se pide:
- La matriz de distancias e interpretación de la misma.
- Utilizar un análisis de conglomerados jerárquico aglomerativo con enlace completo para clasificar los países de la UE según las variables Inflación, Interés, Déficit Público y Deuda Pública, con el objetivo de encontrar grupo de países con comportamiento similares.
Solución
- La matriz de distancias e interpretación de la misma:
\( \begin{array} {|c|c|c|c|c|c|c|} \hline Pais & Alemania & España & Francia & Grecia & Italia & Reino \hspace{.2cm} Unido \\ \hline Alemania & 0 & 0& 1 & 3 & 1 & 2 \\ \hline España & 0 & 0 & 1 &3 & 1 & 2 \\ \hline Francia & 1 & 1 & 0 & 4 & 2 & 1 \\ \hline Grecia & 3 & 3 & 4 & 0 & 2 & 3 \\ \hline Italia & 1 & 1 & 2 & 2 & 0 & 1 \\ \hline Reino \hspace{.2cm} Unido & 2 & 2 & 1 & 3 & 1 & 0 \\ \hline \end{array} \)
Observando la tabla podemos ver por ejemplo que:
- la distancia entre España y Francia es 1 puesto que solamente difieren en un criterio: el de la deuda pública que Francia satisfacía y España no.
- la distancia entre Alemania y Grecia es 3 puesto que difieren en tres criterios: el de Inflación, Interés y Déficit que Alemanía no los satisface y Grecia si.
2. Utilizar un análisis de conglomerados jerárquico aglomerativo con enlace completo para clasificar los países de la UE según las variables Inflación, Interés, Déficit Público y Deuda Pública, con el objetivo de encontrar grupo de países con comportamiento similares.
Seleccionar en el menú principal: Datos/Importar datos/desde un archivo de Excel. En la ventana resultante introducimos el nombre del conjunto de dados. En nuestro caso: Paises
Pulsamos Aceptar y elegimos el archivo de datos paises.xlsx

¿Qué grupos de países tienen comportamientos similares?, ¿cuántos clústeres deberíamos coger?.
Seleccionamos en el menú principal: Estadísticos, Análisis dimensional, análisis de agrupación, Agrupación jerárquica
Dentro del menú Agrupación jerárquica, seleccionamos todas las variables en Datos
y en Opciones, seleccionamos en Método de agrupación, Método de Ward y en Medida de la distancia, Euclídea. Por defecto, está seleccionado Dibujar dendograma
Al pulsar Aceptar se obtiene el siguiente dendograma
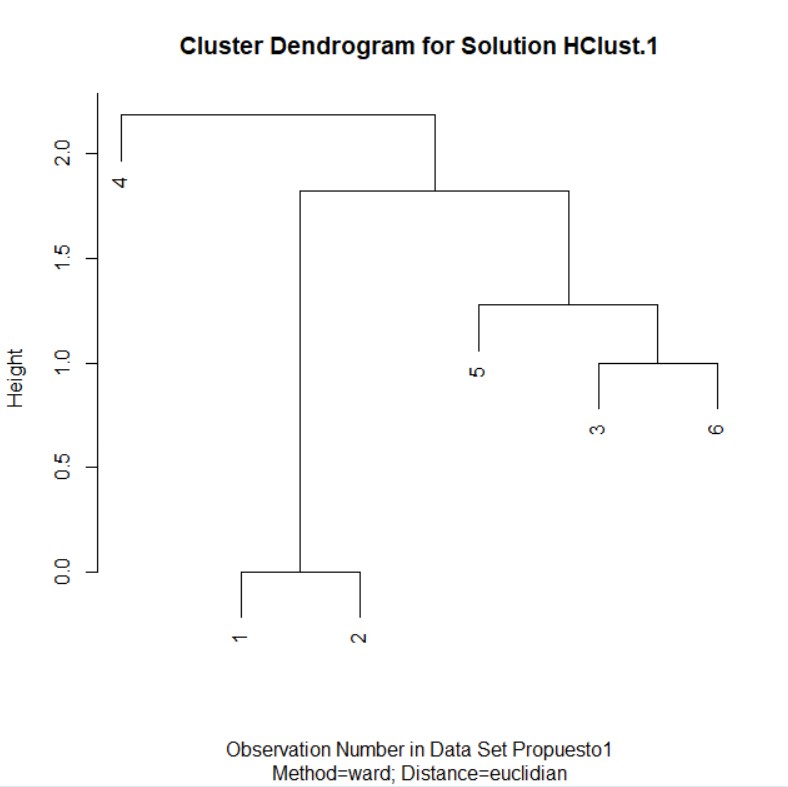
Analizando este dendograma podemos ver:
- La división inicial del árbol forma dos grupos, (1, 2, 3, 6, 5) y (4). El clúster primero contiene los países que satisfacía algunos de los criterios exigidos por la UE y el segundo contiene el país que no satisface ninguno de los criterios para entrar a la Unión Monetaria.
- El grupo de países que satisfacía algunos de los criterios exigidos por la UE se puede dividir en dos subgrupos. El 1er subgrupo formado por los países que satisfacían 3 criterios. Inflación, Interés y Déficit que son Alemania (1) y España (2) pero no satisfacía el criterio Deuda. En el 2do subgrupo, están los países Francia (3), Italia (5) y Reino Unido (6) que satisfacía todos o algunos de los criterios. Por último, el 3er grupo es el país de Grecia (4) que no satisfacía ningún criterio para entrar a la Unión Monetaria.
¿Qué grupos de países tienen comportamientos similares?,
- El 1er subgrupo formado por los países que satisfacía 3 criterios. Inflación, Interés y Déficit que son Alemania (1) y España (2).
- En el 2do subgrupo, están los países Francia (3), Italia (5) y Reino Unido (6) que satisfacía todos o algunos de los criterios.
- El 3er grupo es el país de Grecia (4) que no satisfacía ningún criterio para entrar a la Unión Monetaria.
¿cuántos clústeres deberíamos coger? Se debe considerar 3 clúster.
Ejercicio Guiado 2 (Resuelto)
Se desea determinar los segmentos de mercado de un determinado producto en una ciudad pequeña basándose únicamente en la lealtad a las marcas y la lealtad a las tiendas. Para ello se selecciona una muestra de 10 encuestados sobre los que se miden las dos variables lealtad a la tienda (tienda) y lealtad a la marca (marca) en una escala de 0 a 10. Los datos se muestran en la siguiente tabla:
\( \begin{array} {|c|c|c|c|c|c|c|c|c|c|c|} \hline Variable & A & B & C & D & E & F & G & H & I & J \\ \hline Tienda & 2 & 5 & 3 & 4 & 6 & 9 & 8 & 7 & 4 & 5 \\ \hline Marca & 2 & 9 & 5 & 8 & 7 & 3 & 4 & 5 & 6 & 7 \\ \hline \end{array} \)
Se pide:
- Realizar un diagrama de dispersión y estudiar los grupos más homogéneos
- Realizar un análisis de conglomerados con distintos métodos y comparar.
Solución
- Realizar un diagrama de dispersión y estudiar los grupos más homogéneos
> library(Rcmdr)
En primer lugar importamos el archivo de datos: Datos/Importar datos/desde archivo de texto, portapapeles o URL…

Pulsamos Aceptar y seleccionamos el fichero de datos: Mercado.xlsx
Nota: Cuando cargue la matriz de datos en formato txt o Excel. Se tiene que establecer el nombre de los casos con la variable que desea etiquetar en el diagrama de dispersión. Vamos a la opción Datos, seleccionamos Conjunto de datos activo y Establecer nombre de casos
En esta ventana seleccionamos la variable para especificar como etiquetas de los casos. Pulsar Aceptar
A continuación realizamos un diagrama de dispersión en la opción Gráficas seleccionar Diagrama de Dispersión
En la pestaña de Datos se va a seleccionar las variables. En este ejercicio, seleccionamos la variable Tienda como variable x y Marca para la variable y
En Opciones escribimos el nombre de la variable para cada etiqueta y el título del gráfico. En identificar Observaciones, seleccionamos interactivamente con el ratón, para identificar las etiquetas de cada punto.
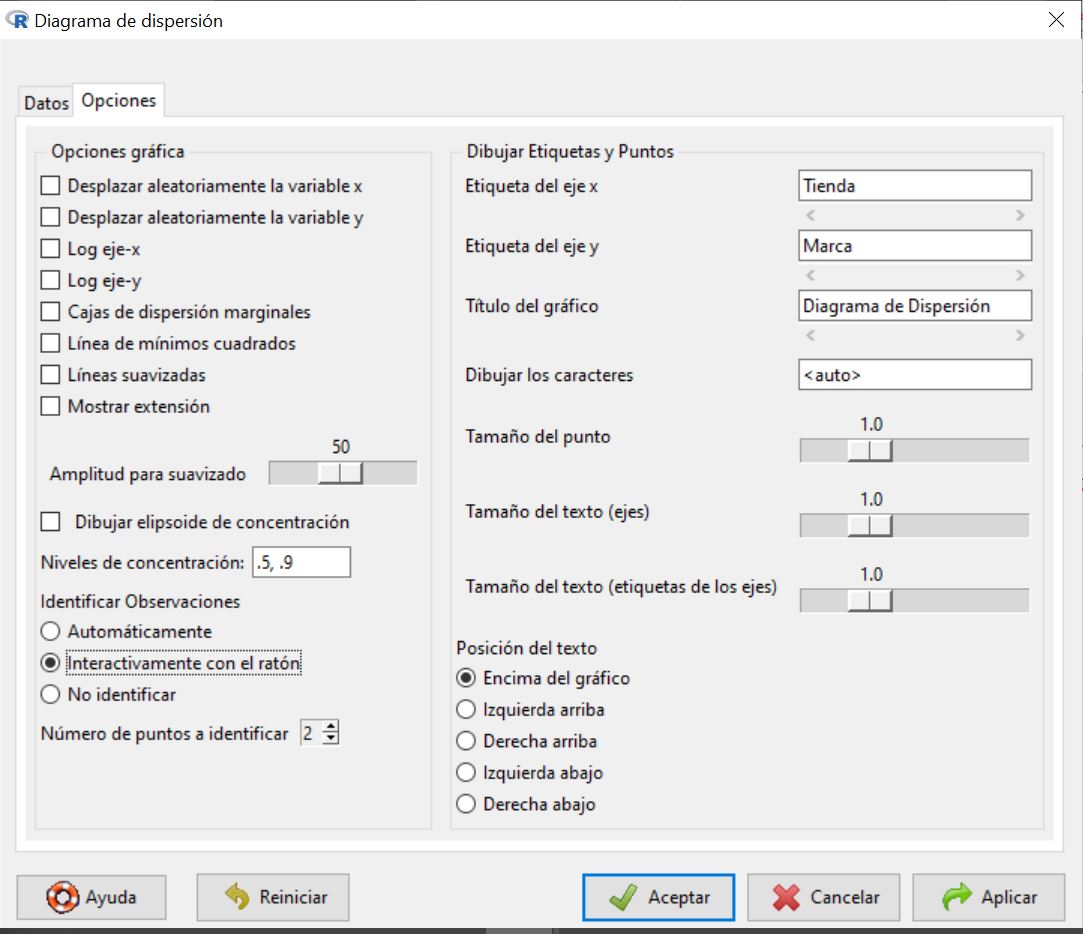
Pulsar Aceptar y se muestra el siguiente gráfico de Diagrama de Dispersión
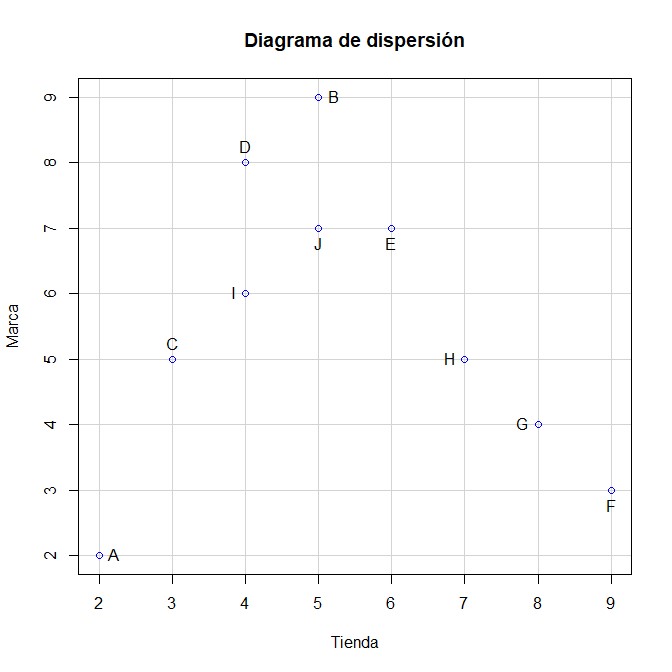
Los grupos más homogéneos parecen ser tres formados por: (A); (C, I, J, D, B, E); (H, G, F).
2. Realizar un análisis de conglomerados con distintos métodos y comparar.
2.a) Método: Vecino más próximo
Si deseamos obtener la matriz de distancias debemos introducir las siguientes órdenes en la ventana de comandos de R Commander:
> d = dist(model.matrix(~-1 + Marca+Tienda, SegmentoMercado))^2
> d
A B C D E F G H I
B 58
C 10 20
D 40 2 10
E 41 5 13 5
F 50 52 40 50 25
G 40 34 26 32 13 2
H 34 20 16 18 5 8 2
I 20 10 2 4 5 34 20 10
J 34 4 8 2 1 32 18 8 2
La matriz de distancia, nos proporciona las distancias o similaridades entre los casos.
Dendograma
Vamos a elegir el método de clúster Enlace simple y la medida de intervalo, la Distancia euclídea al cuadrado. Para eso, vamos a la opción Estadísticos, Análisis dimensional, Análisis de agrupación, Agrupación jerárquica.
En Datos, seleccionar todas las variables que se va analizar.
En Opciones, en Métodos de agrupación seleccionamos Enlace simple y en Medida de la distancia seleccionamos Euclidea al cuadrado
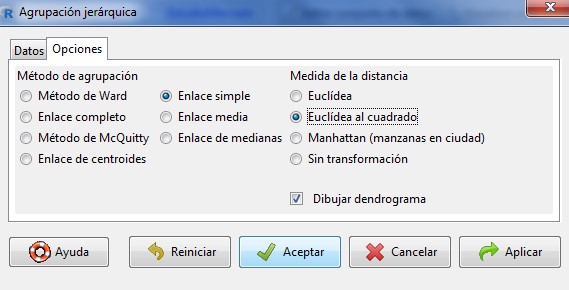
Se pulsa Aceptar y se obtiene el siguiente dendograma:
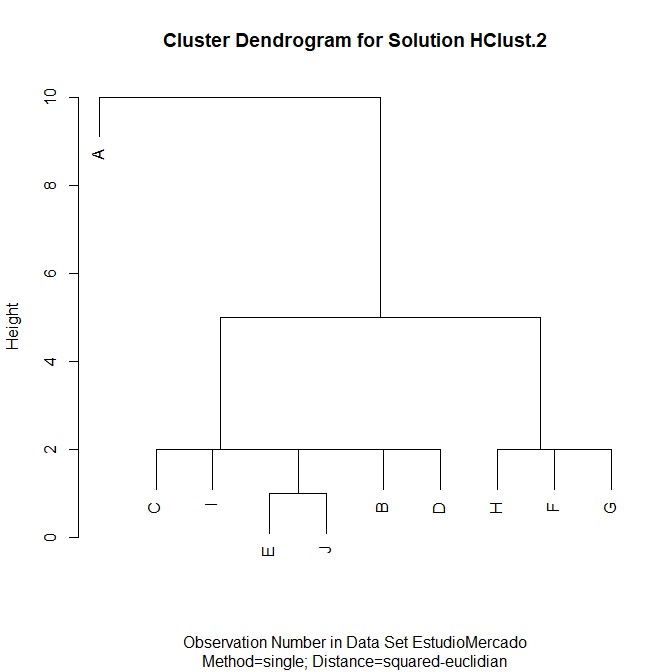
La solución más apropiada se puede observar en el dendograma y es la formada por los grupos: (A); (F, H G) y (I, C, B, D, J, E).
2.b) Método de clúter de Wars
Elegimos el método de clúster Método de Wars y la medida de intervalo, la Distancia euclídea. Para eso, vamos a la opción Estadísticos, Análisis dimensional, Análisis de agrupación, Agrupación jerárquica.
En Opciones, vamos en Métodos de agrupación para seleccionar Método de Wars y en Medida de la distancia seleccionamos Euclidea
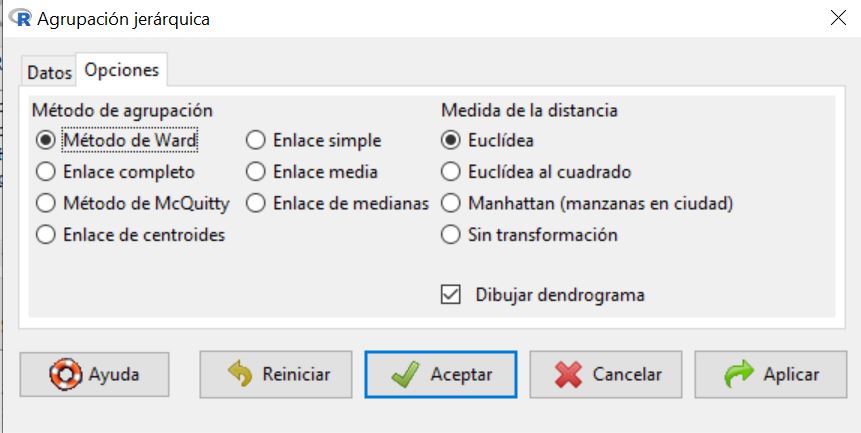
Al pulsar Aceptar se obtiene el siguiente dendograma:
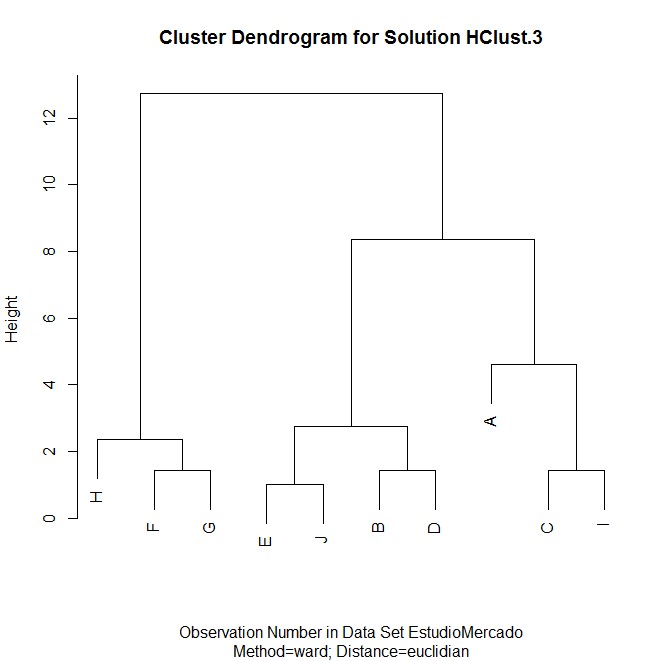
Se puede observar en el dendograma que los grupos formados son: (A, C, I); (H, F, G); y (B, D, E, J).
2.c) Método de clúster Enlace completo
Elegimos el método de clúster Enlace completo y la medida de intervalo, la Distancia Manhattan. Para eso, vamos a la opción Estadísticos, Análisis dimensional, Análisis de agrupación, Agrupación jerárquica.
En Opciones, vamos en Métodos de agrupación para seleccionar Enlace completo y en Medida de la distancia seleccionamos Manhattan
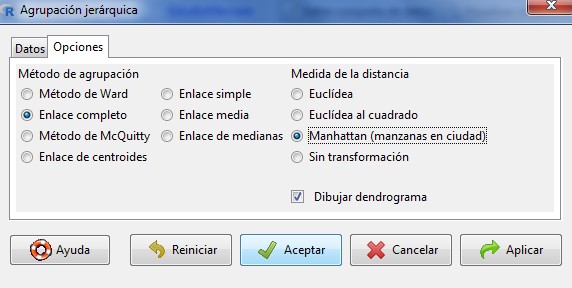
Al pulsar Aceptar se obtiene el siguiente dendograma:
Se puede observar en el dendograma que los grupos formados son: (A, F, G); (H, C, I); y (B, D, E, J).
Este ejercicio lo podemos completar con otras salidas de interés
En el menú Estadísticos, Análisis dimensional, análisis de agrupación, Resumir la agrupación jerárquica, podemos obtener los valores de los centroides para cada una de las variables seleccionadas en cada clúster.
Dentro del menú Agrupación jerárquica, en Seleccionar una solución de agrupación, seleccionamos HCLUST.1 y por ejemplo Número de grupos: 3, que corresponde a seleccionar 3 clústeres.
Al pulsar Aceptar se obtiene la siguiente salida:
> summary(as.factor(cutree(HClust.1, k = 3))) # Cluster Sizes
1 2 3
1 6 3
> by(model.matrix(~-1 + Marca + Tienda, SegmentoMercado), as.factor(cutree(HClust.1, k = 3)), colMeans) # Cluster Centroids
INDICES: 1
Marca Tienda
2 2
——————————————————————————————————————-
INDICES: 2
Marca Tienda
7.0 4.5
——————————————————————————————————————-
INDICES: 3
Marca Tienda
4 8
Dentro del menú Agrupación jerárquica, en Seleccionar una solución de agrupación, seleccionamos HCLUST.2 y por ejemplo Número de grupos: 3, que corresponde a seleccionar 3 clústeres.
> summary(as.factor(cutree(HClust.2, k = 3))) # Cluster Sizes
1 2 3
3 4 3
> by(model.matrix(~-1 + Marca + Tienda, SegmentoMercado), as.factor(cutree(HClust.2, k = 3)), colMeans) # Cluster Centroids
INDICES: 1
Marca Tienda
4.333333 3.000000
——————————————————————————————————————-
INDICES: 2
Marca Tienda
7.75 5.00
——————————————————————————————————————-
INDICES: 3
Marca Tienda
4 8
Dentro del menú Agrupación jerárquica, en Seleccionar una solución de agrupación, seleccionamos HCLUST.3 y por ejemplo Número de grupos: 3, que corresponde a seleccionar 3 clústeres.
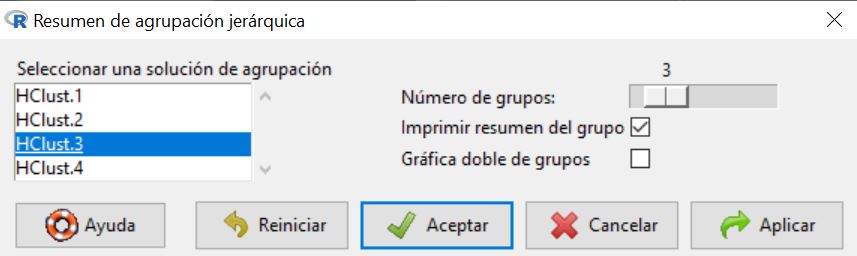
> summary(as.factor(cutree(HClust.3, k = 3))) # Cluster Sizes
1 2 3
3 4 3
> by(model.matrix(~-1 + Marca + Tienda, SegmentoMercado), as.factor(cutree(HClust.3, k = 3)), colMeans) # Cluster Centroids
INDICES: 1
Marca Tienda
4.333333 3.000000
——————————————————————————————————————-
INDICES: 2
Marca Tienda
7.75 5.00
——————————————————————————————————————-
INDICES: 3
Marca Tienda
4 8
Dentro del menú Agrupación jerárquica, en Seleccionar una solución de agrupación, seleccionamos HCLUST.4 y por ejemplo Número de grupos: 3, que corresponde a seleccionar 3 clústeres.
> summary(as.factor(cutree(HClust.4, k = 3))) # Cluster Sizes
1 2 3
1 7 2
> by(model.matrix(~-1 + Marca + Tienda, SegmentoMercado), as.factor(cutree(HClust.4, k = 3)), colMeans) # Cluster Centroids
INDICES: 1
Marca Tienda
2 2
——————————————————————————————————————-
INDICES: 2
Marca Tienda
6.714286 4.857143
——————————————————————————————————————-
INDICES: 3
Marca Tienda
3.5 8.5
Estas tablas corresponden a los centroides dentro de cada variable, dentro de cada uno de los clústeres creados. Esto nos permite comparar las similaridades en los valores de cada variable en los distintos clústeres.
Ejercicio Guiado 3 (Resuelto)
El archivo de datos jóvenes.RData contiene información sobre 14 jóvenes respecto a su edad, estudios, hábitos de lectura, fútbol, cine, teatro, concierto, tv, ámbito familiar…
Se desea clasificar a los 14 jóvenes encuestados por el número de veces que van anualmente al fútbol (fútbol), la paga semanal que reciben (paga) y el número de horas semanales que ven la televisión (tv)
Se pide:
- Realizar un diagrama de dispersión 3-D para mostrar la distribución de los datos y estudiar los posibles grupos que se pueden hacer.
- Utilizar un análisis clúster jerárquico. (Etiquetar los casos mediante Identificación personal, id )
- Método: Vecino más lejano; Medida: Intervalo- Distancia euclídea al cuadrado; Transformar valores: Estandarizar las variables (puntuaciones Z)
- Obtener la Matriz de distancia y el Dendograma
- Analizar las tablas obtenidas y sacar conclusiones
- Repetir el proceso anterior con el Método de Ward
- Repetir el proceso anterior con el Método de Conglomeración: Agrupación de medianas
- Obtener conclusiones ¿Nº de clústeres? ¿Método de conglomeración?
- Realizar un análisis clúster de K medias y comparar las clasificaciones
Nota: Para realizar el apartado 1.
- Seleccionar en el menú principal Gráficas/Gráficos 3D/Diagrama de dispersión en 3D
- Variables explicativas: paga y futbol; Variable explicada: tv
- Pestaña Opciones: Identificar Observaciones Interactivamente con el ratón
El archivo de datos jóvenes.RData contiene 14 datos y está formado por las siguientes variables:
- Variables tipo cadena: id (Identificación personal)
- Variables tipo numérico: centro (Tipo de centro de estudios {1, público}…), estudios (Estudios que cursa {1, EGB}…); estupadr (Estudios del padre {1, Sin estudios}…); estumadr (Estudios de la madre {1, Sin estudios}..); paga (Paga semanal en ptas/100); numher (Nº hermanos incluido sujeto); edad ; califest (Calificación media en estudios); lect ( Libros leídos anualmente); cine (Asistencia anual al cine); fútbol (Asistencia anual al futbol); conciert (Asistencia anual conciertos); tv (Horas semanales tv); sexo ({1, hombre}…); hábitat ({1, rural}…); lectp (Segunda tasa de lectura); univ (¿Deseas acceder a la universidad? {1, sí}…); gustcine (Te gusta ir al cine… {1, solo}…); tipocine (Tipo de película que te gusta {1, amor}…); violen (Nivel de rechazo a la violencia {1, activo}…); impdin (Importancia das al dinero {1, muy poca}..); impest (Importancia de estudios {1, muy poca}…); ingr (Ingresos mensuales {1, <100}…); físico (Importancia al físico {1, muy poca}…); depor (interés deporte {1,muy poca}…).
Solución
- Realizar un diagrama de dispersión 3-D para mostrar la distribución de los datos y estudiar los posibles grupos que se pueden hacer
> library(Rcmdr)
Seleccionar Datos/Importar datos/ desde archivo de texto, portapapeles o URL…
Se muestra la siguiente ventana
Pulsamos Aceptar. seleccionamos el archivo de datos: jovenes.sav, Jovenes.txt
Seleccionar en el menú principal Gráficas/Gráficos 3D/Diagrama de dispersión en 3D
En la pestaña Datos seleccionar:
- En variables explicativas: elegir paga y fútbol
- En variable explicada: elegir tv
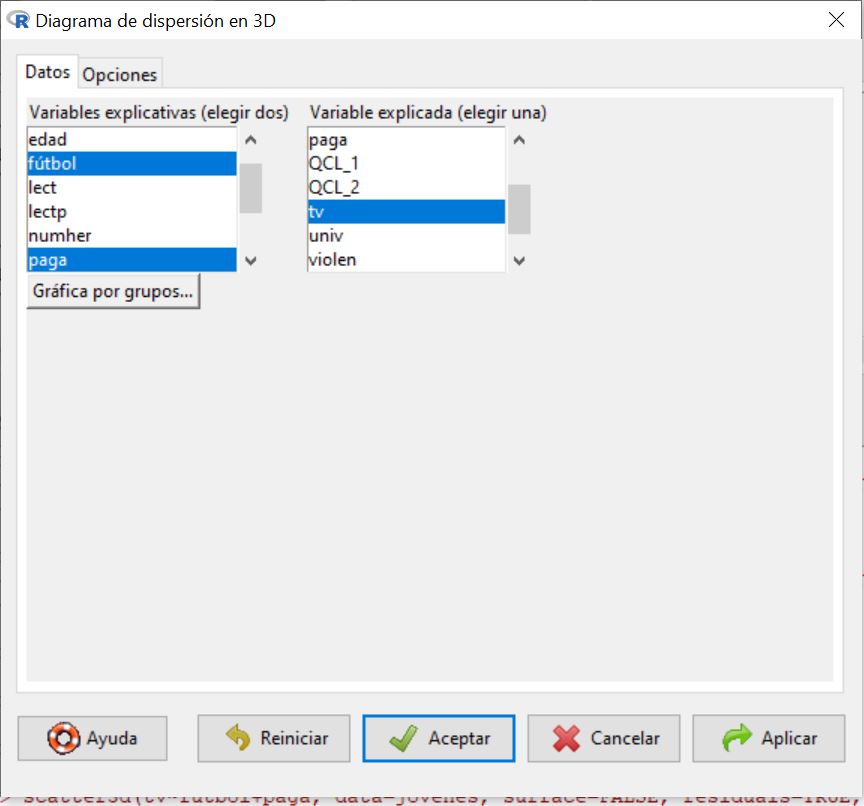
En la pestaña Opciones en el apartado Identificar Observaciones seleccionar Interactivamente con el ratón
Agregué en el script que sale en el 1er cuadrante de R commander
****************************************************************************************************************
scatter3d(tv~fútbol+paga, data=Jovenes, surface=FALSE, residuals=TRUE, bg=”white”, axis.scales=TRUE, xlab=”Futbol”, ylab=”tv”, zlab=”Paga”, grid=TRUE, ellipsoid=FALSE, id=list(method=’identify’))
******************************************************************************************************************
Pega esta orden y lo vuelves a ejecutar y los ejes del gráfico sale etiquetado.
Si se desea que los ejes del gráfico estén etiquetados, añadir en el script que sale en el 1er cuadrante de R commander la siguiente orden y pulse ejecutar.
scatter3d(tv~fútbol+paga, data=Jovenes, surface=FALSE, residuals=TRUE, bg=”white”, axis.scales=TRUE, xlab=”Futbol”, ylab=”tv”, zlab=”Paga”, grid=TRUE, ellipsoid=FALSE, id=list(method=’identify’))
Pulsar ejecutar y los ejes del gráfico se muestran etiquetados.
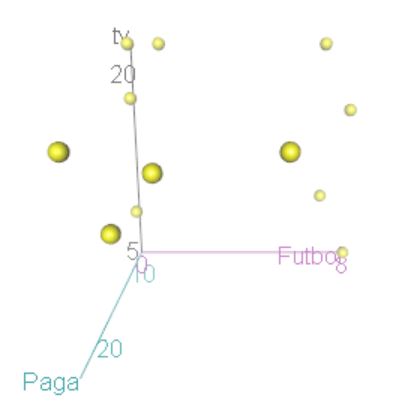
Observando el gráfico podemos observar 3 o 4 grupos de sujetos considerando estas variables.
Cuando se obtiene el gráfico, presiona el lado derecho del ratón y con el cursor se puede rotar el gráfico.
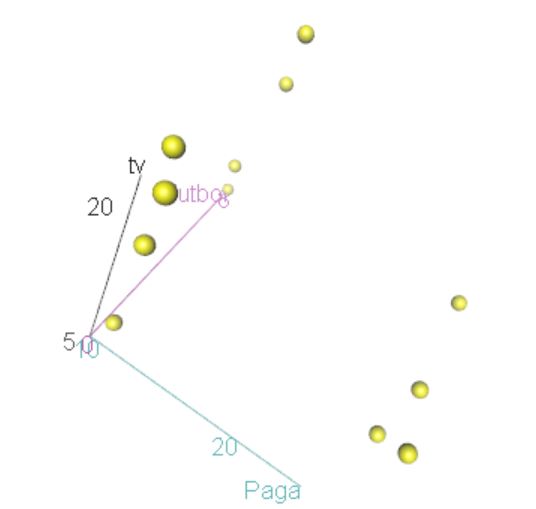
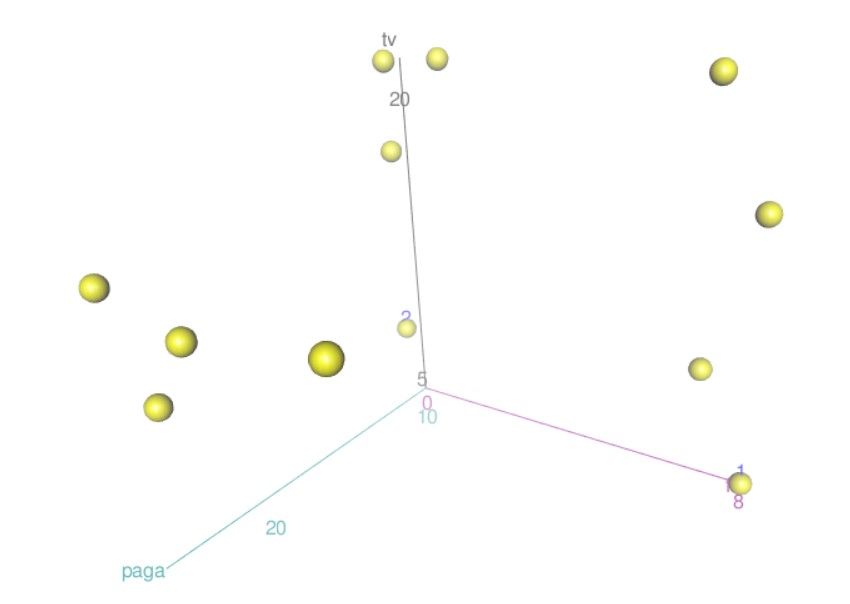
2. Utilizar un análisis clúster jerárquico.
3. Método: Vecino más lejano; Medida: Intervalo- Distancia euclídea al cuadrado; Transformar valores: Estandarizar las variables (puntuaciones Z)
4. Obtener la Matriz de distancia y el Dendograma
5. Analizar las tablas obtenidas y sacar conclusiones
En primer lugar, estandarizamos las variables con las que vamos a trabajar: fútbol, paga, tv, y trabajamos con las variables estandarizadas. Para estandarizar las variables, vamos a la opción Datos, Modificar variables del conjunto de datos activo, Tipificar variables.
Seleccionamos las variables que se va a estandarizar, fútbol, paga, tv. A continuación pulsamos Aceptar y se guardarán las tres variables estandarizadas en la base de datos.
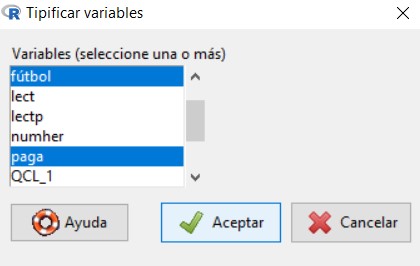
En segundo lugar, para agrupar o clúster los datos, vamos a seleccionar la opción Estadísticos, Análisis de agrupación, Agrupación jerárquico
En la pestaña Datos, seleccionamos las variables estandarizadas (Zfútbol, Zpaga, Ztv).
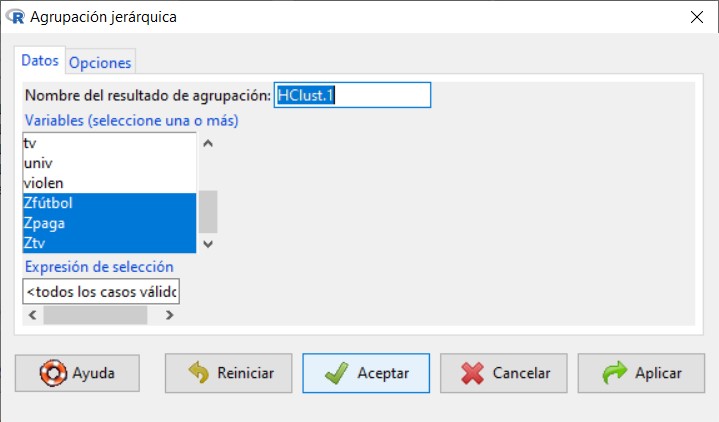
En Opciones, seleccionamos en Método de agrupación: Enlace completo y en Medida de la distancia: Euclídea al cuadrado.
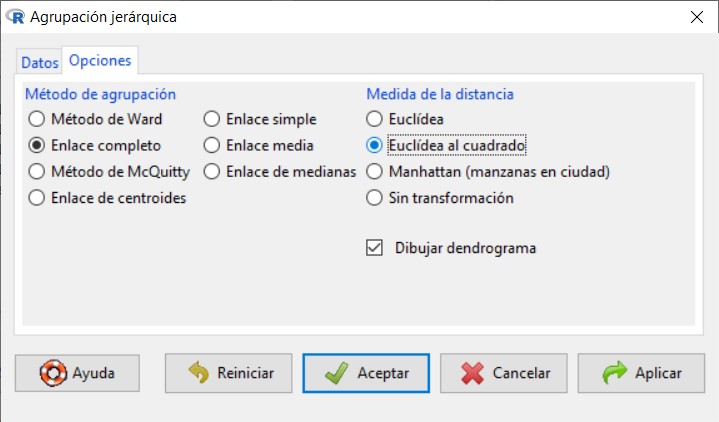
Se pulsa Aceptar y se muestra el siguiente Dendograma
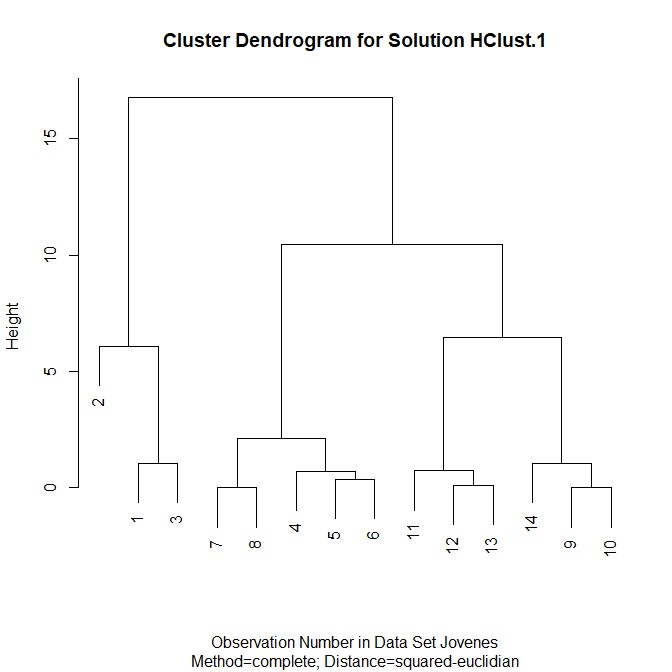
Teniendo en cuenta este dendograma y el diagrama de dispersión obtenido podemos pensar en una solución de tres clústeres.
- Clúster 1: (2,1,3)
- Clúster 2: (7,8,4,5,6)
- Clúster 3: (11, 12, 13, 14, 9, 10)
Por último, tenemos la matriz de distancias:
> d <- dist(model.matrix(~-1 + Z.fútbol+Z.paga+Z.tv, Jovenes))^2
> d
1 2 3 4 5 6 7 8 9 10 11 12 13
2 6.0887837
3 1.0648056 4.2252275
4 10.8936429 4.3865876 7.6325660
5 12.0218856 5.9350095 7.7551915 0.4377599
6 15.3045721 6.1826779 10.3057876 0.7120924 0.3793773
7 10.6270020 8.3088461 6.4786848 1.9877933 0.8046109 2.1261682
8 10.6270020 8.3088461 6.4786848 1.9877933 0.8046109 2.1261682 0.0000000
9 5.6434109 7.9699207 2.0053740 9.0125060 7.3190432 9.6611612 4.9835911 4.9835911
10 5.6434109 7.9699207 2.0053740 9.0125060 7.3190432 9.6611612 4.9835911 4.9835911 0.0000000
11 12.0849078 3.1744186 6.6942197 4.7393008 4.1714436 3.7136856 5.8398538 5.8398538 5.5009284 5.5009284
12 16.7877501 6.6231697 9.8294480 6.9339606 5.4255349 4.6542541 6.7804223 6.7804223 6.4414969 6.4414969 0.6270457
13 15.4933018 6.7269638 8.7050931 7.3925892 5.7140700 5.2829761 6.5586771 6.5586771 5.1470485 5.1470485 0.7308398 0.1037942
14 11.4110588 10.8092068 5.6434109 10.4542714 7.7551915 9.3652191 5.5381163 5.5381163 1.0648056 1.0648056 4.8130828 4.1860371 3.0616822

6. Repetir el proceso anterior con el Método de Ward
En Opciones, seleccionamos en Método de agrupación: Método de Ward y en Medida de la distancia: Euclídea al cuadrado.
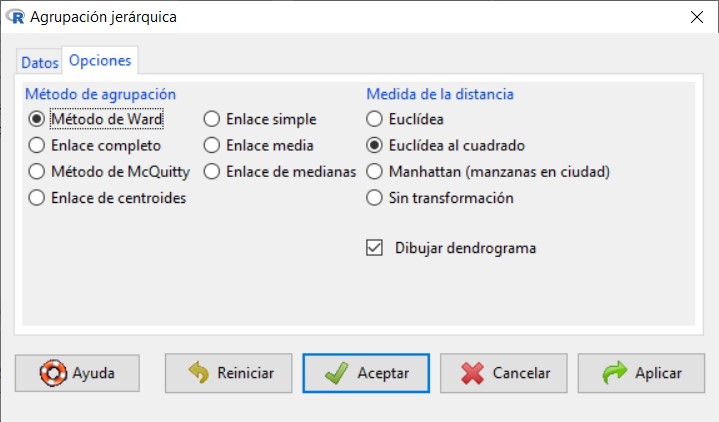
Pulsamos Aceptar. Se muestra el siguiente Dendograma
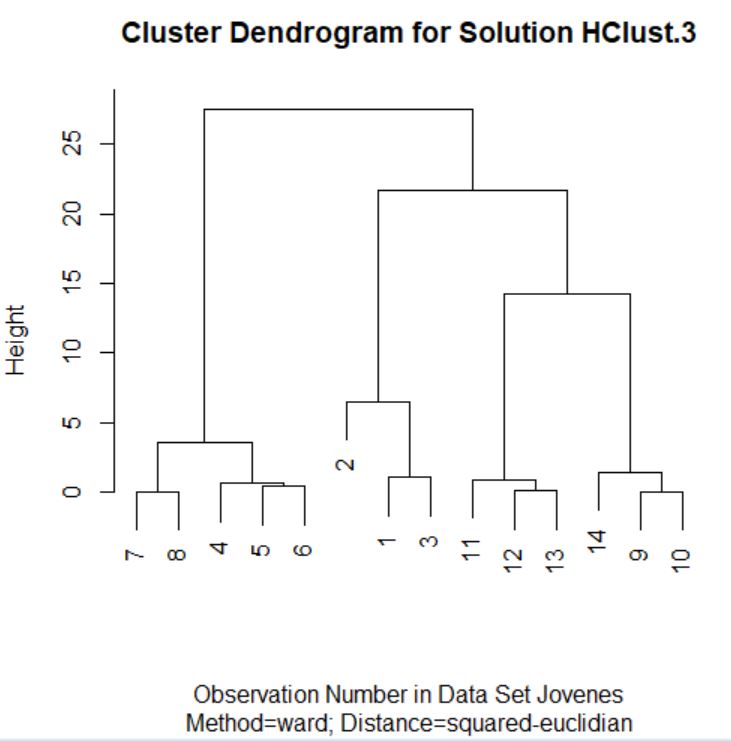
Este dendograma sugiere 3 o 4 clústeres. La solución de 3 clústeres es igual a la proporcionada por el método del enlace completo. La solución de 4 clústeres viene dada por:
- Clúster 1: (7,8,4,5,6)
- Clúster 2: (2,1,3)
- Clúster 3:(11, 12, 13)
- Clúster 4: (14, 9, 10)
En este caso, el clúster 3 que habíamos obtenido mediante el método del enlace completo se divide en dos conglomerados.
7. Repetir el proceso anterior con el Método de Conglomeración: Agrupación de medianas
8. Obtener conclusiones ¿Nº de clústeres? ¿Método de conglomeración?
En Opciones, seleccionamos en Método de agrupación: Enlace de medianas y en Medida de la distancia: Euclídea al cuadrado. Para terminar, damos en Aceptar.
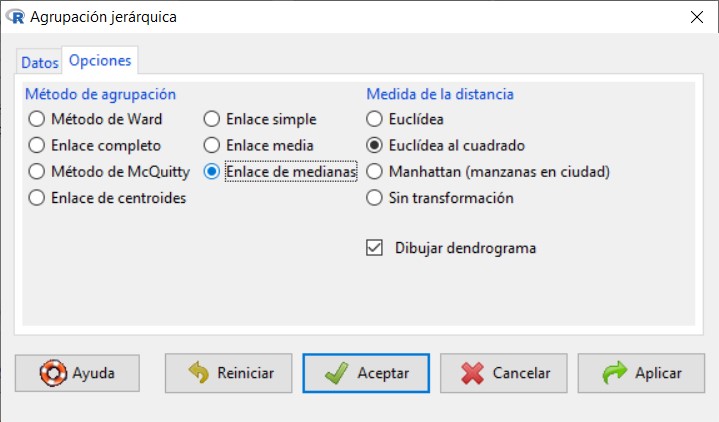
Pulsamos Aceptar. Se muestra el siguiente Dendograma
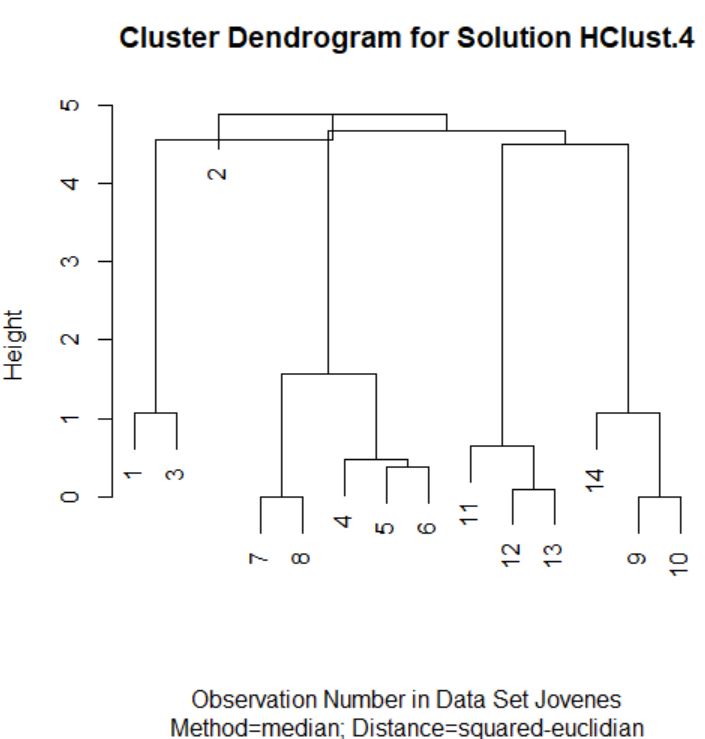
El enlace de medianas nos sugiere la formación de 5 clústeres:
- Clúster 1: (1,3)
- Clúster 2: (2)
- Clúster 3: (7,8,4,5,6)
- Clúster 4:(11, 12, 13)
- Clúster 5: (14, 9, 10)
En este caso el clúster obtenido en primer lugar mediante el enlace completo se divide en dos clústeres: (1,3); (2).
Observando los tres métodos y el diagrama de dispersión tridimensional, decidimos quedarnos con la solución de 3 clústeres.
9. Realizar un análisis clúster de K medias y comparar las clasificaciones
Para realizar el análisis de K medias, se selecciona Estadísticos, Análisis dimensional, Análisis de agrupación y Agrupación por k-medias
Para el método de K-medias, consideramos las mismas variables estandarizadas y fijamos 3 clústeres:
Obtenemos las siguientes salidas
Tamaño de los clústeres
> .cluster$size # Cluster Sizes
[1] 5 4 5
Centros de los grupos para cada variables
> .cluster$centers # Cluster Centroids
new.x.Zfútbol new.x.Zpaga new.x.Ztv
1 1.1331820 -0.7628469 -0.32805717
2 -1.0102818 -0.6601560 0.37472048
3 -0.3249566 1.2909717 0.02828079
Distancias euclídeas entre grupos y dentro de los grupos
> .cluster$withinss # Within Cluster Sum of Squares
[1] 7.109291 4.496558 2.273275
> .cluster$tot.withinss # Total Within Sum of Squares
[1] 13.87912
> .cluster$betweenss # Between Cluster Sum of Squares
[1] 25.12088
También tenemos una nueva variable que se ha añadido al final de la tabla con los resultados del clúster al que pertenece cada individuo.
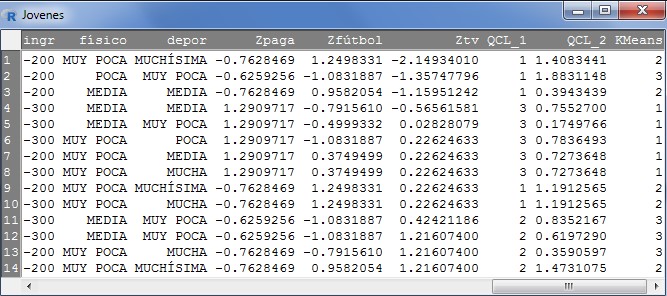
Ejercicio Guiado 4 (Resuelto)
Utilizamos de nuevo el archivo de datos ventas_vehículos.txt que contiene estimaciones de ventas, listas de precios y especificaciones físicas hipotéticas de varias marcas y modelos de vehículos. Se desea hacer un estudio de mercado para poder determinar las posibles competencias para sus vehículos, para ello agrupamos las marcas de los coches según los datos disponibles, hábitos de consumo, sexo, edad, nivel de ingresos, etc. de los clientes. Las empresas de coches adaptan sus estrategias de desarrollo de productos y de marketing en función de cada grupo de consumidores para aumentar las ventas y el nivel de fidelidad a la marca.
Se pide: seleccionar los vehículos cuyo precio de reventa ha sido inferior a 12.000€. Considerando las variables de interés peso neto y tamaño del motor, repetir el análisis hecho en el supuesto práctico 5, obtener el diagrama de dispersión y decidir cuántos clústeres debemos considerar. Analizar los resultados aplicando el método de k-medias.
Nota: El archivo de datos ventas_vehículos.txt contiene 157 datos y está formado por las siguientes variables:
Variables tipo cadena: marca (Fabricante); modelo
Variables tipo numérico: ventas (en miles); reventa (Valor de reventa en 4 años); tipo (Tipo de vehículo: Valores: {0, Automóvil; 1, Camión}); precio (en miles); motor (Tamaño del motor); CV (Caballos); pisada (Base de neumáticos); ancho (Anchura); largo (Longitud); peso_neto (Peso neto); depósito (Capacidad de combustible); mpg (Consumo).
Solución
El archivo ventas_vehículos.txt contiene 157 datos. Para hacer más comprensible la representación gráfica de los resultados. Vamos a quedarnos con aquellos vehículos cuyo precio de reventa es inferior a 12.000€. Para ello vamos al menú Filtrar y en Expresión de selección ponemos: reventa<12.000. Nombramos el fichero de datos de forma distinta para que no sobrescriba el que contiene todos los datos.
En primer lugar seleccionamos Datos, Importar datos, desde archivo de texto, portapapeles…. Una vez importado los datos sólo estudiaremos aquellos vehículos cuyo precio de reventa es inferior a 12.000€
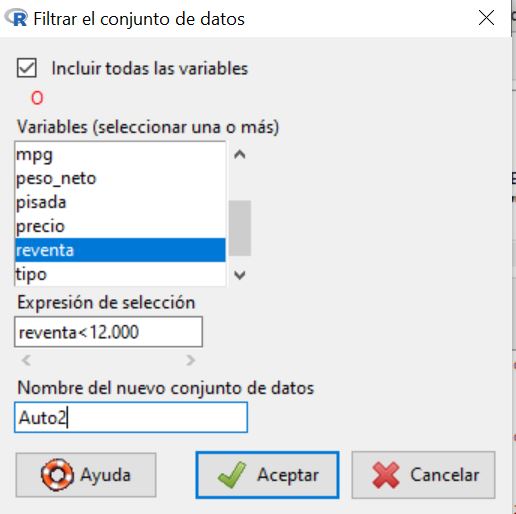
En Expresión de selección: reventa<12.000, nombre del nuevo fichero de datos: Auto2. Pulsamos Aceptar.
Obtenemos el gráfico de dispersión para las variables motor y peso en el menú Gráficas, Diagrama de dispersión:
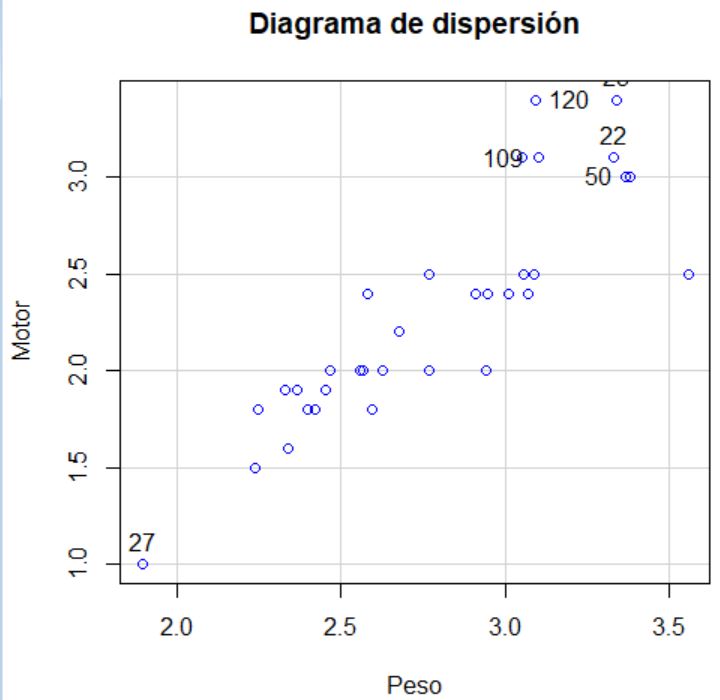
Observando este gráfico podemos pensar en una solución de 3 o 4 clústeres. Podemos pensar en 3 grupos, uno formado por los modeles con peso y tamaño del motor pequeño, otro más numeroso de modelos con peso y tamaño del motor mediano, y finalmente un tercer grupo, menos numeroso y más disperso, de vehículos de mayor peso y mayor motor. O bien, podemos pensar en 4 grupos, dónde el primer clúster se puede dividir en 2, ya que el primer vehículo que aparece está alejado del resto.
Probamos con 3 clústeres. Nos vamos de nuevo al menú Agrupación por k-medias. Seleccionamos las variables peso y motor en la pestaña Datos. En la pestaña Opciones ponemos 3 grupos y Número de iteraciones 20. Pulsamos Aceptar.
Las salidas se presentan a continuación:
> .cluster$size # Cluster Sizes
[1] 13 7 14
> .cluster$centers # Cluster Centroids
new.x.motor new.x.peso_neto
1 2.323077 2.934077
2 3.157143 3.237286
3 1.785714 2.393286
> .cluster$withinss # Within Cluster Sum of Squares
[1] 1.2097938 0.3078623 1.4182977
> .cluster$tot.withinss # Total Within Sum of Squares
[1] 2.935954
> .cluster$betweenss # Between Cluster Sum of Squares
[1] 12.69358
Lo primero que tenemos son los tamaños de los clústeres, El primero está formado por 13 vehículos de tamaño de motor y peso mediano, el segundo con 7 modelos incluye a aquellos que tienen mayor tamaño de motor y peso. El último contiene los modelos más pequeños, hay 14 en total.
Representamos el diagrama de dispersión de nuevo, pero esta vez identificando a qué clúster pertenece cada vehículo:
Pinchar Gráfica por grupos, seleccionar KMeans
Pulsar Aceptar
Pulsar Aceptar
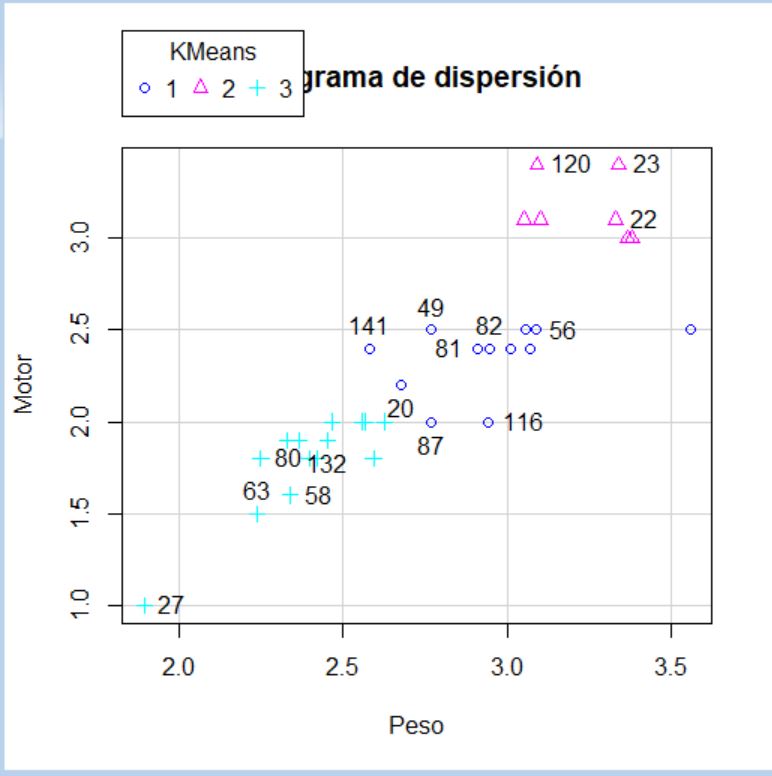
Podemos observar que los modelos se reparten en los clústeres más o menos como habíamos intuido al representar el diagrama de dispersión en primero lugar. Esta solución de 3 clústeres parece ser una buena solución para este caso particular.
Ejercicio Guiado 5 (Resuelto)
Vamos a utilizar de nuevo el archivo de datos jóvenes.RData que contiene información sobre 14 jóvenes.
Se pide:
- Tipificar las variables fútbol, paga y tv
- Realizar un análisis de conglomerados de k-medias con tres conglomerados según las variables tipificadas fútbol, paga y tv (Zpaga, Zfútbol y Ztv)
- Resumir los resultados obtenidos e interpretar la solución.
Solución
Una vez cargado el archivo de datos, tipificamos las variables, en el menú Datos, Modificar variables del conjunto de datos activo, Tipificar variables. Seleccionamos las variables que deseamos tipificar: fútbol, paga, tv. Trabajamos con las variables estandarizadas.
Realizamos el procedimiento Agrupación k-medias, y seleccionamos las variables que acabamos de crear en la pestaña Datos. En la pestaña Opciones, Número de grupos: 3 y Iteraciones máximas: 20.
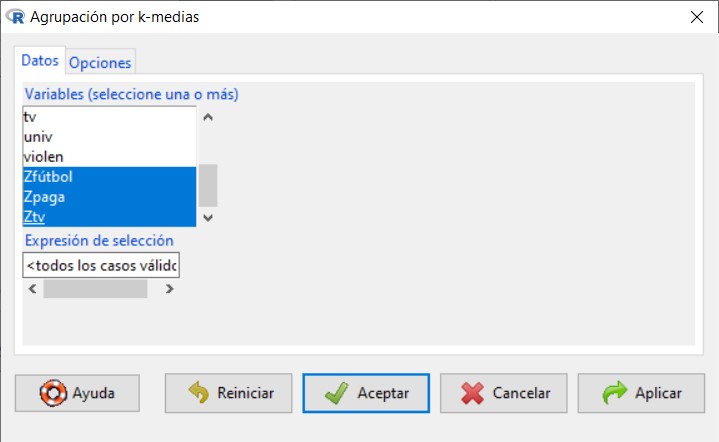
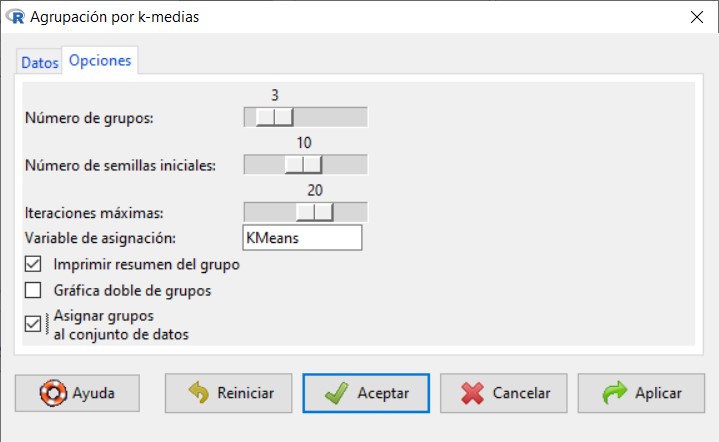
Se pulsa Aceptar
Nuestras salidas son las siguientes:
> .cluster$size # Cluster Sizes
[1] 5 4 5
> .cluster$centers # Cluster Centroids
new.x.Zfútbol new.x.Zpaga new.x.Ztv
1 1.1331820 -0.7628469 -0.32805717
2 -1.0102818 -0.6601560 0.37472048
3 -0.3249566 1.2909717 0.02828079
> .cluster$withinss # Within Cluster Sum of Squares
[1] 7.109291 4.496558 2.273275
> .cluster$tot.withinss # Total Within Sum of Squares
[1] 13.87912
> .cluster$betweenss # Between Cluster Sum of Squares
[1] 25.12088
Los centros de los conglomerados que se han obtenido corresponden a:
Clúster 1: Entre 2 y 3 asistencias anuales al fútbol, 25 unidades de paga semanal, y 16 horas semanales de televisión.
Clúster 2: 4 asistencias anuales al fútbol, entre 10 y 11 unidades de paga semanal, y entre 19 y 20 horas semanales de televisión.
Clúster 3: 5 asistencias anuales al fútbol, entre 10 y 11 unidades de paga semanal, y 8 horas semanales de televisión.
Finalmente, representamos el diagrama de dispersión de la variable tv y fútbol en función de paga, identificando los conglomerados de pertenencia. Para ello nos vamos al menú Gráficas, Gráfica XY.
En la pestaña Datos, seleccionamos como variables explicativas fútbol y tv, y como explicada la variable paga. En grupos ponemos que identifique los individuos con la variable KMeans.
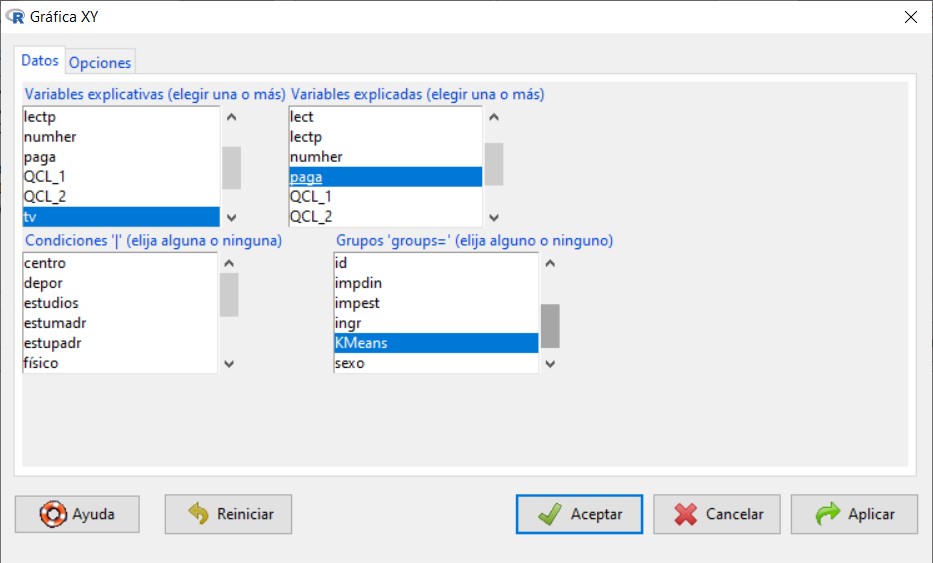
Pulsamos Aceptar y se muestra el siguiente gráfico de dispersión
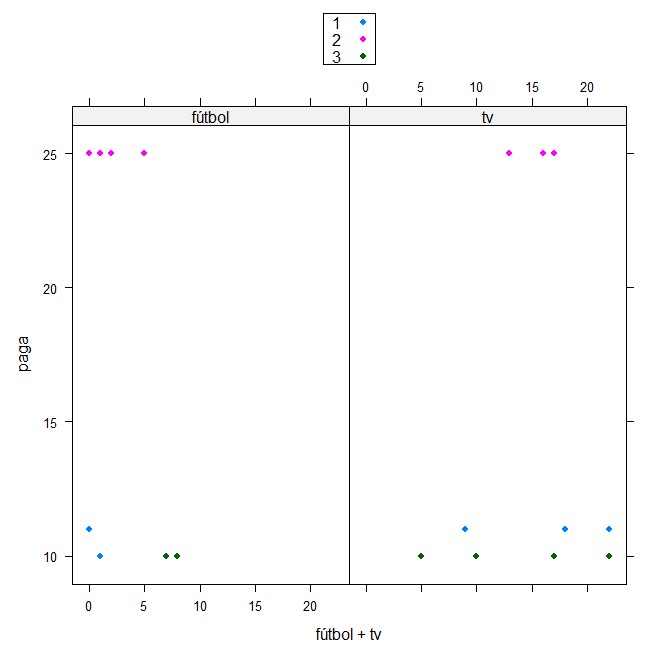 En este gráfico se puede observar que los jóvenes del
En este gráfico se puede observar que los jóvenes del
- Clúster 1 tienen pagas más bajas y acuden al fútbol unas 6 o 7 veces al año, el número de horas semanales de televisión está entre 5 y17 horas.
- Los del clúster 2 se parecen bastante a los del 1, con pagas un poco mayores, aunque la asistencia al fútbol anual está próxima a 0.
- Los del clúster 3 son los que más se diferencian, tienen pagas mucho más altas, pero en términos de asistencia al fútbol y horas de televisión semanales se parecen bastante a los del clúster 2.
Ejercicios Propuestos
Ejercicio Propuesto1
Una empresa de comercio electrónico desea medir el volumen de gasto mensual en euros en función de las reseñas de los clientes, los cupones y el número de visitas a la web de la empresa. Vamos a utilizar el archivo GASTOS1.RData que contiene el gasto mensual de los clientes en euros, números de reseñas positivas realizadas por el cliente, los cupones promocionales disponibles para el cliente y el número de visitas realizadas a la página web.
Se desea clasificar a los 24 clientes encuestados por el número de visitas realizadas a la página web (Visitas), el gasto mensual de los clientes en euros (Gasto) y los cupones promocionales disponibles para el cliente (Cupones)
Se pide:
- Realizar un diagrama de dispersión 3-D para mostrar la distribución de los datos y estudiar los posibles grupos que se pueden hacer.
- Utilizar un análisis clúster jerárquico. (Etiquetar los casos mediante Identificación personal, id )
- Método: Vecino más lejano; Medida: Intervalo- Distancia euclídea al cuadrado; Transformar valores: Estandarizar las variables (puntuaciones Z)
- Obtener la Matriz de distancia y el Dendograma
- Analizar las tablas obtenidas y sacar conclusiones
Ejercicio Propuesto2
Vamos a utilizar de nuevo el archivo de datos GASTOS1.RData que contiene información sobre 24 clientes.
Se pide:
- Tipificar las variables visitas, cupones y gasto
- Realizar un análisis de conglomerados de k-medias con tres conglomerados según las variables tipificadas visitas, cupones y gasto (Zvisitas, Zcupones y Zgasto).
- Resumir los resultados obtenidos e interpretar la solución.
Ejercicio Propuesto 1 (Resuelto)
Una empresa de comercio electrónico desea medir el volumen de gasto mensual en euros en función de las reseñas de los clientes, los cupones y el número de visitas a la web de la empresa. Vamos a utilizar el archivo GASTOS1.RData que contiene el gasto mensual de los clientes en euros, números de reseñas positivas realizadas por el cliente, los cupones promocionales disponibles para el cliente y el número de visitas realizadas a la página web.
Se desea clasificar a los 24 clientes encuestados por el número de visitas realizadas a la página web (Visitas), el gasto mensual de los clientes en euros (Gasto) y los cupones promocionales disponibles para el cliente (Cupones)
Se pide:
- Realizar un diagrama de dispersión 3-D para mostrar la distribución de los datos y estudiar los posibles grupos que se pueden hacer.
- Utilizar un análisis clúster jerárquico. (Etiquetar los casos mediante Identificación personal, id )
- Método: Vecino más lejano; Medida: Intervalo- Distancia euclídea al cuadrado; Transformar valores: Estandarizar las variables (puntuaciones Z)
- Obtener la Matriz de distancia y el Dendograma
- Analizar las tablas obtenidas y sacar conclusiones
Solución
En primer lugar tenemos que cargar los datos y elegimos el fichero GASTOS1.xlsx
- Realizar un diagrama de dispersión 3-D para mostrar la distribución de los datos y estudiar los posibles grupos que se pueden hacer.
- Utilizar un análisis clúster jerárquico. (Etiquetar los casos mediante Identificación personal, id )
- Método: Vecino más lejano; Medida: Intervalo- Distancia euclídea al cuadrado; Transformar valores: Estandarizar las variables (puntuaciones Z)
- Obtener la Matriz de distancia y el Dendograma
- Analizar las tablas obtenidas y sacar conclusiones
{kind=link}
Solución del Ejercicio Propuesto 1
Ejercicio Propuesto 2 (Resuelto)
Vamos a utilizar de nuevo el archivo de datos GASTOS1.RData que contiene información sobre 24 clientes.
Se pide:
- Tipificar las variables visitas, cupones y gasto
- Realizar un análisis de conglomerados de k-medias con tres conglomerados seghttps://wpd.ugr.es/~bioestad/wp-content/uploads/GASTOS1.xlsxún las variables tipificadas visitas, cupones y gasto (Zvisitas, Zcupones y Zgasto).
- Resumir los resultados obtenidos e interpretar la solución.
Solución
- Tipificar las variables visitas, cupones y gasto
En primer lugar, vamos a cargar el conjunto de datos desde un archivo de Excel. Pulsamos Aceptar y elegimos el dichero Gastos1.xlsx
2. Realizar un análisis de conglomerados de k-medias con tres conglomerados según las variables tipificadas visitas, cupones y gasto (Zvisitas, Zcupones y Zgasto).
> .cluster$size # Cluster Sizes
[1] 10 6 8
> .cluster$centers # Cluster Centroids
new.x.Z.Cupones new.x.Z.Gasto new.x.Z.Visitas
1 0.5202637 -0.2347809 -0.6432235
2 -1.4483016 -1.0948018 -0.4238294
3 0.4358966 1.1145775 1.1219014
> .cluster$withinss # Within Cluster Sum of Squares
[1] 9.080704 6.103121 4.038434
> .cluster$tot.withinss # Total Within Sum of Squares
[1] 19.22226
> .cluster$betweenss # Between Cluster Sum of Squares
[1] 49.77774
3. Resumir los resultados obtenidos e interpretar la solución.