DISEÑO ESTADÍSTICO DE EXPERIMENTOS
Objetivos
- Identificar un diseño unifactorial de efectos fijos.
- Plantear y resolver el contraste sobre las medias de los tratamientos.
- Saber aplicar los procedimientos de comparaciones múltiples.
- Identificar un diseño unifactorial de efectos aleatorios.
- Estimar los componentes de la varianza.
- Identificar un diseño en bloque completo aleatorizado con efectos fijos.
- Identificar un diseño en bloque incompleto aleatorizado con efectos fijos.
- Identificar un diseño en bloque incompleto balanceado (BIB).
- Identificar un diseño en cuadrados latinos.
- Identificar un diseño en cuadrados greco-latinos.
- Identificar un diseño en cuadrados de Jouden.
- Plantear y resolver los contrastes de igualdad de tratamientos y de igualdad de bloques.
- Identificar un diseño bifactorial de efectos fijos y estudiar las interacciones entre los factores.
- Identificar un diseño trifactorial de efectos fijos y estudiar las interacciones entre los factores
- Estudiar la influencia de los factores.
- Analizar en qué sentido se producen las interacciones mediante el gráfico de medias.
- Aplicar los procedimientos de comparaciones múltiples: Obtener conclusiones sobre el experimento planteado y las interacciones.
- Analizar la idoneidad de los modelos planteados.
Introducción al Diseño Estadístico de Experimentos
En la práctica 6 hemos descrito métodos de inferencias sobre la media y la varianza de una población y de dos poblaciones. En esta práctica 7 ampliamos dichos métodos a más de dos poblaciones e introducimos algunos aspectos elementales del Diseño Estadístico de Experimentos y del Análisis de la Varianza.
El diseño estadístico de experimentos incluye un conjunto de técnicas de análisis y un método de construcción de modelos estadísticos que, conjuntamente, permiten llevar a cabo el proceso completo de planificar un experimento para obtener datos apropiados, que puedan ser analizados con métodos estadísticos, con objeto de obtener conclusiones válidas y objetivas.
El análisis de la varianza o abreviadamente ANOVA (del inglés analysis of variance) es un procedimiento estadístico que permite dividir la variabilidad observada en componentes independientes que pueden atribuirse a diferentes causas de interés. Es una técnica estadística para comparar más de dos grupos, es decir un método para comparar más de dos tratamientos y la variable de estudio o variable respuesta es numérica.
En esta práctica presentamos el Diseño Completamente Aleatorio con efectos fijos y con efectos aleatorios, el Diseño en Bloques Completos Aleatorizados, Diseño en Bloques Incompletos Balanceados (BIB), el Diseño en Cuadrados Latinos, el Diseño en Cuadrados Greco-Latinos, el Diseño en Cuadrados de Jouden, el Diseño Bifactorial de efectos fijos y el Diseño Trifactorial de efectos fijos.
Diseño Completamente Aleatorio con efectos fijos (Diseño unifactorial de efectos fijos)
El primer diseño que presentamos es el diseño completamente aleatorio de efectos fijos y la técnica estadística es el análisis de la varianza de una vía o un factor. La descripción del diseño así como la terminología subyacente la vamos a introducir mediante el siguiente supuesto práctico.
Supuesto práctico 1
La contaminación es uno de los problemas ambientales más importantes que afectan a nuestro mundo. En las grandes ciudades, la contaminación del aire se debe a los escapes de gases de los motores de explosión, a los aparatos domésticos de la calefacción, a las industrias,… El aire contaminado nos afecta en nuestro vivir diario, manifestándose de diferentes formas en nuestro organismo. Con objeto de comprobar la contaminación del aire en una determinada ciudad, se ha realizado un estudio en el que se han analizado las concentraciones de monóxido de carbono (CO) durante cinco días de la semana (lunes, martes, miércoles, jueves y viernes).
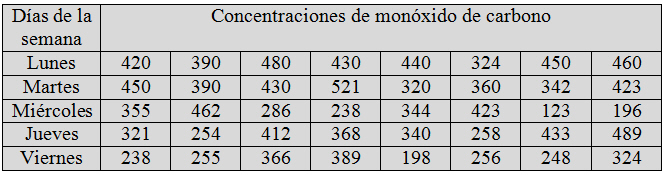
En el ejemplo disponemos de una colección de 40 unidades experimentales y queremos estudiar el efecto de las concentraciones de monóxido de carbono en 5 días distintos. Es decir, estamos interesados en contrastar el efecto de un solo factor, que se presenta con cinco niveles, sobre la variable respuesta.
Nos interesa saber si las concentraciones medias de monóxido de carbono son iguales en los cinco días de la semana, para ello realizamos el siguiente contraste de hipótesis:
![]() Es decir, contrastamos que no hay diferencia en las medias de los cinco tratamientos frente a la alternativa de que al menos una media difiere de otra.
Es decir, contrastamos que no hay diferencia en las medias de los cinco tratamientos frente a la alternativa de que al menos una media difiere de otra.
En este modelo, que estudia el efecto que produce un solo factor en la variable respuesta, la asignación de las unidades experimentales a los distintos niveles del factor se debe realizar de forma completamente al azar. Este modelo, junto con este procedimiento de asignación, recibe el nombre de Diseño Completamente Aleatorizado y está basado en el modelo estadístico de Análisis de la Varianza de un Factor o una Vía. Esta técnica estadística, Análisis de la Varianza de un factor, se utiliza cuando se tienen que comparar más de dos grupos y la variable respuesta es una variable numérica. Para aplicar este diseño adecuadamente las unidades experimentales deben ser lo más homogéneas posible.
Todo este planteamiento se puede formalizar de manera general para cualquier experimento unifactorial. Supongamos un factor con I niveles y para el nivel i-ésimo se obtienen ni observaciones de la variable respuesta. Entonces podemos postular el siguiente modelo:
![]() donde:
donde:
- yij: es la variable aleatoria que representa la observación j-ésima del i-ésimo tratamiento (Variable respuesta). µ: Es un efecto constante, común a todos los niveles del factor, denominado media global.
- τi: es la parte de yij debida a la acción del nivel i-ésimo, que será común a todos los elementos sometidos a ese nivel del factor, llamado efecto del tratamiento i-ésimo.
- uij: son variables aleatorias que engloban un conjunto de factores, cada uno de los cuales influye en la respuesta sólo en pequeña magnitud pero que de forma conjunta debe tenerse en cuenta. Es decir, se pueden interpretar como las variaciones causadas por todos los factores no analizados y que dentro del mismo tratamiento variarán de unos elementos a otros. Reciben el nombre de perturbaciones o error experimental.
Nuestro objetivo es estimar el efecto de los tratamientos y contrastar la hipótesis de que todos los niveles del factor producen el mismo efecto, frente a la alternativa de que al menos dos difieren entre sí. Para ello, se supone que los errores experimentales son variables aleatorias independientes igualmente distribuidas según una Normal de media cero y varianza constante.
En este modelo se distinguen dos situaciones según la selección de los tratamientos: modelo de efectos fijos y modelo de efectos aleatorios.
En el modelo de efectos fijos el experimentador decide qué niveles concretos se van a considerar y las conclusiones que se obtengan sólo son aplicables a esos niveles, no pudiéndose hacer extensivas a otros niveles no incluidos en el estudio.
En el modelo de efectos aleatorios, los niveles del factor se seleccionan al azar; es decir los niveles estudiados son una muestra aleatoria de una población de niveles y las conclusiones que se obtengan se generalizan a todos los posibles niveles del factor, hayan sido explícitamente considerados en el estudio o no.
En cuanto a los tamaños muestrales de los tratamientos, los modelos se clasifican en: modelo equilibrado o balanceado si todas las muestras son del mismo tamaño ni = n y modelo no-equilibrado o no-balanceado si los tamaños muestrales ni son distintos.
El contraste de hipótesis planteado anteriormente está asociado a la descomposición de la variabilidad de la variable respuesta. Dicha variabilidad se descompone de la siguiente forma:
SCT = SCTr + SCR
Donde:
- SCT: es la suma total de cuadrados o variabilidad total de Y
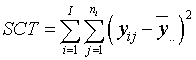 SCTr: es la suma de cuadrados entre tratamientos o variabilidad explicada,
SCTr: es la suma de cuadrados entre tratamientos o variabilidad explicada,
 SCR: es la suma dentro de los tratamientos, variabilidad no explicada o residual
SCR: es la suma dentro de los tratamientos, variabilidad no explicada o residual
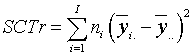 La tabla de análisis de la varianza (tabla ANOVA) se construye a partir de esta descomposición y proporciona el valor del estadístico F que permite contrastar la hipótesis nula planteada anteriormente.
La tabla de análisis de la varianza (tabla ANOVA) se construye a partir de esta descomposición y proporciona el valor del estadístico F que permite contrastar la hipótesis nula planteada anteriormente.
![]()
En el Supuesto práctico 1:
- Variable respuesta: Concentración de CO.
- Factor: Día de la semana que tiene cinco niveles. Es un factor de efectos fijos ya que viene decidido qué niveles concretos se van a utilizar (5 días de la semana).
- Modelo equilibrado: Los niveles de los factores tienen el mismo número de elementos (8 elementos).
- Tamaño del experimento: Número total de observaciones, en este caso 40 unidades experimentales.
El problema planteado se modeliza a través de un diseño unifactorial totalmente aleatorizado de efectos fijos equilibrado.
Para realizarlo mediante SPSS, se comienza definiendo las variables e introduciendo los datos:
- Nombre: Concentración_CO; Tipo: Numérico; Anchura: 3; Decimales: 0
- Nombre: Día_semana; Tipo: Numérico; Anchura: 8; Decimales: 0; Valores: {1, Lunes; 2, Martes; 3, Miércoles; 4, Jueves; 5, Viernes}
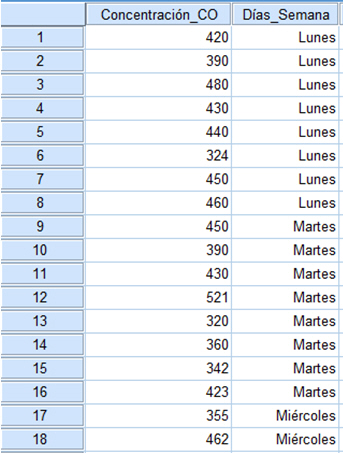 En primer lugar describimos los cinco grupos que tenemos que comparar, los cinco días de la semana, la variable respuesta es la concentración de CO en estos días de la semana. Cada día de la semana tiene ocho unidades, en total tenemos 40 observaciones. La hipótesis nula es que el promedio de las concentraciones es igual el día lunes que el martes, que el miércoles… Es decir, no hay diferencias en las concentraciones con respecto a los días y la alternativa es que las concentraciones de CO son diferentes al menos en dos días.
En primer lugar describimos los cinco grupos que tenemos que comparar, los cinco días de la semana, la variable respuesta es la concentración de CO en estos días de la semana. Cada día de la semana tiene ocho unidades, en total tenemos 40 observaciones. La hipótesis nula es que el promedio de las concentraciones es igual el día lunes que el martes, que el miércoles… Es decir, no hay diferencias en las concentraciones con respecto a los días y la alternativa es que las concentraciones de CO son diferentes al menos en dos días.
Para la descripción de los cinco grupos comenzamos realizando un análisis descriptivo. Para ello, se selecciona, en el menú principal, Analizar/Comparar medias/medias
 se introduce en el campo Lista de dependientes: La variable respuesta Concentración_CO y en el campo Factor: el factor Día_semana. Pulsando Aceptar se obtiene la Tabla ANOVA
se introduce en el campo Lista de dependientes: La variable respuesta Concentración_CO y en el campo Factor: el factor Día_semana. Pulsando Aceptar se obtiene la Tabla ANOVA
se introduce en el campo Lista de dependientes: La variable respuesta Concentración_CO y en el campo Lista de independientes: el factor Día_semana. Se pulsa Opciones y se selecciona Número de casos, Media, Desviación típica, Mínimo, Máximo y Desviación Error de la media.
 Pulsar Continuar y Aceptar y se obtiene la siguiente salida
Pulsar Continuar y Aceptar y se obtiene la siguiente salida
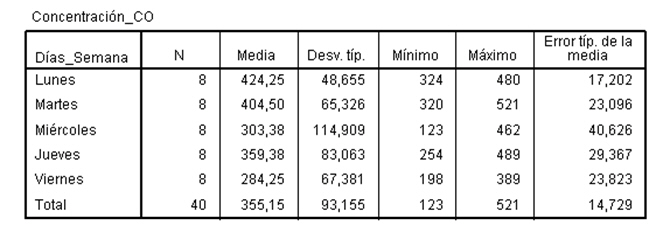 donde se presentan los cinco grupos dispuestos en forma comparativa. A simple vista se puede observar que el valor medio de estos grupos es numéricamente distinto, de hecho la media del día lunes tiene un valor medio casi equivalente al doble de la media del viernes. Por tanto, nuestra hipótesis se centra en comprobar si la concentración de CO es significativamente distinta en los cinco grupos. Para responder a esta hipótesis recurrimos al Análisis de la Varianza de un factor y realizamos el contraste de igualdad de medias
donde se presentan los cinco grupos dispuestos en forma comparativa. A simple vista se puede observar que el valor medio de estos grupos es numéricamente distinto, de hecho la media del día lunes tiene un valor medio casi equivalente al doble de la media del viernes. Por tanto, nuestra hipótesis se centra en comprobar si la concentración de CO es significativamente distinta en los cinco grupos. Para responder a esta hipótesis recurrimos al Análisis de la Varianza de un factor y realizamos el contraste de igualdad de medias
![]() mediante SPSS dicho contraste se puede ejecutar de dos formas:
mediante SPSS dicho contraste se puede ejecutar de dos formas:
- Se selecciona, en el menú principal, Analizar/Comparar medias/ANOVA de un factor… En la salida correspondiente,
 se introduce en el campo Lista de dependientes: La variable respuesta Concentración_CO y en el campo Factor: el factor Día_semana. Pulsando Aceptar se obtiene la Tabla ANOVA
se introduce en el campo Lista de dependientes: La variable respuesta Concentración_CO y en el campo Factor: el factor Día_semana. Pulsando Aceptar se obtiene la Tabla ANOVA
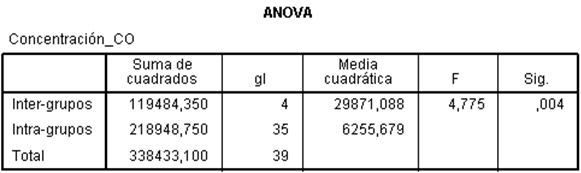 donde:
donde:
- Inter-grupos: Representa la Suma de cuadrados debida a los tratamientos (SCTr)
- Intra-grupos: Representa la suma de cuadrados residual (SCR)
- Total: Representa la suma de cuadrados total (SCT).
Si el valor de F es mayor que uno quiere decir que hay un efecto positivo del factor día. Se observa que el P-valor (Sig.) tiene un valor de 0.004, que es menor que el nivel de significación 0.05. Por lo tanto, hemos comprobado estadísticamente que estos cinco grupos son distintos. Es decir no se puede rechazar la hipótesis alternativa que dice que al menos dos grupos son diferentes, pero ¿Cuáles son esos grupos? ¿Los cinco grupos son distintos o sólo alguno de ellos? Pregunta que resolveremos más adelante mediante los contrastes de comparaciones múltiples.
- Se selecciona, en el menú principal, Analizar/Modelo lineal general/ Univariante…

En la salida correspondiente, se introduce en el campo Variable dependiente: La variable respuesta Concentración_CO y en el campo Factores fijos: el factor Día_semana. Pulsando Aceptar se obtiene la Tabla ANOVA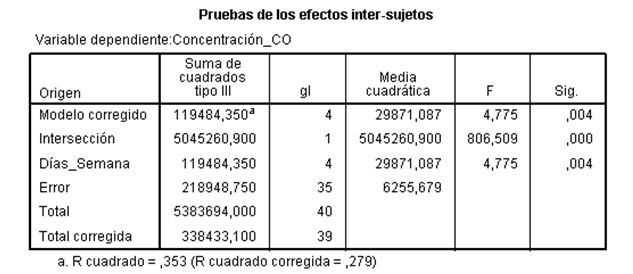 En la tabla correspondiente a las pruebas de los efectos inter-sujetos, se muestran el Origen denominado:
En la tabla correspondiente a las pruebas de los efectos inter-sujetos, se muestran el Origen denominado:
- Modelo corregido: que recoge la suma de cuadrados asociadas a todos los factores que se incluyen en el modelo
- Intersección: coincide con la expresión
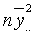
- Días-semana: Representa la Suma de cuadrados debida a los tratamientos (SCTr), que viene identificada con el nombre de la variable que representa al factor.
- Error: Representa la suma de cuadrados residual (SCR).
- Total: Representa la suma de los cuadrados de todas las observaciones
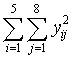
- Total corregida: Representa la suma de cuadrados total (SCT). Por lo tanto, Intersección es la diferencia entre Total corregido y Total.
En la Tabla ANOVA, el valor del estadístico de contraste de igualdad de medias, F = 4.775 deja a su derecha un p-valor de 0.004, menor que el nivel de significación del 5%, por lo que se rechaza la Hipótesis nula de igualdad de medias. Es decir, existen diferencias significativas en las concentraciones medias de monóxido de carbono entre los cinco días de la semana.
La salida de SPSS también nos muestra que R cuadrado vale 0.353, indicándonos que el modelo explica el 35.3% de la variabilidad de los datos.
El modelo que hemos propuesto hay que validarlo, para ello hay que comprobar si se verifican las hipótesis básicas del modelo, es decir, si las perturbaciones son variables aleatorias independientes con distribución normal de media 0 y varianza constante (homocedasticidad).
Estudio de la Idoneidad del modelo
Como hemos dicho anteriormente, validar el modelo propuesto consiste en estudiar si las hipótesis básicas del modelo están o no en contradicción con los datos observados. Es decir si se satisfacen los supuestos del modelo: Normalidad, Independencia, Homocedasticidad. Para ello utilizamos procedimientos gráficos y analíticos.
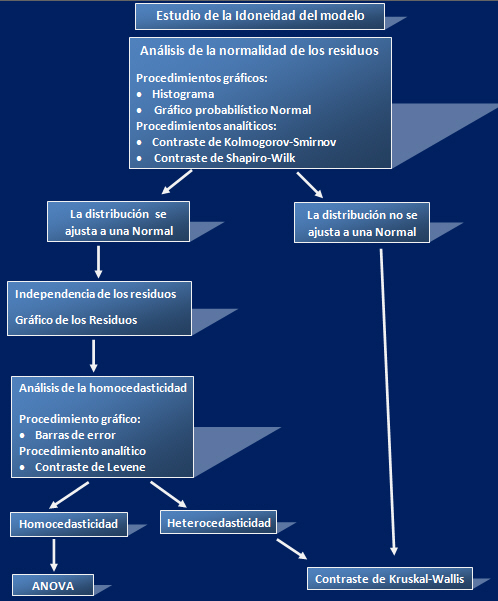
Hipótesis de normalidad
En primer lugar, analizamos la normalidad de las concentraciones y continuamos con el análisis de la normalidad de los residuos. Para analizar la normalidad de las concentraciones, se selecciona en el menú principal: Analizar/Estadísticos descriptivos/Explorar… y en la salida correspondiente
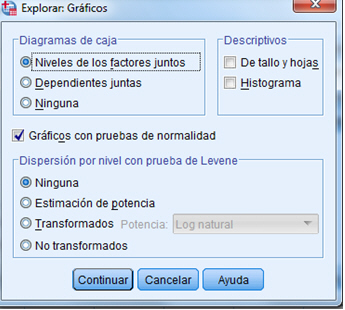 se introduce en el campo Lista de dependientes: La variable respuesta Concentración_CO y en el campo Lista de Factores: el factor Día_semana . En Visualización se selecciona Ambos. Se pulsa Gráficos y se selecciona Gráficos con pruebas de normalidad. Pulsando Continuar y Aceptar se obtiene los siguientes contrastes de normalidad
se introduce en el campo Lista de dependientes: La variable respuesta Concentración_CO y en el campo Lista de Factores: el factor Día_semana . En Visualización se selecciona Ambos. Se pulsa Gráficos y se selecciona Gráficos con pruebas de normalidad. Pulsando Continuar y Aceptar se obtiene los siguientes contrastes de normalidad
 Observamos el contraste de Shapiro-Wilk que es adecuado cuando las muestras son pequeñas (n<50) y es una alternativa más potente que el test de Kolmogorov-Smirnov. Todos los p-valores (Sig.) son mayores que el nivel de significación 0.05. Concluyendo que las muestras de las concentraciones se distribuyen de forma normal en cada día de la semana.
Observamos el contraste de Shapiro-Wilk que es adecuado cuando las muestras son pequeñas (n<50) y es una alternativa más potente que el test de Kolmogorov-Smirnov. Todos los p-valores (Sig.) son mayores que el nivel de significación 0.05. Concluyendo que las muestras de las concentraciones se distribuyen de forma normal en cada día de la semana.
Para analizar la hipótesis de normalidad de los residuos, se debe comenzar salvando los residuos. Para ello, se selecciona, en el menú principal, Analizar/Modelo lineal general/ Univariante/Guardar…
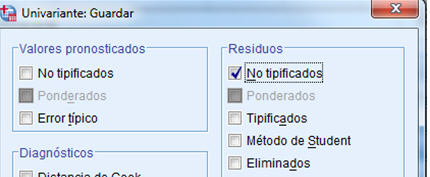
En la ventana resultante se selecciona Residuos No tipificados. Se pulsa, Continuar y Aceptar. Y en el Editor de datos se ha creado una nueva variable RES_1 que contiene los residuos del modelo.
El estudio de la Normalidad de los residuos, lo realizamos mediante procedimientos gráficos (Histograma y Gráfico probabilístico Normal) y procedimientos analíticos (Contraste de Kolmogorov-Smirnov).
Histograma: Se selecciona en el menú principal, Gráficos/Cuadros de diálogos antiguos/Histograma
se introduce en el campo Variable: la variable que recoge los residuos RES_1, se selecciona Mostrar curva normal. Se pulsa Aceptar
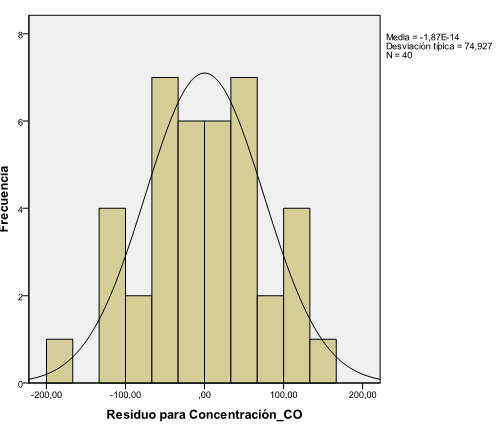 Aunque podemos observar en el histograma resultante algunas desviaciones de la normalidad, éstas no implican necesariamente la ausencia de normalidad de los residuos.
Aunque podemos observar en el histograma resultante algunas desviaciones de la normalidad, éstas no implican necesariamente la ausencia de normalidad de los residuos.
Gráfico probabilístico Normal: Se selecciona en el menú principal, Analizar/Estadísticos descriptivos/Gráficos Q-Q
 se introduce en el campo Variables: RES_1. Se pulsa Aceptar
se introduce en el campo Variables: RES_1. Se pulsa Aceptar
 Podemos apreciar en este gráfico que los puntos aparecen próximos a la línea diagonal. Esta gráfica no muestra una desviación marcada de la normalidad.
Podemos apreciar en este gráfico que los puntos aparecen próximos a la línea diagonal. Esta gráfica no muestra una desviación marcada de la normalidad.
Contraste de Kolmogorov-Smirnov: Se selecciona en el menú principal, Analizar/Pruebas no paramétricas/ Cuadros de diálogos antiguos/K-S de 1 muestra
 se introduce en el campo Lista Contrastar variables: RES_1. Se pulsa Aceptar
se introduce en el campo Lista Contrastar variables: RES_1. Se pulsa Aceptar
 El valor del p-valor es mayor que el nivel de significación 0.05, no rechazándose la hipótesis de normalidad.
El valor del p-valor es mayor que el nivel de significación 0.05, no rechazándose la hipótesis de normalidad.
Hipótesis de independencia
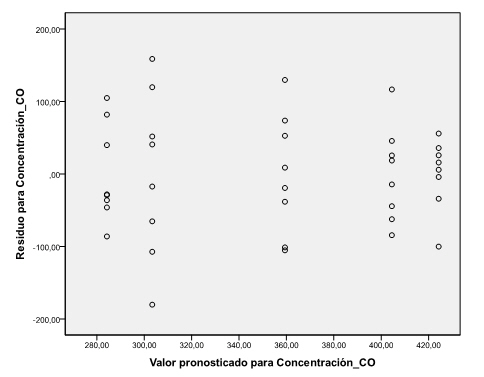
Para comprobar que se satisface el supuesto de independencia entre los residuos analizamos el gráfico de los residuos frente a los valores pronosticados o predichos por el modelo. El empleo de este gráfico es útil puesto que la presencia de alguna tendencia en el mismo puede ser indicio de una violación de dicha hipótesis. Para obtener dicho gráfico seleccionamos Opciones en el cuadro de diálogo de Univariante y marcamos la casilla Gráfico de los residuos
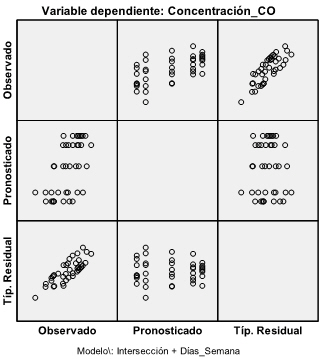
Pulsando Continuar y Aceptar se obtiene el gráfico de los residuos. En esta figura, interpretamos el gráfico que aparece en la fila 3 columna 2, es decir aquel gráfico que se representan los residuos en el eje de ordenadas y los valores pronosticados en el eje de abscisas. No observamos, en dicho gráfico, ninguna tendencia sistemática que haga sospechar del incumplimiento de la suposición de independencia.
También, podemos realizar un gráfico de dispersión de los residuos y las predicciones, para ello, tenemos que guardar los valores predichos. Se selecciona, en la ventana Univariante /Guardar. En la ventana resultante se selecciona Valores pronosticados No tipificados. Se pulsa Continuar y Aceptar y en el Editor de datos se ha creado una nueva variable PRE_1 que contiene los valores predichos por el modelo. Realizamos el gráfico de dispersión, para ello se selecciona en el menú principal, Gráficos/Cuadros de diálogos antiguos/Diagramas/Puntos
Y en la salida correspondiente seleccionar Dispersión simple y pulsar Definir
se introduce en el Eje Y: Residuos y el Eje X: Valores predichos. Se pulsa Aceptar
Hipótesis de homocedasticidad
En primer lugar comprobamos la homocedasticidad gráficamente, para ello se selecciona en el menú principal, Gráficos/Cuadros de diálogos antiguos/Barras de error…
Y en la salida correspondiente seleccionar Simple y pulsar Definir
se introduce en el campo Variable: La variable respuesta Concentración_CO y en el campo Eje de categorías: el factor Día_semana. En Las barras representan se selecciona Desviación típica, en Multiplicador: 2 (nos interesa que la desviación típica esté multiplicada por dos). Se pulsa Aceptar.
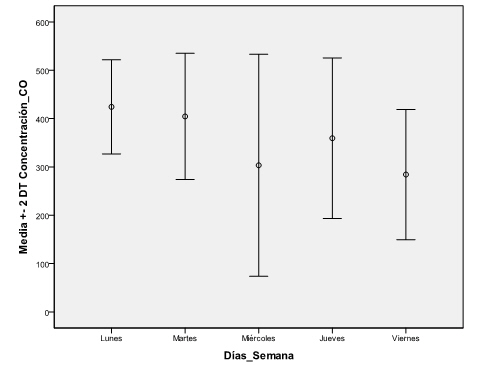 Cada grupo tiene su promedio (el círculo en cada una de las barras) y dos desviaciones típicas a la izquierda y dos desviaciones típicas a la derecha del promedio. Observamos que el miércoles hay mucha más dispersión que el resto de los días y donde hay menos dispersión es el lunes, la dispersión del martes y viernes son muy similares. Del gráfico no se deduce directamente si hay homogeneidad en estas varianzas, por lo que recurrimos analizar la heterocedasticidad analíticamente mediante el test de Levene.
Cada grupo tiene su promedio (el círculo en cada una de las barras) y dos desviaciones típicas a la izquierda y dos desviaciones típicas a la derecha del promedio. Observamos que el miércoles hay mucha más dispersión que el resto de los días y donde hay menos dispersión es el lunes, la dispersión del martes y viernes son muy similares. Del gráfico no se deduce directamente si hay homogeneidad en estas varianzas, por lo que recurrimos analizar la heterocedasticidad analíticamente mediante el test de Levene.
Para realizar el test de Levene mediante SPSS, en la ventana de ANOVA de un factor… pulsar Opciones
Se selecciona Prueba de homogeneidad de las varianzas y Gráfico de las medias. Se pulsa Continuar y Aceptar
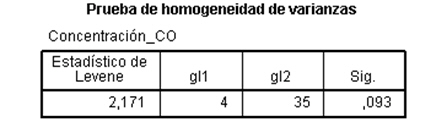 El p-valor es 0.093 por lo tanto no se puede rechazar la hipótesis de homogeneidad de las varianzas y se concluye que los cinco grupos tienen varianzas homogéneas. Si esta prueba sale significativa, es decir si la homocedasticidad no se cumple, en ese caso SPSS dispone de pruebas alternativas para realizar los contrastes de Comparaciones Múltiples que veremos en los contrastes Post-hoc.
El p-valor es 0.093 por lo tanto no se puede rechazar la hipótesis de homogeneidad de las varianzas y se concluye que los cinco grupos tienen varianzas homogéneas. Si esta prueba sale significativa, es decir si la homocedasticidad no se cumple, en ese caso SPSS dispone de pruebas alternativas para realizar los contrastes de Comparaciones Múltiples que veremos en los contrastes Post-hoc.
Una vez comprobado que se verifican las hipótesis del modelo se puede interpretar la tabla ANOVA. Si alguna de las hipótesis de homocedasticidad e independencia fallase no debería aplicarse el ANOVA, en cuanto a la hipótesis de Normalidad hay que tener en cuenta que las pruebas ANOVA son robustas ante leves desviaciones de la normalidad.
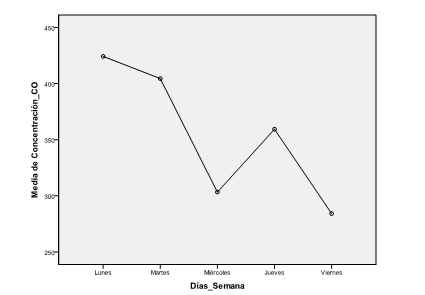 Antes de resolver el contraste de igualdad de medias observemos este gráfico de medias, donde en el eje de ordenadas figuran las concentraciones medias de CO y en el eje de abscisas los días de la semana. En esta gráfica observamos que la mayor concentración de CO se produce el lunes y las más bajas el miércoles y el viernes, siendo la concentración de este último la menor. Para saber entre que parejas de días estas diferencias son significativas aplicamos una prueba Post-hoc.
Antes de resolver el contraste de igualdad de medias observemos este gráfico de medias, donde en el eje de ordenadas figuran las concentraciones medias de CO y en el eje de abscisas los días de la semana. En esta gráfica observamos que la mayor concentración de CO se produce el lunes y las más bajas el miércoles y el viernes, siendo la concentración de este último la menor. Para saber entre que parejas de días estas diferencias son significativas aplicamos una prueba Post-hoc.
Comparaciones múltiples
En Analizar/Comparar medias/ANOVA de un factor… pulsamos en Post_hoc…
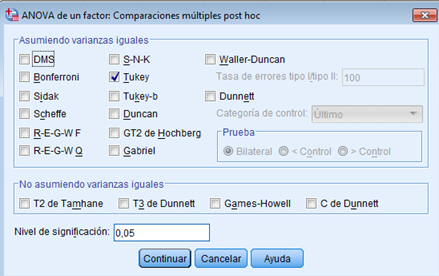
En la ventana resultante seleccionamos, por ejemplo, Tukey. Si no se verifica la hipótesis homocedasticidad se tiene que utilizar una de las pruebas que figura en No asumiendo varianzas iguales. Se pulsa Continuar y Aceptar
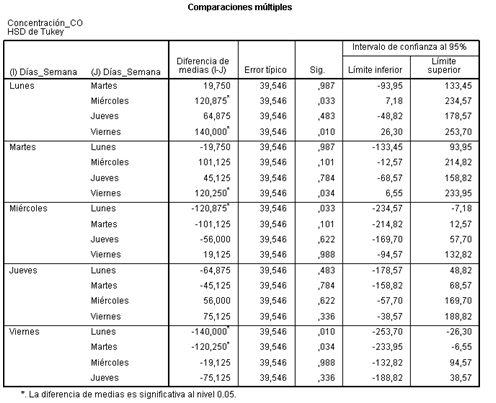 Esta salida nos muestra los intervalos de confianza simultáneos construidos por el método de Tukey. En la tabla se muestra un resumen de las comparaciones de cada tratamiento con los restantes. Es decir, aparecen comparadas dos a dos las cinco medias de los tratamientos. En el primer bloque de la tabla se muestran comparadas la media del lunes con la media de los otros cuatro días de la semana. En los siguientes bloques se muestran comparadas las restantes medias entre sí. En la columna Diferencias de medias (I-J) se muestran las diferencias entre las medias que se comparan.
Esta salida nos muestra los intervalos de confianza simultáneos construidos por el método de Tukey. En la tabla se muestra un resumen de las comparaciones de cada tratamiento con los restantes. Es decir, aparecen comparadas dos a dos las cinco medias de los tratamientos. En el primer bloque de la tabla se muestran comparadas la media del lunes con la media de los otros cuatro días de la semana. En los siguientes bloques se muestran comparadas las restantes medias entre sí. En la columna Diferencias de medias (I-J) se muestran las diferencias entre las medias que se comparan.
En la columna Sig. aparecen los p-valores de los contrastes, que permiten conocer si la diferencia entre cada pareja de medias es significativa al nivel de significación considerado (en este caso 0.05) y la última columna proporciona los intervalos de confianza al 95% para cada diferencia. Así por ejemplo, si comparamos la concentración media de CO del Lunes con el Martes, tenemos una diferencia entre ambas medias de 19.750, un error típico de 39.546, que es un error típico para la diferencia de estas medias, un P-valor (Sig.) de 0.987 no significativo puesto que la concentración de CO no difiere significativamente el lunes del martes y un intervalo de confianza con un límite inferior negativo y un límite superior positivo y por lo tanto contiene al cero de lo que también deducimos que no hay diferencias significativas entre los dos grupos que se comparan o que ambos grupos son homogéneos. En cambio si observamos el grupo formado por el Lunes y el Miércoles, vemos que ambos extremos del intervalo son del mismo signo y el P-valor es significativo deduciendo que si hay diferencias significativas entre ambos. Ya se había observado que la concentración media de CO el miércoles era muy inferior al lunes, de hecho el valor de la diferencia de medias es 120.875. Las otras comparaciones se interpretan de forma análoga.
Por lo tanto la tabla se interpreta observando los valores de Sig menores que el 5%, o si el intervalo de confianza contiene al cero. Además, los contrastes que sí han resultado significativos al nivel de significación 0.05 aparecen marcados con asterisco. Concluimos que se detectan diferencias significativas en las concentraciones de CO entre lunes y miércoles; lunes y viernes; martes y viernes.
Para que se pueda analizar esta tabla más fácilmente, trasladamos la columna Sig a la primera columna, para ello hacemos doble Click en cualquier lugar de la tabla, nos posicionamos en la cabecera de la columna de Sig. y con el botón izquierdo del ratón la arrastramos al lugar que queramos (primera posición) y allí la soltamos. Aparecen dos opciones: Insertar antes e Intercambiar.
 Seleccionamos Insertar antes, y se muestra la salida se la siguiente forma
Seleccionamos Insertar antes, y se muestra la salida se la siguiente forma
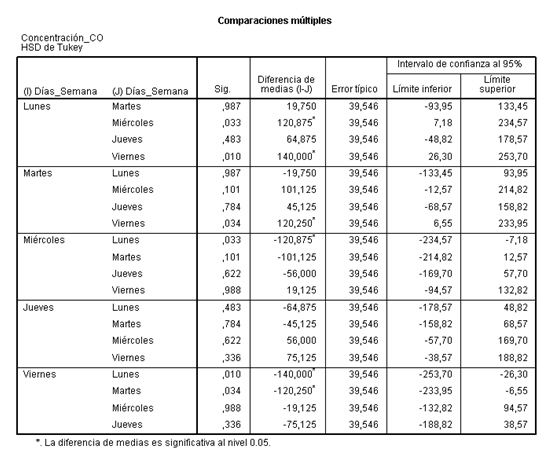 En el menú principal seleccionamos Pivotar/Paneles de pivotado
En el menú principal seleccionamos Pivotar/Paneles de pivotado
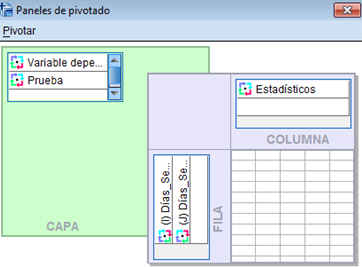 Los Días_Semana están en fila y los arrastramos para que figuren en columnas, quedando la siguiente tabla
Los Días_Semana están en fila y los arrastramos para que figuren en columnas, quedando la siguiente tabla
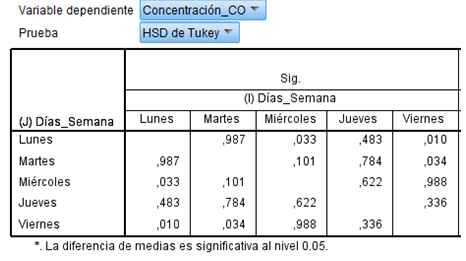 De esta forma es más cómodo comparar cualquier pareja de días para saber si hay diferencias significativas. De la tabla se deduce, como vimos anteriormente, que hay diferencias significativas entre lunes y miércoles, lunes y viernes, martes y viernes.
De esta forma es más cómodo comparar cualquier pareja de días para saber si hay diferencias significativas. De la tabla se deduce, como vimos anteriormente, que hay diferencias significativas entre lunes y miércoles, lunes y viernes, martes y viernes.
Además de la tabla de Comparaciones múltiples también se muestra una tabla de subconjuntos homogéneos
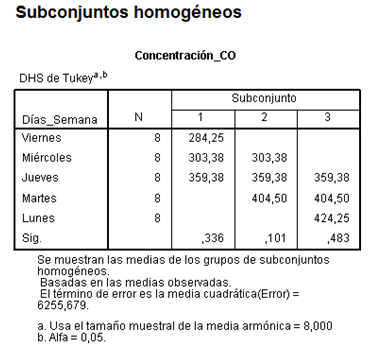 La tabla de subconjuntos homogéneos muestra por columnas los subgrupos de medias iguales, formados al utilizar el método de Tukey. Se llama Prueba de subgrupos homogéneos por que se agrupan en columnas aquellos grupos que no difieren significativamente. Se observa que la prueba de Tukey ha agrupado los días viernes, miércoles y jueves en una misma columna; miércoles, jueves y martes en otra columna y jueves, martes y lunes en una tercera columna. De esta forma gráfica deducimos que subgrupos son homogéneos y cuales difieren significativamente.
La tabla de subconjuntos homogéneos muestra por columnas los subgrupos de medias iguales, formados al utilizar el método de Tukey. Se llama Prueba de subgrupos homogéneos por que se agrupan en columnas aquellos grupos que no difieren significativamente. Se observa que la prueba de Tukey ha agrupado los días viernes, miércoles y jueves en una misma columna; miércoles, jueves y martes en otra columna y jueves, martes y lunes en una tercera columna. De esta forma gráfica deducimos que subgrupos son homogéneos y cuales difieren significativamente.
Los subgrupos homogéneos son los formados por: viernes, miércoles y jueves; miércoles, jueves y martes y jueves, martes y lunes. De hecho, por ejemplo, si comparamos en el primer subconjunto, los tres primeros grupos el P-valor (Sig.) es 0.336 mayor que el nivel de significación 0.05 deduciendo que no hay diferencias significativas en la concentración media de CO entre estos tres.
También se deduce qué subconjuntos difieren significativamente entre sí. La concentración de CO en el primer subconjunto difiere de la concentración en el segundo y de la concentración en el tercero y dentro de estos subconjuntos no se aprecian diferencias significativas entre las concentaciones implicadas.También se observa que la concentración media de CO es mayor los lunes (424,25) y menor los viernes (284,25).
Veamos estas diferencias de una forma gráfica, para ello se selecciona en el menú principal, Gráficos/Generador de gráficos…
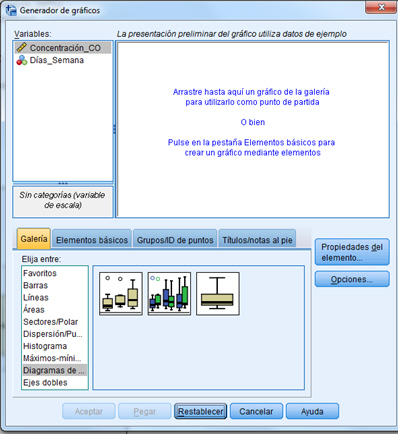
Se selecciona el Diagrama de cajas y se arrastra el diagrama de caja simple (el primer gráfico) a la ventana que hay encima. Se pulsa Aceptar

Se sitúa Días_Semana en el eje X y la Concentración_CO en el eje Y
Se pulsa Aceptar y se obtiene la siguiente salida
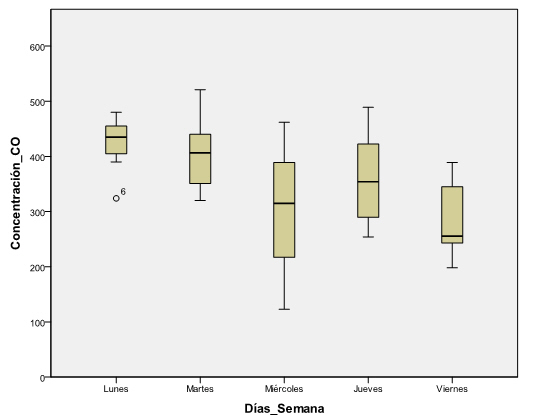 Observamos que las cajas correspondientes a los miércoles, jueves y viernes están prácticamente superpuestas, de hecho el valor mediano del miércoles (línea negra dentro de las cajas) está a un nivel interno dentro de la caja del jueves y de la caja del vierne. Este criterio se utiliza para comparar grupos y en este caso nos indica que hay homogeneidad o que no hay diferencias significativas en ese grupo de medias. Observamos que el lunes tiene una distribución superior a los demás, por lo que concluimos que la concentración de CO es mucho mayor este día de la semana.
Observamos que las cajas correspondientes a los miércoles, jueves y viernes están prácticamente superpuestas, de hecho el valor mediano del miércoles (línea negra dentro de las cajas) está a un nivel interno dentro de la caja del jueves y de la caja del vierne. Este criterio se utiliza para comparar grupos y en este caso nos indica que hay homogeneidad o que no hay diferencias significativas en ese grupo de medias. Observamos que el lunes tiene una distribución superior a los demás, por lo que concluimos que la concentración de CO es mucho mayor este día de la semana.
Contrastes
Se denomina Contraste a toda combinación lineal C, de los parámetros del modelo de análisis de la varianza de la forma
 Se utilizan para comparar tratamientos entre sí o grupos de tratamientos, así por ejemplo:
Se utilizan para comparar tratamientos entre sí o grupos de tratamientos, así por ejemplo:
- Para comparar dos días entre sí, por ejemplo el lunes y jueves el contraste debe tener los siguientes coeficientes:
![]() Es decir, los coeficientes de las dos categorías que se van a comparar deben sumar cero y los días que no se van a comparar deben tener un coeficiente de 0
Es decir, los coeficientes de las dos categorías que se van a comparar deben sumar cero y los días que no se van a comparar deben tener un coeficiente de 0
- Para comparar grupos de días, por ejemplo el grupo formado por el lunes y miércoles con el formado por el martes y viernes, en este caso los coeficientes deben ser
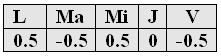 Los coeficientes de los grupos que se comparan deben sumar uno de ellos 1 y el otro -1 y la suma de todos los coeficientes debe ser cero.
Los coeficientes de los grupos que se comparan deben sumar uno de ellos 1 y el otro -1 y la suma de todos los coeficientes debe ser cero.
- Para realizar el contraste:
![]() Los coeficientes deben ser
Los coeficientes deben ser
![]() Para realizar estos contrastes con SPSS, se selecciona Analizar/Comparar medias/ANOVA de un factor… y se pulsa en Contrastes…
Para realizar estos contrastes con SPSS, se selecciona Analizar/Comparar medias/ANOVA de un factor… y se pulsa en Contrastes…
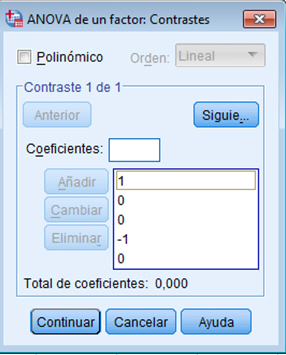
Para el primer contraste, en Coeficientes se pone 1, 0, 0, -1, 0.
Como hay cinco tratamientos deben figurar cinco números indicando los 0 las categorías que no se comparan.
Si queremos realizar otro contraste pulsamos Siguie_ e introducimos los coeficientes del segundo contraste
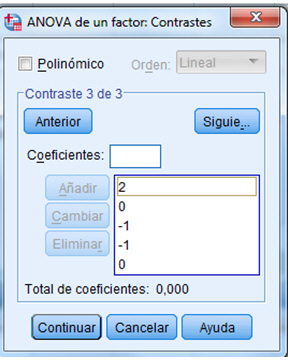
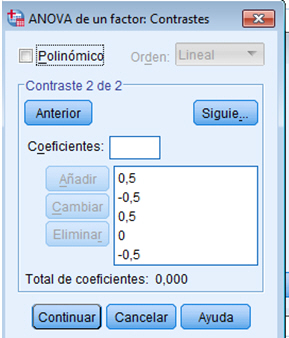 pulsamos Siguie_ e introducimos los coeficientes del tercer contraste.
pulsamos Siguie_ e introducimos los coeficientes del tercer contraste.
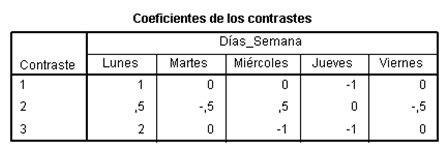
 Se pulsa Continuar y Aceptar y se muestra la tabla de contrastes con los coeficientes indicando los contrastes que se van a realizar
Se pulsa Continuar y Aceptar y se muestra la tabla de contrastes con los coeficientes indicando los contrastes que se van a realizar
Y la prueba t para los contrastes
 Para interpretar la tabla, asumimos en todos los contrastes la homocedasticidad, aunque sólo la hemos comprobado para cada uno de los tratamientos y no lo hemos hecho en grupos de tratamientos.
Para interpretar la tabla, asumimos en todos los contrastes la homocedasticidad, aunque sólo la hemos comprobado para cada uno de los tratamientos y no lo hemos hecho en grupos de tratamientos.
Observamos que para el primer contraste, las concentraciones de CO para el lunes y jueves ha dado no significativo, P-valor es 0.110.
En el segundo contraste se quiere comparar las concentraciones de CO de lunes y miércoles en conjunto con las concentraciones de CO el martes y viernes también en conjunto, en este contraste el P-valor es 0.492 por lo tanto no hay diferencias significativas entre los dos grupos comparados.
En el tercer contraste se quiere comprobar si el lunes hay el doble de concentración de CO que el miércoles y jueves conjuntamente. El P-valor es 0.010 por lo tanto se rechaza la hipótesis nula y se deduce que la concentración de CO el lunes difiere significativamente del promedio de las concentraciones del miércoles y el jueves.
Diseño Unifactorial de efectos aleatorios
En el modelo de efectos aleatorios, los niveles del factor son una muestra aleatoria de una población de niveles. Este modelo surge ante la necesidad de estudiar un factor que presenta un número elevado de posibles niveles, que en algunas ocasiones puede ser infinito. En este modelo las conclusiones obtenidas se generalizan a toda la población de niveles del factor, ya que los niveles empleados en el experimento fueron seleccionados al azar. El estudio de este diseño lo vamos a realizar mediante el siguiente supuesto práctico.
Supuesto práctico 2
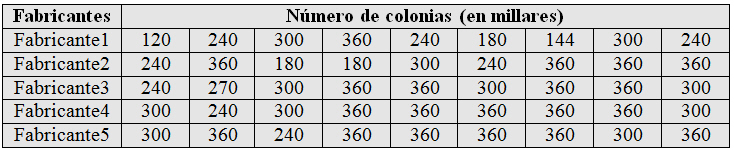
Los medios de cultivo bacteriológico en los laboratorios de los hospitales proceden de diversos fabricantes. Se sospecha que la calidad de estos medios de cultivo varía de un fabricante a otro. Para comprobar esta teoría, se hace una lista de fabricantes de un medio de cultivo concreto, se seleccionan aleatoriamente los nombres de cinco de los que aparecen en la lista y se comparan las muestras de los instrumentos procedentes de éstos. La comprobación se realiza colocando sobre una placa dos dosis, en gotas, de una suspensión medida de un microorganismo clásico, Escherichia coli, dejando al cultivo crecer durante veinticuatro horas, y determinando después el número de colonias (en millares) del microorganismo que aparecen al final del período. Se quiere comprobar si la calidad del instrumental difiere entre fabricantes.
Supuestos del modelo
-
Las cinco muestras representan muestras aleatorias independientes extraídas de I poblaciones seleccionadas aleatoriamente de unconjunto mayor de poblaciones.
-
Todas las poblaciones del conjunto más amplio tienen distribución Normal, de modo que cada una de las 5 poblaciones muestreadas se distribuyen segun una Normal.
-
Todas las poblaciones del conjunto más amplio tienen la misma varianza, y por lo tanto, cada una de las 5 poblaciones muestreadas tiene también varianza σ2.
-
Las variables τi son variables aleatorias normales independientes,cada una con media 0 y varianza común
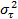 .
.
El modelo matemático de este diseño y los tres primeros supuestos del modelo son semejantes a los del modelo de efectos fijos. Sin embargo, el supuesto 4 expresa matemáticamente una importante diferencia entre los dos. En el modelo de efectos fijos, el experimentador elige los tratamientos o niveles del factor utilizados en el experimento. Si se replicase el experimento, se utilizarían los mismos tratamientos. Es decir, se muestrearían las mismas poblaciones cada vez y los I efectos del tratamiento τi = μi – μ no variarían. Esto implica que en el modelo de efectos fijos, estos I términos se consideran constantes desconocidas. En el modelo de efectos aleatorios se seleccionan aleatoriamente I poblaciones, las elegidas variarán de replicación en replicación. De este modo, en este modelo los I términos μi – μ no son constantes, son variables aleatorias, cuyos valores para una determinada réplica depende de la elección de las I poblaciones a estudiar. En este modelo estas variables τi se suponen variables aleatorias normales independientes con media 0 y varianza común ![]() . Además este modelo requiere que las variables τi y uij sean independientes. Así, por la independencia de estas variables, la varianza de cualquier observación de la muestra, es decir, la varianza total, vale
. Además este modelo requiere que las variables τi y uij sean independientes. Así, por la independencia de estas variables, la varianza de cualquier observación de la muestra, es decir, la varianza total, vale
![]()
La mecánica del Análisis de la Varianza es la misma que en el modelo de efectos fijos. En este modelo, carece de sentido probar la hipótesis que se refiere a los efectos de los tratamientos individuales. Si las medias poblacionales en el conjunto mayor son iguales, no variarán los efectos del tratamiento τi, es decir, ![]() . Así en el modelo de efectos aleatorios, la hipótesis de medias iguales se contrasta considerando:
. Así en el modelo de efectos aleatorios, la hipótesis de medias iguales se contrasta considerando:
![]() Si no se rechaza H0, significa que no hay variedad en los efectos de los tratamientos.
Si no se rechaza H0, significa que no hay variedad en los efectos de los tratamientos.
En el supuesto práctico 2:
- Variable respuesta: Calidad_Instrumental
- Factor: Fabricante. Es un factor de efectos aleatorios, se han elegido aleatoriamente a cinco fabricantes, que constituyen únicamente una muestra de todos los fabricantes y el propósito no es comparar estos cinco fabricantes sino contrastar el supuesto general de que la calidad del instrumental difiere entre fabricantes.
- Modelo equilibrado: Los niveles de los factores tienen el mismo número de elementos (9 elementos).
- Tamaño del experimento: Número total de observaciones, en este caso 45 unidades experimentales.
El problema planteado se modeliza a través de un diseño unifactorial totalmente aleatorizado de efectos aleatorios equilibrado.
Para realizarlo mediante SPSS, se comienza definiendo las variables e introduciendo los datos:
- Nombre: Calidad_Instrumental ; Tipo: Numérico ; Anchura: 3 ; Decimales: 0
- Nombre: Fabricante ; Tipo: Numérico ; Anchura: 8 ; Decimales: 0 ; Valores: { 1, Fabricante1; 2, Fabricante2; 3, Fabricante3; 4, Fabricante4; 5, Fabricante 5}
Se quiere comprobar si la calidad del instrumental difiere entre fabricantes, por lo que hay que resolver el contraste mencionado anteriormente, para ello, se selecciona, en el menú principal, Analizar/Modelo lineal general/Univariante… En la salida correspondiente, se introduce en el campo Variable dependiente: La variable respuesta Calidad_Instrumental y en el campo Factores aleatorios: el factor Fabricante. Pulsando Aceptar se obtiene la Tabla ANOVA
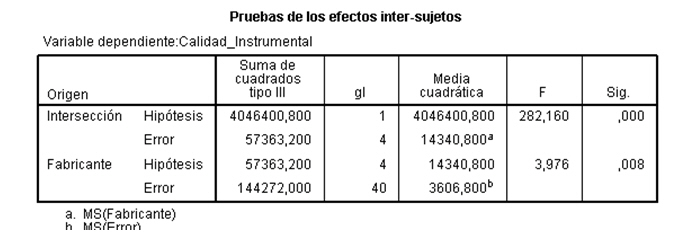
Esta tabla muestra los resultados del contraste planteado. El valor del estadístico de contraste es igual a 3.976 que deja a la derecha un p-valor de 0.008, así que la respuesta dependerá del nivel de significación que se fije. Si fijamos un nivel de significación de 0.05 se concluye que hay evidencia suficiente para afirmar la existencia de alguna variabilidad entre la calidad del material de los diferentes fabricantes. Si fijamos un nivel de significación de 0.001, no podemos hacer tal afirmación.
En el modelo de efectos aleatorios no se necesitan llevar a cabo más contrastes incluso aunque la hipótesis nula sea rechazada. Es decir, en el caso de rechazar H0 no hay que realizar comparaciones múltiples para comprobar que medias son distintas, ya que el propósito del experimento es hacer un planteamiento general relativo a las poblaciones de las que se extraen las I muestras.
La tabla siguiente muestra la media cuadrática esperada, de esta tabla se deducen las expresiones de las esperanzas de los cuadrados medios del factor y del error:
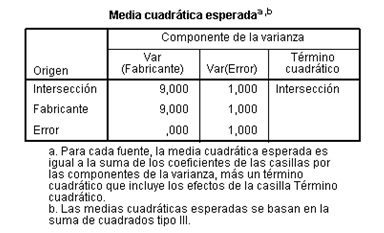 |
|
Estas expresiones se utilizan para estimar las componentes de la varianza ![]() y σ2. Para determinar el valor concreto de estas estimaciones mediante SPSS, se selecciona, en el menú principal Analizar/Modelo lineal general/Componentes de la varianza… En la salida correspondiente, se introduce en el campo Variable dependiente: La variable respuesta Calidad_Instrumental y en el campo Factores aleatorios: el factor Fabricante. Pinchando en Opciones
y σ2. Para determinar el valor concreto de estas estimaciones mediante SPSS, se selecciona, en el menú principal Analizar/Modelo lineal general/Componentes de la varianza… En la salida correspondiente, se introduce en el campo Variable dependiente: La variable respuesta Calidad_Instrumental y en el campo Factores aleatorios: el factor Fabricante. Pinchando en Opciones
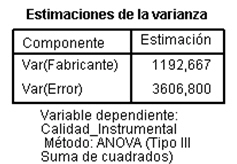
Se elige ANOVA en Método y en Sumas de Cuadrados el tipo III (Método que consiste en igualar los cuadrados medios con sus esperanzas). Pulsando Continuar y Aceptar se obtiene las estimaciones de los componentes de la varianza. Donde
![]() Por lo tanto, la varianza total (4799.467) se descompone en una parte atribuible a la diferencia entre los fabricantes (1192.667) y otra procedente de la variabilidad existente dentro de ellos (3606.8). Comprobamos que en dicha varianza tiene mayor peso la variación dentro de los fabricantes, en porcentaje un 75.15 % frente a la variación entre fabricantes, que representa el 24.85 % del total.
Por lo tanto, la varianza total (4799.467) se descompone en una parte atribuible a la diferencia entre los fabricantes (1192.667) y otra procedente de la variabilidad existente dentro de ellos (3606.8). Comprobamos que en dicha varianza tiene mayor peso la variación dentro de los fabricantes, en porcentaje un 75.15 % frente a la variación entre fabricantes, que representa el 24.85 % del total.
Diseño en Bloques Aleatorizados
En los diseños estudiados anteriormente hemos supuesto que existe bastante homogeneidad entre las unidades experimentales. Pero puede suceder que dichas unidades experimentales sean heterogéneas y contribuyan a la variabilidad observada en la variable respuesta. Si en esta situación se utiliza un diseño completamente aleatorizado, no sabremos si la diferencia entre dos unidades experimentales sometidas a distintos tratamientos se debe a una diferencia real entre los efectos de los tratamientos o a la heterogeneidad de dichas unidades. Como resultado, el error experimental reflejará esta variabilidad. En esta situación se debe sustraer del error experimental la variabilidad producida por las unidades experimentales y para ello el experimentador puede formar bloques de manera que las unidades experimentales de cada bloque sean lo más homogéneas posible y los bloques entre sí sean heterogéneos.
En el diseño en bloques Aleatorizados, primero se clasifican las unidades experimentales en grupos homogéneos, llamados bloques, y los tratamientos son entonces asignados aleatoriamente dentro de los bloques. Esta estrategia de diseño mejora efectivamente la precisión en las comparaciones al reducir la variabilidad residual.
Distinguimos dos tupos de diseños en bloques aleatorizados:
- Los diseños en bloques completos aleatorizados (Todos los tratamientos se prueban en cada bloque exactamente vez).
- Los diseños por bloques incompletos aleatorizados (Todos los tratamientos no están representados en cada bloque, y aquellos que sí están en uno en particular se ensayan en él una sola vez).
Diseño en Bloques Completos Aleatorizados
En esta sección presentamos el diseño completo aleatorizado con efectos fijos. La palabra bloque se refiere al hecho de que se ha agrupado a las unidades experimentales en función de alguna variable extraña; aleatorizado se refiere al hecho de que los tratamientos se asignan aleatoriamente dentro de los bloques; completo implica que se utiliza cada tratamiento exactamente una vez dentro de cada bloque y el término efectos fijos se aplica a bloques y tratamientos. Es decir, se supone que ni los bloques ni los tratamientos se eligen aleatoriamente. Además una caracterización de este diseño es que los efectos bloque y tratamiento son aditivos; es decir no hay interacción entre los bloques y los tratamientos.
La descripción del diseño así como la terminología subyacente la vamos a introducir mediante el siguiente supuesto práctico.
Supuesto práctico 3
El Abeto blanco, Abeto del Pirineo, es un árbol de gran belleza por la elegancia de sus formas y el exquisito perfume balsámico que destilan sus hojas y cortezas. Destilando hojas y madera se obtiene aceite de trementina muy utilizado en medicina contra torceduras y contusiones. En estos últimos años se ha observado que la producción de semillas ha descendido y con objeto de conseguir buenas producciones se proponen tres tratamientos. Se observa que árboles diferentes tienen distintas características naturales de reproducción, este efecto de las diferencias entre los árboles se debe de controlar y este control se realiza mediante bloques. En el experimento se utilizan 10 abetos, dentro de cada abeto se seleccionan tres ramas semejantes. Cada rama recibe exactamente uno de los tres tratamientos que son asignados aleatoriamente. Constituyendo cada árbol un bloque completo. Los datos obtenidos se presentan en la siguiente tabla donde se muestra el número de semillas producidas por rama.

El objetivo del estudio es comparar los tres tratamientos, por lo que se trata de un factor con tres niveles. Sin embargo, al realizar la medición sobre los distintos abetos, es posible que estos influyan sobre el número se semillas observadas. Por ello, y al no ser directamente motivo de estudio, los abetos es un factor secundario que recibe el nombre de bloque.
Nos interesa saber si los distintos tratamientos influyen en la producción de semillas, para ello realizamos el siguiente contraste de hipótesis:
![]() Es decir, contrastamos que no hay diferencia en las medias de los tres tratamientos frente a la alternativa de que al menos una media difiere de otra.
Es decir, contrastamos que no hay diferencia en las medias de los tres tratamientos frente a la alternativa de que al menos una media difiere de otra.
Pero, previamente hay que comprobar si la presencia del factor bloque (los abetos) está justificada. Para ello, realizamos el siguiente contraste de hipótesis:
![]() Es decir, contrastamos que no hay diferencia en las medias de los diez bloques frente a la alternativa de que al menos una media difiere de otra.
Es decir, contrastamos que no hay diferencia en las medias de los diez bloques frente a la alternativa de que al menos una media difiere de otra.
Este experimento se modeliza mediante un diseño en bloques completos al azar. El modelo matemático es:
![]()
La fórmula expresa simbólicamente la idea de que cada observación yij (Número de semillas medida con el tratamiento i, del abeto j ), puede subdividirse en cuatro componentes: un efecto medio global μ, un efecto tratamiento τi (efecto del factor principal sobre el número de semillas), un efecto bloque βj (efecto del factor secundario (abetos) sobre el número de semillas) y una desviación aleatoria debida a causas desconocidas uij (Perturbaciones o error experimental). Este modelo tiene que verificar los siguientes supuestos:
-
Las 30 observaciones constituyen muestras aleatorias independientes, cada una de tamaño 3, de 30 poblaciones con medias μij, i=1, 2,…, 3 y j = 1, 2, .., 10.
-
Cada una de las 30 poblaciones es normal.
-
Cada una de las 30 poblaciones tiene la misma varianza.
-
Los efectos de los bloques y tratamientos son aditivos; es decir, no existe interacción entre los bloques y tratamientos. Esto significa que si hay diferencias entre dos tratamientos cualesquiera, estas se mantienen en todos los bloques (abetos).
Los tres primeros supuestos coinciden con los supuestos del modelo unifactorial, con la diferencia de que en el modelo unifactorial se examinaban I poblaciones y en este modelo se examinan IJ. El cuarto supuesto es característico del diseño en bloques. La no interacción entre los bloques y los tratamientos significa que los tratamientos tienen un comportamiento consistente a través de los bloques y que los bloques tienen un comportamiento consistente a través de los tratamientos. Expresado matemáticamente significa que la diferencia de los valores medios para dos tratamientos cualesquiera es la misma en todo un bloque y que la diferencia de los valores medios para dos bloques cualesquiera es la misma para cada tratamiento.
- Variable respuesta: Número de semillas
- Factor: Tratamiento que tiene tres niveles. Es un factor de efectos fijos ya que viene decidido qué niveles concretos se van a utilizar.
- Bloque: Abeto que tiene diez niveles. Es un factor de efectos fijos ya que viene decidido qué niveles concretos se van a utilizar.
- Modelo completo: Los tres tratamientos se prueban en cada bloque exactamente una vez.
- Tamaño del experimento: Número total de observaciones (30).
Para realizar este experimento mediante SPSS, se comienza definiendo las variables e introduciendo los datos:
- Nombre: Número_semillas ; Tipo: Numérico ; Anchura: 2 ; Decimales: 0
- Nombre: Tratamientos ; Tipo: Numérico ; Anchura: 1 ; Decimales: 0
- Nombre: Abetos ; Tipo: Numérico ; Anchura: 1 ; Decimales: 0.
Para resolver los contrastes planteados, se selecciona, en el menú principal, Analizar/Modelo lineal general/ Univariante… En la salida correspondiente, se introduce en el campo Variable dependiente: La variable respuesta Número_semillas y en el campo Factores fijos: el factor Tratamientos y el bloque Abetos. Para indicar que se trata de un modelo sin interacción entre los tratamientos y los bloques, se debe pinchar en Modelo e indicar en la salida correspondiente que es un modelo aditivo.
Por defecto, SPSS tiene marcado un modelo Factorial completo, por lo que hay que señalar Personalizado. En el modelo que estamos estudiando sólo aparecen los efectos principales de los dos factores, por lo tanto se selecciona en Tipo: Efectos principales y se pasan los dos factores, Tratamientos y Abetos, al campo Modelo: Observamos que no hay distinción entre los dos factores, no se indica cual es el factor principal y cuál es el bloque. En el modelo matemático el tratamiento que se hace es el mimo para ambos factores, lo que cambia es la interpretación.
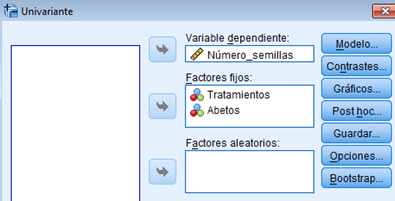
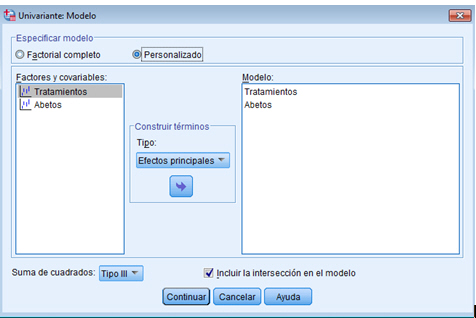
Pulsando Continuar y Aceptar se obtiene la Tabla ANOVA
Puesto que la construcción de bloques se ha diseñado para comprobar el efecto de una variable, nos preguntamos si ha sido eficaz su construcción. En caso afirmativo, la suma de cuadrados de bloques explicaría una parte sustancial de la suma total de cuadrados. También se reduce la suma de cuadrados del error dando lugar a un aumento del valor del estadístico de contraste experimental utilizado para contrastar la igualdad de medias de los tratamientos y posibilitando que se rechace la Hipótesis nula, mejorándose la potencia del contraste.
La construcción de bloques puede ayudar cuando se comprueba su eficacia pero debe evitarse su construcción indiscriminada. Ya que, la inclusión de bloques en un diseño da lugar a una disminución del número de grados de libertad para el error, aumenta el punto crítico para contrastar la Hipótesis nula y es más difícil rechazarla. La potencia del contraste es menor.
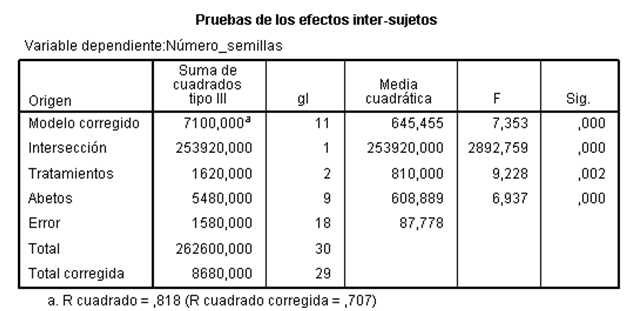
La Tabla ANOVA, muestra que:
-
El valor del estadístico de contraste de igualdad de bloques, F = 6.937 deja a su derecha un p-valor menor que 0.001, menor que el nivel de significación del 5%, por lo que se rechaza la Hipótesis nula de igualdad de bloques. La eficacia de este diseño depende de los efectos de los bloques. Un valor grande de F de los bloques (6.937) implica que el factor bloque tiene un efecto grande. En este caso el diseño es más eficaz que el diseño completamente aleatorizado ya que si el cuadrado medio entre bloques es grande (608.889), el término residual será mucho menor (87.778) y el contraste principal de las medias de los tratamientos será más sensible a las diferencias entre tratamientos. Por lo tanto la inclusión del factor bloque en el modelo es acertada. Así, la producción de semillas depende del abeto.
Si los efectos de los bloques son muy pequeños, el análisis de bloque quizás no sea necesario y en caso extremo, cuando el valor de F de los bloques es próximo a 1, puede llegar a ser perjudicial, ya que el número de grados de libertad, (I-1)(J-1 ), del denominador de la comparación de tratamientos es menor que el número de grados de libertad correspondiente, IJ-I, en el diseño completamente aleatorizado. Pero, ¿Cómo saber cuándo se puede prescindir de los bloques? La respuesta la tenemos en el valor de la F experimental de los bloques, se ha comprobado que si dicho valor es mayor que 3, no conviene prescindir de los bloques para efectuar los contrastes.
-
El valor del estadístico de contraste de igualdad de tratamiento, F = 9.228 deja a su derecha un p-valor de 0.002, menor que el nivel de significación del 5%, por lo que se rechaza la Hipótesis nula de igualdad de tratamientos. Así, los tratamientos influyen en el número de semillas. Es decir, existen diferencias significativas en el número de semillas entre los tres tratamientos.
La salida de SPSS también nos muestra que R cuadrado vale 0.818, indicándonos que el modelo explica el 81.80% de la variabilidad de los datos.
El modelo que hemos propuesto hay que validarlo, para ello hay que comprobar si se verifican los cuatros supuestos expresados anteriormente.
Estudio de la Idoneidad del modelo
Hipótesis de aditividad entre los bloques y tratamientos
La interacción entre el factor bloque y los tratamientos se puede estudiar gráficamente de diversas formas:
-
Gráfico de residuos frente a los valores predichos por el modelo. Si este gráfico no presenta ningún aspecto curvilíneo se admite que el modelo es aditivo. Este gráfico se puede realizar en SPSS de dos formas:
-
Seleccionamos Opciones en el cuadro de diálogo de Univariante y marcamos la casilla Gráfico de los residuos. Se pulsa, Continuar y Aceptar
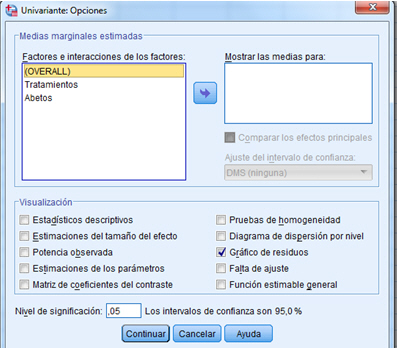
 Interpretamos el gráfico que aparece en la fila 3 columna 2, es decir aquel gráfico que se representan los residuos en el eje de ordenadas y los valores pronosticados en el eje de abscisas. No observamos, en dicho gráfico, ninguna tendencia curvilínea, es decir no muestra evidencia de interacción entre el factor bloque y los tratamientos.
Interpretamos el gráfico que aparece en la fila 3 columna 2, es decir aquel gráfico que se representan los residuos en el eje de ordenadas y los valores pronosticados en el eje de abscisas. No observamos, en dicho gráfico, ninguna tendencia curvilínea, es decir no muestra evidencia de interacción entre el factor bloque y los tratamientos.
-
Gráfico de dispersión de los residuos y las predicciones. Para realizar este gráfico, se selecciona, en el menú principal, Analizar/Modelo lineal general/ Univariante/Guardar… En la ventana resultante se selecciona Residuos No tipificados y Valores pronosticados No tipificados. Se pulsa, Continuar y Aceptar. Y en el Editor de datos se han creado dos nuevas variables RES_1 y PRE_1 que contienen los residuos del modelo y los valores predichos, respectivamente. Realizamos el gráfico de dispersión, para ello se selecciona en el menú principal, Gráficos/Cuadros de diálogos antiguos/Diagramas/Puntos
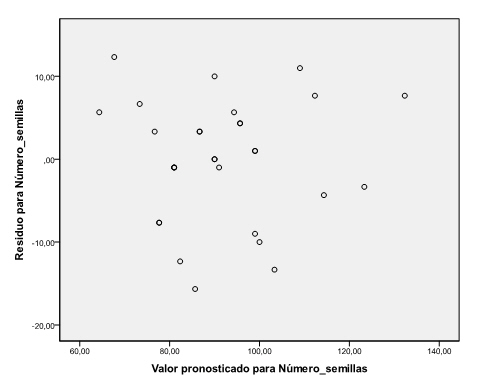
-
Gráfico de perfil: Es un gráfico de las medias de los tratamientos, para realizarlo se selecciona, en el menú principal, Analizar/Modelo lineal general/ Univariante/Gráficos… se introduce en el Eje horizontal: Tratamientos y en Líneas separadas: Abetos . Se pulsa Añadir, Continuar y Aceptar.
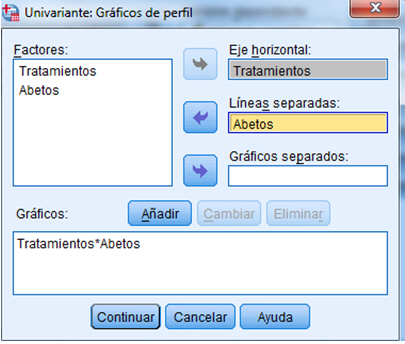

La figura representa el gráfico de las medias de los tratamientos. Cuando no existe interacción, los segmentos lineales que unen dos medias cualesquiera serán paralelos a través de los bloques. Es decir, es posible hacer consideraciones generales relativas a los tratamientos sin tener que especificar el bloque implicado. Podemos deducir, por ejemplo, que el tratamiento 1 es menos eficaz que los otros dos en el sentido que produce menos semillas. Cuando estos segmentos no son paralelos se deduce que hay interacción entre los bloques y tratamientos. Esto significa que debemos tener cuidado cuando hagamos declaraciones relativas a los tratamientos, porque el bloque implicado es también importante.
Hipótesis de normalidad
En primer lugar se deben salvar los residuos (procedimiento realizado anteriormente) y a continuación realizamos el estudio de la normalidad mediante el Gráfico probabilístico Normal y el Contraste de Kolmogorov-Smirnov
Gráfico probabilístico Normal: Se selecciona en el menú principal, Analizar/Estadísticos descriptivos/Gráficos Q-Q. Se introduce en el campo Variables: la variable que recoge los residuos RES_1. Se pulsa Aceptar
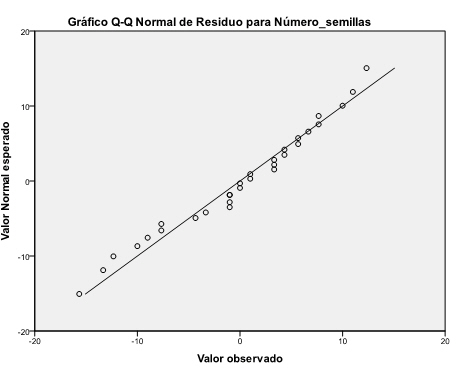
Podemos apreciar en este gráfico que los puntos aparecen próximos a la línea diagonal. Esta gráfica no muestra una desviación marcada de la normalidad.
Contraste de Kolmogorov-Smirnov: Se selecciona en el menú principal, Analizar/Pruebas no paramétricas/ Cuadros de diálogos antiguos/K-S de 1 muestra. Se introduce en el campo Lista Contrastar variables: la variable que recoge los residuos RES_1. Se pulsa Aceptar

El valor del p-valor, 0.544, es mayor que el nivel de significación 0.05, aceptándose la hipótesis de normalidad.
Independencia entre los residuos
En el gráfico de los residuos realizado anteriormente, interpretamos el gráfico que aparece en la fila 3 columna 2, es decir aquel gráfico en el que se representan los residuos en el eje de ordenadas y los valores pronosticados en el eje de abscisas. No observamos, en dicho gráfico, ninguna tendencia sistemática que haga sospechar del incumplimiento de la suposición de independencia. Este gráfico también lo podemos realizar mediante un diagrama de dispersión de los residuos y las predicciones. Procedimiento realizado anteriormente para comprobar la hipótesis de no interacción.
Homogeneidad de varianzas
En primer lugar comprobamos la homocedasticidad gráficamente, para ello se selecciona en el menú principal, Gráficos/Cuadros de diálogos antiguos/Barras de error… Y en la salida correspondiente seleccionar Simple y pulsar Definir. Se introduce en el campo Variable: La variable respuesta Número_semillas y en el campo Eje de categorías: el factor Tratamientos. En Las barras representan se selecciona Desviación típica, en Multiplicador: 2 (nos interesa que la desviación típica esté multiplicada por dos). Se pulsa Aceptar
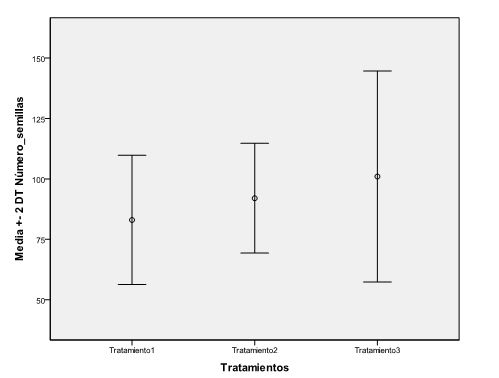 Cada grupo tiene su promedio (el círculo en cada una de las barras) y dos desviaciones típicas a la izquierda y dos desviaciones típicas a la derecha del promedio. Observamos que en el tratamiento3 hay mucha más dispersión que en los otros dos y donde hay menos dispersión es en el Tratamiento2. Del gráfico no se deduce directamente si hay homogeneidad en estas varianzas, por lo que recurrimos analizarlo analíticamente mediante una prueba el test de Levene.
Cada grupo tiene su promedio (el círculo en cada una de las barras) y dos desviaciones típicas a la izquierda y dos desviaciones típicas a la derecha del promedio. Observamos que en el tratamiento3 hay mucha más dispersión que en los otros dos y donde hay menos dispersión es en el Tratamiento2. Del gráfico no se deduce directamente si hay homogeneidad en estas varianzas, por lo que recurrimos analizarlo analíticamente mediante una prueba el test de Levene.
Realizamos el mismo gráfico para el factor bloque, para ello se introduce en el campo Eje de categorías: el factor Abetos.
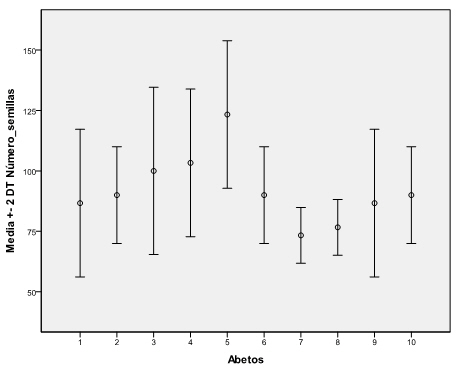 Observamos que en el Abeto 3 parece que hay mayor dispersión pero seguido a muy poca distancia del los Abetos 1, 4, 5 y 9 y donde hay menos dispersión es en los Abetos 7 y 8. Como en el gráfico anterior, no se deduce directamente si hay homogeneidad en estas varianzas, por lo que recurrimos analizarlo analíticamente mediante una prueba el test de Levene.
Observamos que en el Abeto 3 parece que hay mayor dispersión pero seguido a muy poca distancia del los Abetos 1, 4, 5 y 9 y donde hay menos dispersión es en los Abetos 7 y 8. Como en el gráfico anterior, no se deduce directamente si hay homogeneidad en estas varianzas, por lo que recurrimos analizarlo analíticamente mediante una prueba el test de Levene.
Para realizar el test de Levene mediante SPSS, Se selecciona, en el menú principal, Analizar/Comparar medias/ANOVA de un factor. En la salida correspondiente, se introduce en el campo Lista de dependientes: La variable respuesta Número_semillas y en el campo Factor: el factor Tratamientos. Se pulsa Opciones. Se selecciona Pruebas de homogeneidad de las varianzas y Gráfico de medias. Se pulsa Continuar y Aceptar
 El p-valor es 0.244 por lo tanto no se puede rechazar la hipótesis de homogeneidad de las varianzas y se concluye que los tres grupos tienen varianzas homogéneas.
El p-valor es 0.244 por lo tanto no se puede rechazar la hipótesis de homogeneidad de las varianzas y se concluye que los tres grupos tienen varianzas homogéneas.
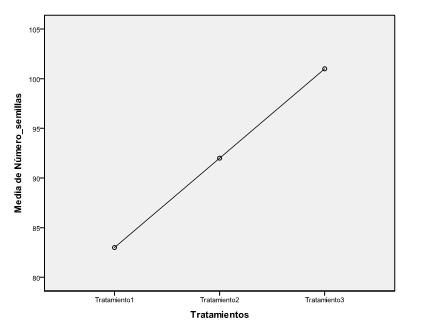 Antes de resolver el contraste de igualdad de medias observemos este gráfico de medias, donde en el eje de ordenadas figuran las medias del número de semillas y en el eje de abscisas los tratamientos. En esta gráfica observamos que la mayor concentración del número de semillas se produce en el Tratamiento3 y el número más bajo se produce con el Tratamiento1. Para saber entre que parejas de tratamientos estas diferencias son significativas aplicamos una prueba Post-hoc.
Antes de resolver el contraste de igualdad de medias observemos este gráfico de medias, donde en el eje de ordenadas figuran las medias del número de semillas y en el eje de abscisas los tratamientos. En esta gráfica observamos que la mayor concentración del número de semillas se produce en el Tratamiento3 y el número más bajo se produce con el Tratamiento1. Para saber entre que parejas de tratamientos estas diferencias son significativas aplicamos una prueba Post-hoc.
Realizamos el mismo contraste para los bloques, ya que hay que comprobar la homocedasticidad tanto en los tratamientos como en los bloques. En la ventana ANOVA de un factor, en la salida correspondiente, se introduce en el campo Lista de dependientes: Número_semillas y en el campo Factor: Abetos. Se pulsa Opciones y a continuación se selecciona Pruebas de homogeneidad de las varianzas. Se pulsa Continuar y Aceptar
 El p-valor es 0.518 por lo tanto no se puede rechazar la hipótesis de homogeneidad de las varianzas y se concluye que los diez grupos tienen varianzas homogéneas.
El p-valor es 0.518 por lo tanto no se puede rechazar la hipótesis de homogeneidad de las varianzas y se concluye que los diez grupos tienen varianzas homogéneas.
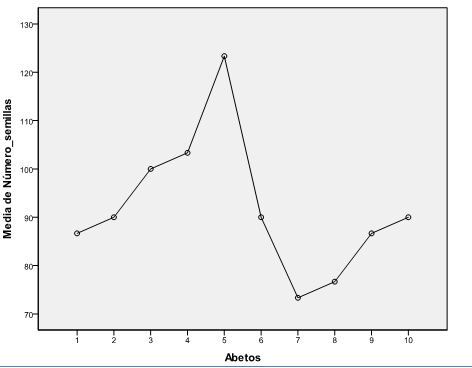
En esta gráfica observamos que la mayor concentración del número de semillas se produce en el Abeto5 y el número más bajo se produce en el Abeto7. Para saber entre que parejas de Abetos estas diferencias son significativas aplicamos una prueba Post-hoc.
Comparaciones múltiples
Se selecciona, en el menú principal, Analizar/Modelo lineal general/ Univariante… En la salida correspondiente, se introduce en el campo Variable dependiente: Número_semillas y en el campo Factores fijos: Tratamientos y Abetos. Para indicar que se trata de un modelo sin interacción entre los tratamientos y los bloques, se debe pinchar en Modelo e indicar en la salida correspondiente que es un modelo aditivo. Para ello, señalar Personalizado y en Tipo: Efectos principales y se pasan los dos factores, Tratamientos y Abetos, al campo Modelo. Se pulsa Continuar y Post_hoc… En la ventana resultante, se pasan las variables Tratamientos y Abetos al campo Pruebas posthoc para: y seleccionamos la prueba de Duncan. Se pulsa Continuar y Aceptar

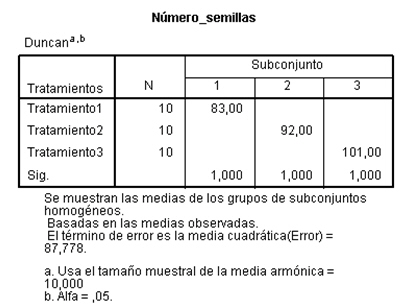 La tabla de subconjuntos homogéneos muestra por columnas los subgrupos de medias iguales, formados al utilizar el método de Duncan. Se observa que los tres tratamientos difieren significativamente entre sí. También se observa que la concentración media del número de semillas es mayor con el Tratamiento3 (101) y menor con el Tratamiento1 (83).
La tabla de subconjuntos homogéneos muestra por columnas los subgrupos de medias iguales, formados al utilizar el método de Duncan. Se observa que los tres tratamientos difieren significativamente entre sí. También se observa que la concentración media del número de semillas es mayor con el Tratamiento3 (101) y menor con el Tratamiento1 (83).
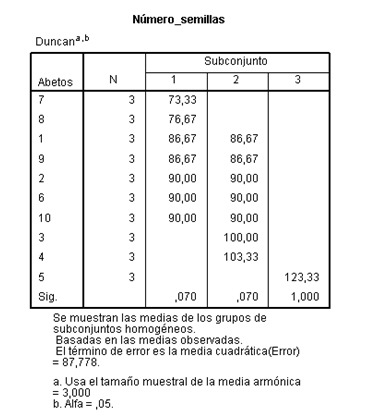 Se observa que la prueba de Duncan ha agrupado los abetos 7, 8, 1, 9, 2, 6 y 10 en una misma columna (P-valor 0.070, no hay diferencias significativas entre ellos), 1, 9 ,2 6, 10, 3 y 4 (P-valor 0.070, no hay diferencias significativas entre ellos) en otra columna y la tercera columna está formada únicamente por el Abeto5. Inmediatamente se ve que por ejemplo el Abeto5 difiere de todos los demás, siendo en este abeto donde se produce el mayor número de semillas (123.33)y el menor en el Abeto7.
Se observa que la prueba de Duncan ha agrupado los abetos 7, 8, 1, 9, 2, 6 y 10 en una misma columna (P-valor 0.070, no hay diferencias significativas entre ellos), 1, 9 ,2 6, 10, 3 y 4 (P-valor 0.070, no hay diferencias significativas entre ellos) en otra columna y la tercera columna está formada únicamente por el Abeto5. Inmediatamente se ve que por ejemplo el Abeto5 difiere de todos los demás, siendo en este abeto donde se produce el mayor número de semillas (123.33)y el menor en el Abeto7.
Diseño en bloques Incompletos Aleatorizados
En los diseños en bloques Aleatorizados, puede suceder que no sea posible realizar todos los tratamientos en cada bloque. En estos casos es posible usar diseños en bloques Aleatorizados en los que cada tratamiento no está presente en cada bloque. Estos diseños reciben el nombre de diseño en bloque incompleto aleatorizado siendo uno de los más utilizados el diseño en bloque incompleto balanceado (BIB)
El diseño de bloques incompletos balanceado (BIB) compara todos los tratamientos con igual precisión.
Este diseño experimental debe verificar:
-
Cada tratamiento ocurre el mismo número de veces en el diseño.
-
Cada par de tratamientos ocurren juntos el mismo número de veces que cualquier otro par.
Supongamos que se tienen I tratamientos de los cuales sólo pueden experimentar K tratamientos en cada bloque (K < I). Los parámetros que caracterizan este modelo son:
-
I, J y K son el número de tratamientos, el número de bloques y el número de tratamientos por bloque, respectivamente.
-
R, número de veces que cada tratamiento se presenta en el diseño, es decir el número de réplicas de un tratamiento dado.
-
λ , número de bloques en los que un par de tratamientos ocurren juntos.
-
N, número de observaciones.
Estos parámetros deben verificar las siguientes relaciones:
Estos parámetros deben verificar las siguientes relaciones:
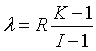 Fórmula: Relación en Bloques Incompletos
Fórmula: Relación en Bloques Incompletos
donde J ≥ I y N = I R = J K
- Si J = I el diseño recibe el nombre de simétrico.
Al igual que en el diseño en bloques completo, la asignación de los tratamientos a las unidades experimentales en cada bloque se debe realizar en forma aleatoria.
Este diseño lo estudiaremos a continuación mediante el supuesto práctico 4
Supuesto práctico 4
Se realiza un estudio para comprobar la efectividad en el retraso del crecimiento de bacterias utilizando cuatro soluciones diferentes para lavar los envases de la leche. El análisis se realiza en el laboratorio y sólo se pueden realizar seis pruebas en un mismo día. Como los días son una fuente de variabilidad potencial, el investigador decide utilizar un diseño aleatorizado por bloques, pero al recopilar las observaciones durante seis días no ha sido posible aplicar todos los tratamientos en cada día, sino que sólo se han podido aplicar dos de las cuatro soluciones cada día. Se decide utilizar un diseño en bloques incompletos balanceado, donde I = 4 y K = 2. Un posible diseño para estos parámetros lo proporciona la tabla correspondiente al Diseño 5 del Fichero-Adjunto, con R = 3, J = 6 y λ = 1. La disposición del diseño y las observaciones obtenidas se muestran en la siguiente tabla.
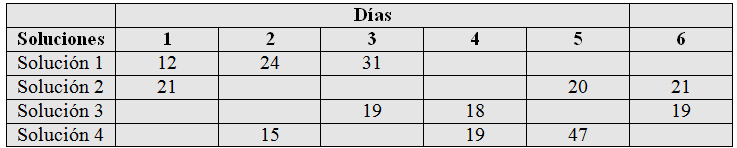
En el ejemplo:
• N = I R = J K. En efecto, ya que N= 12; I = 4, J = 6; R = 3 y K = 2.
• ![]()
El objetivo principal es estudiar la efectividad en el retraso del crecimiento de bacterias utilizando cuatro soluciones, por lo que se trata de un factor con cuatro niveles. Sin embrago, como los días son una fuente de variabilidad potencial, consideramos un factor bloque con seis niveles.
- Variable respuesta: Número de bacterias
- Factor: Soluciones que tiene cuatro niveles. Es un factor de efectos fijos ya que viene decidido qué niveles concretos se van a utilizar.
- Bloque: Días que tiene seis niveles. Es un factor de efectos fijos ya que viene decidido qué niveles concretos se van a utilizar.
- Modelo incompleto: Todos los tratamientos no se prueban en cada bloque.
- Tamaño del experimento: Número total de observaciones (12).
Para realizar este experimento mediante SPSS, se comienza definiendo las variables e introduciendo los datos:
-
Nombre: Número_bacterias ; Tipo: Numérico ; Anchura: 2 ; Decimales: 0
-
Nombre: Soluciones ; Tipo: Numérico ; Anchura: 1 ; Decimales: 0 ; • Valores: { 1, Solución1; 2, Solución2; 3, Solución3; 4, Solución4 }
-
Nombre: Días ; Tipo: Numérico ; Anchura: 1 ; Decimales: 0 .
Para resolver los contrastes planteados. Se selecciona, en el menú principal, Analizar/Modelo lineal general/ Univariante… En la salida correspondiente, se introduce en el campo Variable dependiente: Número_bacterias y en el campo Factores fijos: Soluciones y Días. Para indicar que se trata de un modelo sin interacción entre los tratamientos y los bloques, se debe pinchar en Modelo e indicar en la salida correspondiente que es un modelo aditivo.
En este tipo de diseño los tratamientos no estan en todos los bloques, entonces los bloques y tratamientos no son ortogonales (como lo son en el diseño de bloques completos al azar), por lo tanto no es posible realizar una descomposición de la variabilidad del experimento como en el diseño en bloques completos. Para resolver está cuestión, SPSS utiliza las Sumas de cuadrados de tipo I. En la obtención de las Sumas de Cuadrados de tipo I cada término se corrige sólo respecto al término que le precede en el modelo por lo que también recibe el nombre de Método de Descomposición Jerárquica de la Suma de Cuadrados.
-
Para evaluar el efecto de los tratamientos, la suma de cuadrados de tratamientos debe ajustarse por bloques, por lo tanto primerose introducen los bloques y después los tratamientos. En la ventana Univariante se selecciona TipoI en Suma de cuadrados. Los resultados de dicho ANOVA dependerán del orden en que se introduzcan los factores en el campo Factores fijo: Pulsando Continuar y Aceptar se obtiene la Tabla ANOVA
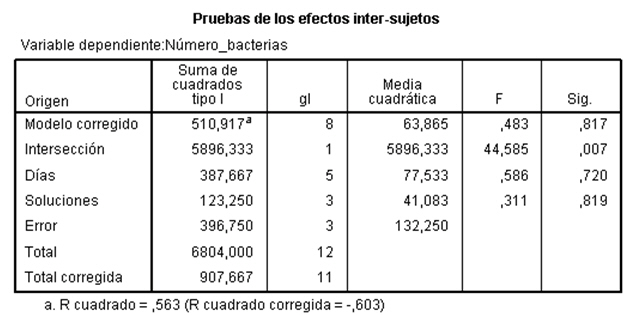 El valor del estadístico de contraste de igualdad de Soluciones, F = 0.311 deja a su derecha un p-valor 0.819, mayor que el nivel de significación del 5%, por lo que no se rechaza la Hipótesis nula de igualdad de tratamientos. Por lo tanto el tipo de solución para lavar los envases de la leche no influye en el retraso del crecimiento de bacterias.
El valor del estadístico de contraste de igualdad de Soluciones, F = 0.311 deja a su derecha un p-valor 0.819, mayor que el nivel de significación del 5%, por lo que no se rechaza la Hipótesis nula de igualdad de tratamientos. Por lo tanto el tipo de solución para lavar los envases de la leche no influye en el retraso del crecimiento de bacterias.
-
Para evaluar el efecto de los bloques, la suma de cuadrados de bloques debe ajustarse por los tratamientos, por lo tanto primero se introducen los tratamientos y después los bloques
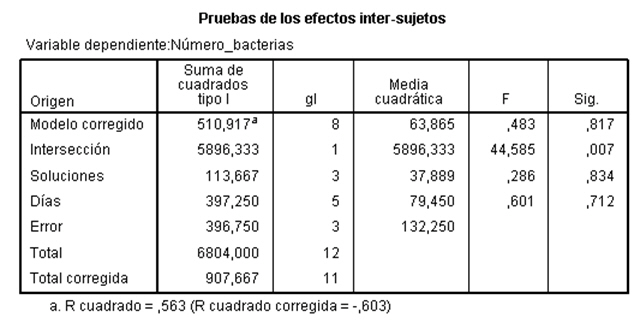 El valor del estadístico de contraste de igualdad de Días, F = 0.601 deja a su derecha un p-valor 0.712, mayor que el nivel de significación del 5%, por lo que no se rechaza la Hipótesis nula de igualdad de bloques. Por lo tanto los días en los que se realiza la prueba para lavar los envases de la leche no influyen en el retraso del crecimiento de bacterias. Con este ejemplo se ilustra el hecho de decidir si se prescinde o no de los bloques. Hay situaciones en las que, aunque los bloques no resulten significativamente diferentes no es conveniente prescindir de ellos. Pero ¿cómo saber cuándo se puede prescindir de los bloques? La respuesta la tenemos en el valor de la F de los bloques, experimentalmente se ha comprobado que si dicho valor es mayor que 3, no conviene prescindir de los bloque para efectuar los contrastes. En esta situación si se puede prescindir del efecto de los bloques y estudiar el modelo unifactorial correspondiente, cuyo único factor es: Soluciones.
El valor del estadístico de contraste de igualdad de Días, F = 0.601 deja a su derecha un p-valor 0.712, mayor que el nivel de significación del 5%, por lo que no se rechaza la Hipótesis nula de igualdad de bloques. Por lo tanto los días en los que se realiza la prueba para lavar los envases de la leche no influyen en el retraso del crecimiento de bacterias. Con este ejemplo se ilustra el hecho de decidir si se prescinde o no de los bloques. Hay situaciones en las que, aunque los bloques no resulten significativamente diferentes no es conveniente prescindir de ellos. Pero ¿cómo saber cuándo se puede prescindir de los bloques? La respuesta la tenemos en el valor de la F de los bloques, experimentalmente se ha comprobado que si dicho valor es mayor que 3, no conviene prescindir de los bloque para efectuar los contrastes. En esta situación si se puede prescindir del efecto de los bloques y estudiar el modelo unifactorial correspondiente, cuyo único factor es: Soluciones.
Diseño en Cuadrados Latinos
Hemos estudiado en el apartado anterior que los diseños en bloques completos aleatorizados utilizan un factor de control o variable de bloque con objeto de eliminar su influencia en la variable respuesta y así reducir el error experimental. Los diseños en cuadrados latinos utilizan dos variables de bloque para reducir el error experimental.
Un inconveniente que presentan a veces los diseños es el de requerir excesivas unidades experimentales para su realización. Un diseño en bloques completos con un factor principal y dos factores de bloque, con K1, K2 y K3 niveles en cada uno de los factores, requiere K1×K2×K3 unidades experimentales. En un experimento puede haber diferentes causas, por ejemplo de índole económico, que no permitan emplear demasiadas unidades experimentales, ante esta situación se puede recurrir a un tipo especial de diseños en bloques incompletos aleatorizados. La idea básica de estos diseños es la de fracción es decir, seleccionar una parte del diseño completo de forma que, bajo ciertas hipótesis generales, permita estimar los efectos que interesan.
Uno de los diseños en bloques incompletos aleatorizados más importante con dos factores de control es el modelo en cuadrado latino, dicho modelo requiere el mismo número de niveles para los tres factores.
En general, para K niveles en cada uno de los factores, el diseño completo en bloques aleatorizados utiliza K² bloques, aplicándose en cada bloque los K niveles del factor principal, resultando un total de K³ unidades experimentales.
Los diseños en cuadrado latino reducen el número de unidades experimentales a K² utilizando los K² bloques del experimento, pero aplicando sólo un tratamiento en cada bloque con una disposición especial. De esta forma, si K fuese 4, el diseño en bloques completos necesitaría 4³=64 observaciones, mientras que el diseño en cuadrado latino sólo necesitaría 4²=16 observaciones.
Los diseños en cuadrados latinos son apropiados cuando es necesario controlar dos fuentes de variabilidad. En dichos diseños el número de niveles del factor principal tiene que coincidir con el número de niveles de las dos variables de bloque o factores secundarios y además hay que suponer que no existe interacción entre ninguna pareja de factores.
Recibe el nombre de cuadrado latino de orden K a una disposición en filas y columnas de K letras latinas, de tal forma que cada letra aparece una sola vez en cada fila y en cada columna.
En resumen, podemos decir que un diseño en cuadrado latino tiene las siguientes características:
-
Se controlan tres fuentes de variabilidad, un factor principal y dos factores de bloque.
-
Cada uno de los factores tiene el mismo número de niveles, K .
-
Cada nivel del factor principal aparece una vez en cada fila y una vez en cada columna.
-
No hay interacción entre los factores.
En el Fichero-Adjunto se muestran algunos cuadrados latinos estándares para los órdenes 3, 4, 5, 6, 7, 8 y 9.
Este diseño lo estudiaremos a continuación mediante el supuesto práctico 5
Supuesto práctico 5
Se estudia el rendimiento de un proceso químico en seis tiempos de reposo, A, B, C, D, E y F. Para ello, se consideran seis lotes de materia prima que reaccionan con seis concentraciones de ácido distintas, de manera que cada lote de materia prima en cada concentración de ácido se somete a un tiempo de reposo. Tanto la asignación de los tiempos de reposo a los lotes de materia prima, como la concentración de ácido, se hizo de forma aleatoria. Los datos del rendimiento del proceso químico se muestran en la siguiente tabla.
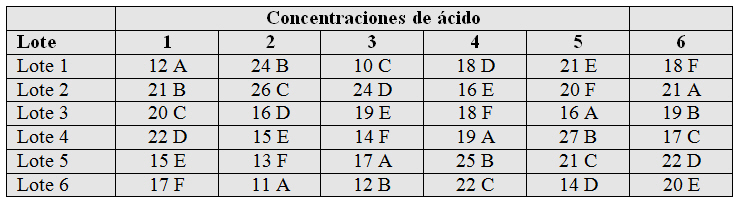
El objetivo principal es estudiar la influencia de seis tiempos de reposo en el rendimiento de un proceso químico, por lo que se trata de un factor con seis niveles. Sin embargo, como los lotes de materia prima y las concentraciones son dos fuentes de variabilidad potencial, consideramos dos factores de bloque con seis niveles cada uno.
- Variable respuesta: Rendimiento
- Factor: Tiempo de reposo que tiene seis niveles. Es un factor de efectos fijos ya que viene decidido que niveles concretos se van a utilizar.
- Bloques: Lotes y Concentraciones, ambos con seis niveles y ambos son factores de efectos fijos.
- Tamaño del experimento: Número total de observaciones (36).
Para realizar este experimento mediante SPSS, se comienza definiendo las variables e introduciendo los datos:
-
Nombre: Rendimiento ; Tipo: Numérico ; Anchura: 2 ; Decimales: 0
-
Nombre: Tiempo_reposo ; Tipo: Numérico ; Anchura: 1 ; Decimales: 0 ; Valores: { 1, A; 2, B; 3, C; 4, D; 5, E; 6, F }
-
Nombre: Lotes ; Tipo: Numérico ; Anchura: 1 ; Decimales: 0 ; Valores: { 1, Lote1; 2, Lote2; 3, Lote 3; 4, Lote 4; 5, Lote 5; 6, Lote 6}
-
Nombre: Concentraciones ; Tipo: Numérico ; Anchura: 1 ; Decimales: 0.
Para resolver los contrastes, se selecciona, en el menú principal, Analizar/Modelo lineal general/ Univariante… En la salida correspondiente, se introduce en el campo Variable dependiente: Rendimiento y en el campo Factores fijos: Tiempo_reposo, Lotes y Concentraciones. Para indicar que se trata de un modelo sin interacción entre los tratamientos y los bloques, se debe pinchar en Modelo e indicar en la salida correspondiente que es un modelo aditivo.
 Observando los valores de los p-valores, 0.281, 0.368 y 0.553; mayores respectivamente que el nivel de significación del 5%, deducimos que ningún efecto es significativo.
Observando los valores de los p-valores, 0.281, 0.368 y 0.553; mayores respectivamente que el nivel de significación del 5%, deducimos que ningún efecto es significativo.
Diseño en Cuadrados Greco-Latinos
El modelo en cuadrado greco-latino se puede considerar como una extensión del modelo en cuadrado latino en el que se incluye una tercera variable control o variable de bloque. En este modelo como en el diseño en cuadrado latino, todos los factores deben tener el mismo número de niveles, K, y el número de observaciones necesarias sigue siendo K². Este diseño es, por tanto, una fracción del diseño completo en bloques aleatorizados con un factor principal y tres factores secundarios que requeriría K4 observaciones.
Los cuadrados greco-latinos se obtienen por superposición de dos cuadrados latinos del mismo orden y ortogonales entre sí, uno de los cuadrados con letras latinas el otro con letras griegas. Dos cuadrados reciben el nombre de ortogonales si, al superponerlos, cada letra latina y griega aparecen juntas una sola vez en el cuadrado resultante.
En el Fichero-Adjunto se muestra una tabla de cuadrados latinos que dan lugar, por superposición de dos de ellos, a cuadrados greco-latinos. Notamos que no es posible formar cuadrados greco-latinos de orden 6.
La Tabla siguiente ilustra un cuadrado greco-latino para K=4
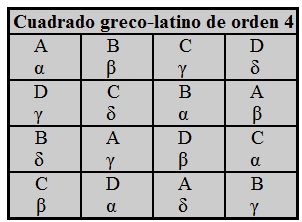 Este diseño lo estudiaremos a continuación mediante el supuesto práctico
Este diseño lo estudiaremos a continuación mediante el supuesto práctico
Supuesto práctico 6
Para comprobar el rendimiento de un proceso químico en cinco tiempos de reposo, se consideran cinco lotes de materia prima que reaccionan con cinco concentraciones de ácido distintas a cinco temperaturas distintas, de manera que cada lote de materia prima con cada concentración de ácido y cada temperatura se somete a un tiempo de reposo. Tanto la asignación de los tiempos de reposo a los lotes de materia prima, como las concentraciones de ácido, y las temperaturas, se hizo de forma aleatoria. En este estudio el científico considera que tanto los lotes de materia prima, las concentraciones y las temperaturas pueden influir en el rendimiento del proceso, por lo que los considera como variables de bloque cada una con cinco niveles y decide plantear un diseño por cuadrados greco-latinos como el que muestra en la siguiente tabla.
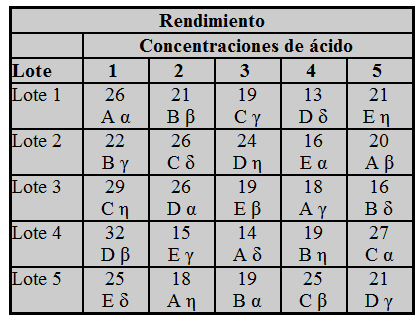 La variable respuesta que vamos a estudiar es el rendimiento del proceso químico. El factor principal es tiempo de reposo que se presenta con cinco niveles.
La variable respuesta que vamos a estudiar es el rendimiento del proceso químico. El factor principal es tiempo de reposo que se presenta con cinco niveles.
- Variable respuesta: Rendimiento
- Factor: Tiempos de reposo que tiene cinco niveles. Es un factor de efectos fijos ya que viene decidido que niveles concretos se van a utilizar.
- Bloques: Lotes, Concentraciones y Temperaturas, cada uno con cinco niveles y de efectos fijos.
- Tamaño del experimento: Número total de observaciones (25).
Para realizar este experimento mediante SPSS, se comienza definiendo las variables e introduciendo los datos:
-
Nombre: Rendimiento ; Tipo: Numérico ; Anchura: 2 ; Decimales: 0
-
Nombre: Tiempo_reposo ; Tipo: Numérico ; Anchura: 1 ; Decimales: 0 ; Valores: { 1, alpha; 2, beta; 3, gamma; 4, delta; 5, eta }
-
Nombre: Temperatura; Tipo: Numérico ; Anchura: 1 ; Decimales: 0 ; Valores: { 1, A; 2, B; 3, C; 4, D; 5, E}
-
Nombre: Lotes ; Tipo: Numérico ; Anchura: 1 ; Decimales: 0 ; Valores: { 1, Lote1; 2, Lote2; 3, Lote 3; 4, Lote 4; 5, Lote 5}
-
Nombre: Concentraciones ; Tipo: Numérico ; Anchura: 1 ; Decimales: 0.
Para resolver los contrastes, se selecciona, en el menú principal, Analizar/Modelo lineal general/ Univariante…
En la salida correspondiente, se introduce en el campo Variable dependiente: Rendimiento y en el campo Factores fijos: Tiempo_reposo, Lotes Concentraciones y Temperaturas.
Para indicar que se trata de un modelo sin interacción entre los tratamientos y los bloques, se debe pinchar en Modelo e indicar en la salida correspondiente que es un modelo aditivo.
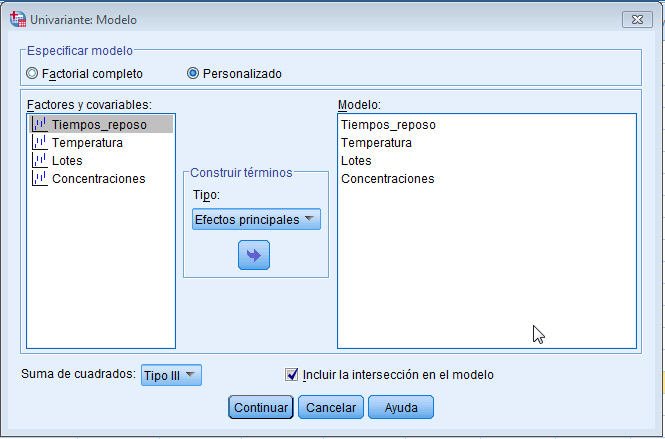
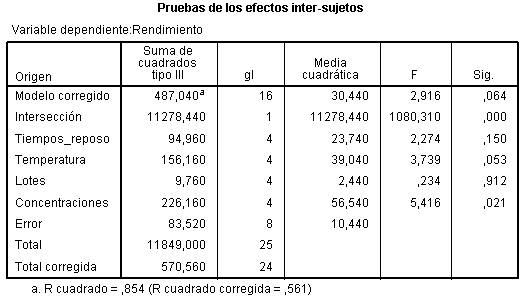 Observando los valores de los p-valores, 0.150, 0.053, 0.912 y 0.021, deducimos que el único efecto significativo, al nivel de significación del 5%, es el efecto de la distintas concentraciones sobre el rendimiento del proceso químico.
Observando los valores de los p-valores, 0.150, 0.053, 0.912 y 0.021, deducimos que el único efecto significativo, al nivel de significación del 5%, es el efecto de la distintas concentraciones sobre el rendimiento del proceso químico.
Diseño en Cuadrados de Youden
Hemos estudiado que en el diseño en cuadrado latino se tiene que verificar que los tres factores tengan el mismo número de niveles, es decir que hay el mismo número de filas, de columnas y de letras latinas. Sin embargo, puede suceder que el número de niveles disponibles de uno de los factores de control sea menor que el número de tratamientos, en este caso estaríamos ante un diseño en cuadrado latino incompleto. Estos diseños fueron estudiados por W.J. Youden y se conocen con el nombre de cuadrados de Youden.
Este diseño lo estudiaremos a continuación mediante el supuesto práctico 7.
Supuesto práctico 7
Consideremos de nuevo el experimento sobre el rendimiento de un proceso químico en el que se está interesado en estudiar seis tiempos de reposo, A, B, C, D, E y F y se desea eliminar estadísticamente el efecto de los lotes materia prima y de las concentraciones de ácido distintas. Pero supongamos que sólo se dispone de cinco tipos de concentraciones. Para analizar este experimento se decidió utilizar un cuadrado de Youden con seis filas (los lotes de materia prima), cinco columnas (las distintas concentraciones) y seis letras latinas (los tiempos de reposo). Los datos correspondientes se muestran en la siguiente tabla.
 Observamos que este diseño se convierte en un cuadrado latino si se le añade la columna F, A, B, C, D y E. En general, un cuadrado de Youden podemos considerarlo como un cuadrado latino al que le falta al menos una columna. Sin embargo, un cuadrado latino no se convierte en un cuadrado de Youden eliminando arbitrariamente más de una columna.
Observamos que este diseño se convierte en un cuadrado latino si se le añade la columna F, A, B, C, D y E. En general, un cuadrado de Youden podemos considerarlo como un cuadrado latino al que le falta al menos una columna. Sin embargo, un cuadrado latino no se convierte en un cuadrado de Youden eliminando arbitrariamente más de una columna.
Un cuadrado de Youden se puede considerar como un diseño en bloques incompletos balanceado y simétrico en el que las filas corresponden a los bloques. En efecto, si asignamos
-
el factor principal a las letras latinas,
-
un factor secundario, el que tiene el mismo número de niveles que el factor principal, a las filas,
-
un factor secundario, el que tiene menor número de niveles que el factor principal, a las columnas,
entonces, un cuadrado de Youden es un diseño en bloques incompletos balanceado y simétrico en el que
- Cada tratamiento ocurre una vez en cada columna.
- La posición del tratamiento dentro de un bloque indica el nivel del factor secundario correspondiente a las columnas.
- El número de réplicas de un tratamiento dado es igual al número de tratamientos por bloque.
Recordamos que los parámetros que caracterizan este modelo son:
-
I, J y K son el número de tratamientos, el número de bloques y el número de tratamientos por bloque, respectivamente.
-
R, número de veces que cada tratamiento se presenta en el diseño, es decir el número de réplicas de un tratamiento dado.
-
λ , número de bloques en los que un par de tratamientos ocurren juntos.
-
N, número de observaciones.
Los valores de los parámetros del modelo en este ejemplo son:
N = I R = J K. En efecto, ya que N= 30; I = 6 = J ; R = K = 5.
![]()
El objetivo principal es estudiar la influencia de seis tiempos de reposo en el rendimiento de un proceso químico, por lo que se trata de un factor con seis niveles. Sin embargo, como los lotes de materia prima y las concentraciones son dos fuentes de variabilidad potencial, consideramos dos factores de bloque con seis y cinco niveles, respectivamente.
- Variable respuesta: Rendimiento
- Factor: Tiempo de reposo que tiene seis niveles. Es un factor de efectos fijos ya que viene decidido que niveles concretos se van a utilizar.
- Bloques: Lotes y Concentraciones, con seis y cinco niveles, respectivamente y ambos son factores de efectos fijos.
- Tamaño del experimento: Número total de observaciones (30).
Para realizar este experimento mediante SPSS, se comienza definiendo las variables e introduciendo los datos:
-
Nombre: Rendimiento ; Tipo: Numérico ; Anchura: 2 ; Decimales: 0
-
Nombre: Tiempo_reposo ; Tipo: Numérico ; Anchura: 1 ; Decimales: 0 ; Valores: { 1, A; 2, B; 3, C; 4, D; 5, E; 6, F }
-
Nombre: Lotes ; Tipo: Numérico ; Anchura: 1 ; Decimales: 0 ; Valores: { 1, Lote1; 2, Lote2; 3, Lote 3; 4, Lote 4; 5, Lote 5; 6, Lote 6}
-
Nombre: Concentraciones ; Tipo: Numérico ; Anchura: 1 ; Decimales: 0.
Para resolver los contrastes, se selecciona, en el menú principal, Analizar/Modelo lineal general/ Univariante… En la salida correspondiente, se introduce en el campo Variable dependiente: Rendimiento y en el campo Factores fijos: Tiempo_reposo, Lotes y Concentraciones. Para indicar que se trata de un modelo sin interacción entre los tratamientos y los bloques, se debe pinchar en Modelo e indicar en la salida correspondiente que es un modelo aditivo. Así mismo hay que indicar que el diseño en cuadrado de Youden es un diseño en bloques incompletos balanceado, por lo que hay que seleccionar la suma de cuadrados de tipo I.
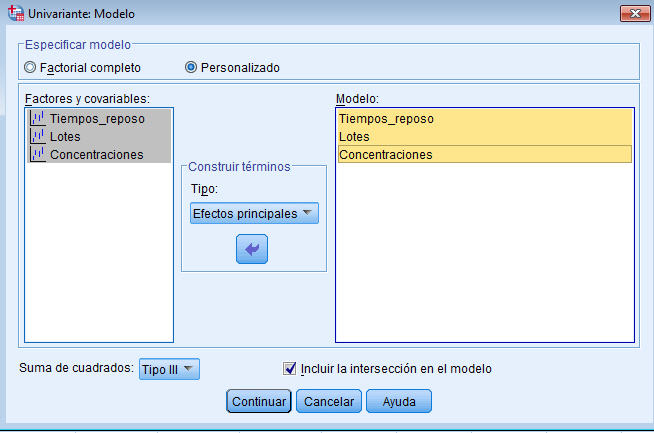
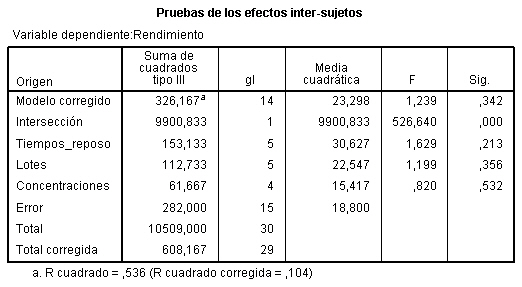
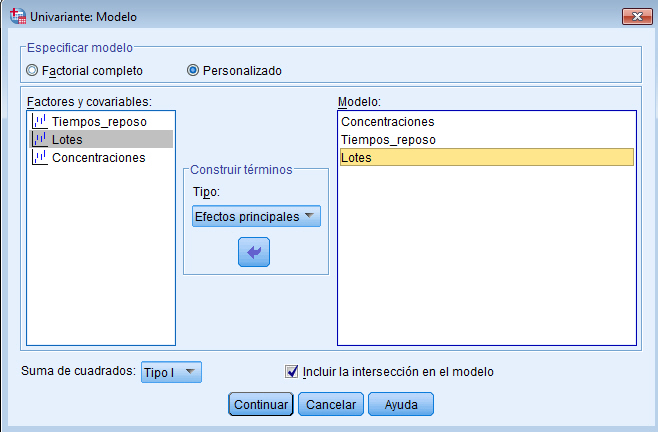
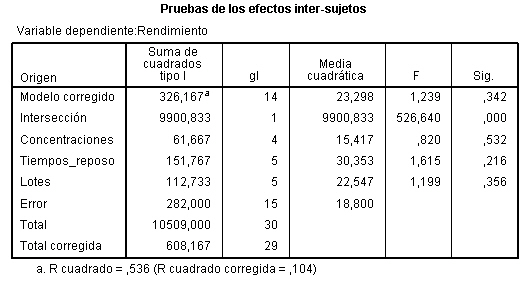
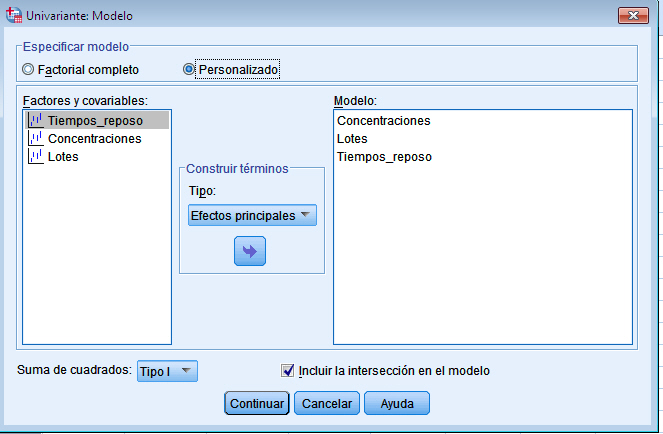
 Observando los p-valores, 0.532, 0.356 y 0.213; mayores respectivamente que el nivel de significación del 5%, deducimos que ningún efecto es significativo.
Observando los p-valores, 0.532, 0.356 y 0.213; mayores respectivamente que el nivel de significación del 5%, deducimos que ningún efecto es significativo.
Diseños Factoriales
En muchos experimentos es frecuente considerar dos o más factores y estudiar el efecto conjunto que dichos factores producen sobre la variable respuesta. Para resolver esta situación se utiliza el Diseño Factorial.
Se entiende por diseño factorial aquel diseño en el que se investigan todas las posibles combinaciones de los niveles de los factores en cada réplica del experimento. En estos diseños, los factores que intervienen tienen la misma importancia a priori y se supone por tanto, la posible presencia de interacción. En este epígrafe vamos a considerar únicamente modelos de efectos fijos.
Diseños factoriales con dos factores
En primer lugar vamos a estudiar los diseños más simples, es decir aquellos en los que intervienen sólo dos factores. Supongamos que hay a niveles para el factor A y b niveles del factor B, cada réplica del experimento contiene todas las posibles combinaciones de tratamientos, es decir contiene los ab tratamientos posibles.
El modelo sin replicación
El modelo estadístico para este diseño es:
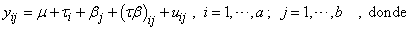 yij: Representa la observación correspondiente al nivel (i) del factor A y al nivel (j) del factor B.
yij: Representa la observación correspondiente al nivel (i) del factor A y al nivel (j) del factor B.
-
µ: Efecto constante, común a todos los niveles de los factores, denominado media global.
-
τi: Efecto producido por el nivel i-ésimo del factor A, (∑iτi = 0).
-
βj: Efecto producido por el nivel j-ésimo del factor B, (∑j βj = 0).
-
(τβ)ij: Efecto producido por la interacción entre A×B,(∑i (τβ)ij = ∑j (τβ)ij = 0).
-
uij son vv aa. independientes con distribución N(0,σ).
Supondremos que se toma una observación por cada combinación de factores, por tanto, hay un total de N=ab observaciones.
Parámetros a estimar:
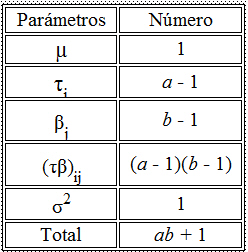 |
A pesar de las restricciones impuestas al modelo, ∑iτi = ∑j βj = ∑i (τβ)ij = ∑j (τβ)ij = 0, el número de parámetros (ab+1) supera al número de observaciones (ab). Por lo tanto, algún parámetro no será estimable. |
Los residuos de este modelo son nulos, eij = 0, por lo tanto no es posible estimar la varianza del modelo y no se pueden contrastar la significatividad de los efectos de los factores. Dichos contrates sólo pueden realizarse si:
- Suponemos que la interacción entre A×B es cero.
- Replicamos el experimento (Tomamos varias observaciones por cada combinación de factores).
Supuesto práctico 8
En unos laboratorios se está investigando sobre el tiempo de supervivencia de unos animales a los que se les suministra al azar tres tipos de venenos y cuatro antídotos distintos. Se pretende estudiar si los tiempos de supervivencia de los anímales varían en función de las combinaciones veneno-antídoto. Los datos que se recogen en la tabla adjunta son los tiempos de supervivencia en horas.
El objetivo principal es estudiar la influencia de tres tipos de venenos y 4 tipos de antídotos en el tiempo de supervivencia de unos determinados animales, por lo que se trata de un modelo con dos factores: el veneno (con tres niveles) y el antídoto (con cuatro niveles). La variable que va a medir las diferencias entre los tratamientos es el tiempo que sobreviven los animales. Se combinan todos los niveles de los dos factores por lo que tenemos en total doce tratamientos.
- Variable respuesta: Tiempo de supervivencia
- Factor: Tipo de veneno que tiene tres niveles. Es un factor de efectos fijos ya que viene decidido qué niveles concretos se van a utilizar.
- Factor: Tipo de antídoto que tiene cuatro niveles. Es un factor de efectos fijos ya que viene decidido qué niveles concretos se van a utilizar.
- Tamaño del experimento: Número total de observaciones (12).
Para realizar este experimento mediante SPSS, se comienza definiendo las variables e introduciendo los datos:
-
Nombre: Tiempo_supervivencia; Tipo: Numérico ; Anchura: 2 ; Decimales: 0
-
Nombre: Tipo_veneno; Tipo: Numérico ; Anchura: 1 ; Decimales: 0 ; Valores: { 1, Veneno1; 2, Veneno2; 3, Veneno3}
-
Nombre: Tipo_antídoto; Tipo: Numérico ; Anchura: 1 ; Decimales: 0 ; Valores: { 1, Antídoto1; 2, Antídoto2; 3, Antídoto3; 4, Antídoto4}
Para resolver los contrastes, se selecciona, en el menú principal, Analizar/Modelo lineal general/ Univariante… En la salida correspondiente, se introduce en el campo Variable dependiente: Tiempo_supervivencia y en el campo Factores fijos: Tipo_veneno y Tipo_antídoto. Es un modelo de dos factores con 3 y 4 niveles cada uno y un total de 12 observaciones por lo que no puede haber interacción entre los factores ya que si la hubiera el número de parámetros del modelo superaría al número de observaciones y como consecuencia los residuos del modelo serían nulos y no se podrían contrastar la significatividad de los efectos de los factores. Indicamos que se trata de un modelo sin interacción entre los factores, para ello se debe pinchar en Modelo e indicar en la salida correspondiente que es un modelo aditivo. Se pulsa Continuar y Aceptar
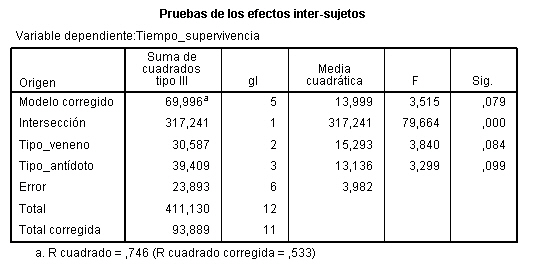 Esta Tabla ANOVA recoge la descomposición de la varianza considerando como fuente de variación los doce tratamientos o grupos que se forman al combinar los niveles de los dos factores. Mediante esta tabla se puede estudiar sí varían los tiempos que sobreviven los animales en función de las combinaciones veneno-antídoto. Es decir, se pueden estudiar si existen diferencias significativas entre los tiempos medios de supervivencia con los distintos tipos de venenos y antídotos, pero no se puede estudiar si la efectividad de los antídotos es la misma para todos los venenos. Observando los p-valores, 0.084 y 0.099; mayores respectivamente que el nivel de significación del 5%, deducimos que ningún efecto es significativo. Por lo tanto, no existen diferencias en los tiempos medios de supervivencia de los animales, en función de la pareja veneno-antídoto que se les suministra.
Esta Tabla ANOVA recoge la descomposición de la varianza considerando como fuente de variación los doce tratamientos o grupos que se forman al combinar los niveles de los dos factores. Mediante esta tabla se puede estudiar sí varían los tiempos que sobreviven los animales en función de las combinaciones veneno-antídoto. Es decir, se pueden estudiar si existen diferencias significativas entre los tiempos medios de supervivencia con los distintos tipos de venenos y antídotos, pero no se puede estudiar si la efectividad de los antídotos es la misma para todos los venenos. Observando los p-valores, 0.084 y 0.099; mayores respectivamente que el nivel de significación del 5%, deducimos que ningún efecto es significativo. Por lo tanto, no existen diferencias en los tiempos medios de supervivencia de los animales, en función de la pareja veneno-antídoto que se les suministra.
El modelo con replicación
El modelo estadístico para este diseño es:
![]()
donde r es el número de replicaciones y N = abr es el número de observaciones.
El número de parámetros de este modelo es, como en el modelo de dos factores sin replicación, ab+1 pero en este caso el número de observaciones es abr.
La descripción del diseño así como la terminología subyacente la vamos a introducir mediante el siguiente supuesto práctico.
Supuesto práctico 9
Consideremos el supuesto práctico anterior en el que realizamos dos réplicas por cada tratamiento. Los datos que se recogen en la tabla adjunta son los tiempos de supervivencia en horas de unos animales a los que se les suministra al azar tres venenos y cuatro antídotos. El objetivo es estudiar qué antídoto es el adecuado para cada veneno.
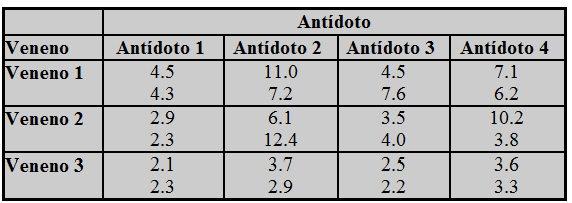
El modelo matemático que planteamos es el siguiente:
![]()
- yijk: Representa el tiempo de supervivencia del animal k al que se le suministró el veneno i y el antídoto j.
-
µ: Efecto constante, común a todos los niveles de los factores, denominado media global.
-
τi: Efecto medio producido por el veneno i, (∑iτi = 0).
-
βj: Efecto medio producido por antídoto j, (∑j βj = 0).
-
(τβ)ij: Efecto medio producido por la interacción entre el veneno i y el antídoto j, (∑i (τβ)ij = ∑j (τβ)ij = 0).
-
uijk: Vv aa. independientes con distribución N(0,σ).
- Variable respuesta: Tiempo de supervivencia;
- Factor: Tipo de veneno (tres niveles).
- Factor: Tipo de antídoto (cuatro niveles).
- Ambos factores de efectos fijos.
- Tamaño del experimento: Número total de observaciones (24).
Para realizar este experimento mediante SPSS, se comienza introduciendo las variables definidas anteriormente en el supuesto práctico 8.
Para resolver los contrastes, se selecciona, en el menú principal, Analizar/Modelo lineal general/ Univariante… En la salida correspondiente, se introduce en el campo Variable dependiente: Tiempo_supervivencia y en el campo Factores fijos: Tipo_veneno y Tipo_antídoto. Es un modelo de dos factores donde se quiere estudiar la posible interacción entre ambos factores, por lo que se realiza el modelo completo donde aparezca dicha interacción. Así que no es necesario especificar nada en la opción Modelo y se pulsa directamente Aceptar:
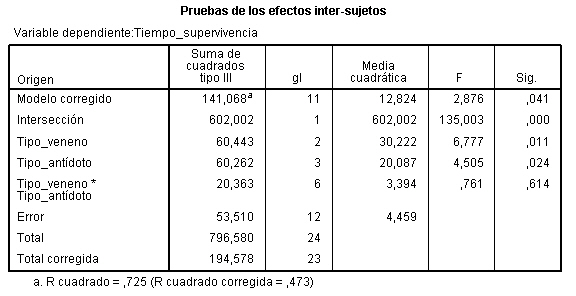 La Tabla ANOVA muestra las filas de Tipo_veneno, Tipo_antídoto y Tipo_veneno*Tipo_antídoto que corresponde a la variabilidad debida a los efectos de cada uno de los factores y de la interacción entre ambos.
La Tabla ANOVA muestra las filas de Tipo_veneno, Tipo_antídoto y Tipo_veneno*Tipo_antídoto que corresponde a la variabilidad debida a los efectos de cada uno de los factores y de la interacción entre ambos.
Las preguntas que nos planteamos son: ¿Son los venenos igual de peligrosos? ¿Y los antídotos son igual de efectivos? La efectividad de los antídotos, ¿es la misma para todos los venenos? Para responder a estas preguntas, comenzamos comprobando si el efecto de los antídotos es el mismo para todos los venenos. Para ello observamos el valor del estadístico (Fexp= 0.761) que contrasta la hipótesis correspondiente a la interacción entre ambos factores (H0: (τβ)ij = 0). Dicho valor deja a la derecha un Sig. = 0.614, mayor que el nivel de significación 0.05. Por lo tanto la interacción entre ambos factores no es significativa y debemos eliminarla del modelo. Construimos de nuevo la Tabla ANOVA en la que sólo figurarán los efectos principales. Para ello en la ventana Univariante, pinchamos en Modelo e indicamos en la salida correspondiente que es un modelo aditivo. Se pulsa Continuar y Aceptar y se muestra la siguiente Tabla
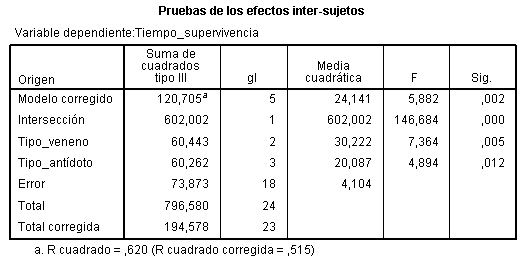 Esta tabla muestra dos únicas fuentes de variación, lo efectos principales de los dos factores (Tipo_veneno y Tipo_antídoto), y se ha suprimido la interacción entre ambos. Se observa que el valor de la Suma de Cuadrados del error de este modelo (73.873) se ha formado con los valores de las Sumas de cuadrados del error y de la interacción del modelo anterior (20.363 + 53.510 = 73.873). Observando los valores de los p-valores, 0.005 y 0.012 asociados a los contrastes principales, se deduce que los dos efectos son significativos a un nivel de significación del 5%. Deducimos que ni la gravedad de los venenos es la misma, ni la efectividad de los antídotos, pero dicha efectividad no depende del tipo de veneno con el que se administre ya que la interacción no es significativa.
Esta tabla muestra dos únicas fuentes de variación, lo efectos principales de los dos factores (Tipo_veneno y Tipo_antídoto), y se ha suprimido la interacción entre ambos. Se observa que el valor de la Suma de Cuadrados del error de este modelo (73.873) se ha formado con los valores de las Sumas de cuadrados del error y de la interacción del modelo anterior (20.363 + 53.510 = 73.873). Observando los valores de los p-valores, 0.005 y 0.012 asociados a los contrastes principales, se deduce que los dos efectos son significativos a un nivel de significación del 5%. Deducimos que ni la gravedad de los venenos es la misma, ni la efectividad de los antídotos, pero dicha efectividad no depende del tipo de veneno con el que se administre ya que la interacción no es significativa.
Como hemos dicho en el enunciado, el objetivo del estudio es determinar qué antídoto es el adecuado para cada veneno. Con el fin de determinar qué antídoto es el mejor utilizamos el método de Tukey, para ello en la ventana Univariante seleccionamos Post_hoc…y, se pasa la variable Tipo_antídoto al campo Pruebas posthoc para: y seleccionamos la prueba de Tukey. Se pulsa Continuar y Aceptar.
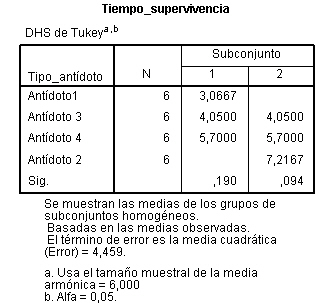
La tabla nos muestra dos subconjuntos homogéneos, el primero está formado por los antídotos 1, 3 y 4; esto nos indica que no se aprecian diferencias significativas entre ellos. El segundo subconjunto homogéneo está formado por los antídotos 3, 4 y 2 indicándonos, como en el caso anterior que no hay diferencias significativas entre estos tres tipos de antídotos. Sin embargo si hay diferencias significativas entre ambos subconjuntos, siendo el Antídoto2 significativamente más efectivo que el Antídoto1 (su tiempo medio de supervivencia es 7.2167, superior a los obtenidos con los otros antídotos), y significativamente superior al del Antídoto1.
Diseños factoriales con tres factores
Supongamos que hay a niveles para el factor A, b niveles del factor B y c niveles para el factor C y que cada réplica del experimento contiene todas las posibles combinaciones de tratamientos, es decir contiene los abc tratamientos posibles.
El modelo sin replicación
El modelo estadístico para este diseño es:
![]() donde
donde
-
yijk: Representa la observación correspondiente al nivel (i) del factor A, al nivel (j) del factor B y al nivel (k) del factor C.
-
µ: Efecto constante, común a todos los niveles de los factores, denominado media global.
-
τi: Efecto producido por el nivel i-ésimo del factor A, (∑iτi = 0).
-
βj: Efecto producido por el nivel j-ésimo del factor B, (∑j βj = 0).
-
γk: Efecto producido por el nivel k -ésimo del factor C, (∑k γk = 0).
-
(τβ)ij: Efecto producido por la interacción entre A×B, (∑i (τβ)ij = ∑j (τβ)ij = 0).
-
(τγ)ik: Efecto producido por la interacción entre A×C, (∑i (τγ)ik = ∑k (τγ)ik = 0).
-
(βγ)jk: Efecto producido por la interacción entre B×C, (∑j (βγ)jk = ∑j (βγ)jk = 0).
-
(τβγ)ijk: Efecto producido por la interacción entre A×B×C,(∑i (τβγ) ijk = ∑j (τβγ) ijk = ∑k(τβγ)ijk = 0).
-
uijk: Vv aa. independientes con distribución N(0,σ).
Supondremos que se toma una observación por cada combinación de factores, por tanto, hay un total de N=abc observaciones.
Parámetros a estimar:
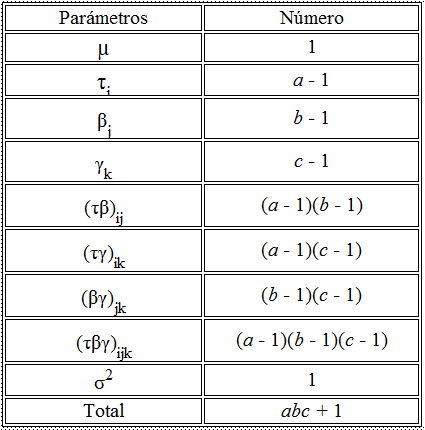 |
A pesar de las restricciones impuestas al modelo, ∑iτi = ∑j βj = ∑k γk = ∑i (τβ)ij = ∑j (τβ)ij = , …., = ∑k(τβγ)ijk = 0, el número de parámetros (abc+1) supera al número de observaciones (abc). Por lo tanto, algún parámetro no será estimable. |
En este modelo la variabilidad total se descompone en:
SCT=SCA+SCB+SCC+SC(AB)+SC(AC)+SC(BC)+SC(ABC)+SCR
Que representan:
- SCT : Suma de Cuadrados Total,
- SCA, SCB, SCC: Suma de Cuadrados entre los niveles de A, de B y de C, respectivamente
- SC(AB), SC(AC), SC(BC), SC(ABC), SCR: Suma de Cuadrados de las interacciones A×B, A×C, B×C, A×B×C y del error, respectivamente.
A partir de la ecuación básica del Análisis de la Varianza se pueden construir los cuadrados medios definidos como:
-
Cuadrado medio total: CMT=(SCT)/(n-1)
-
Cuadrado medio de A: CMA=(SCA)/(a-1)
-
Cuadrado medio de B: CMB=(SCB)/(b-1)
-
Cuadrado medio de C: CMC=(SCC)/(c-1)
-
Cuadrado medio de las interacciones:
-
Cuadrado medio residual: CMR=(SCR)/((a-1)(b-1(c-1))
Supuesto práctico 10
En una fábrica de refrescos está haciendo unos estudios en la planta embotelladora. El objetivo es obtener más uniformidad en el llenado de las botellas. La máquina de llenado teóricamente llena cada botella a la altura correcta, pero en la práctica hay variación, y la embotelladora desea entender mejor las fuentes de esta variabilidad para eventualmente reducirla. En el proceso se pueden controlar tres factores durante el proceso de llenado: El % de carbonato (factor A), la presión del llenado (factor B) y el número de botellas llenadas por minuto que llamaremos velocidad de la línea (factor C). Se consideran tres niveles para el factor A (10%, 12%, 14%), dos niveles para el factor B (25psi, 30psi) y dos niveles para el factor C (200bpm, 250bpm). Los datos recogidos de la desviación de la altura objetivo se muestran en la tabla adjunta
Analizar los resultados y obtener las conclusiones apropiadas.
El modelo matemáticos que planteamos es el siguiente:
![]() donde
donde
-
yijk: Representa la desviación de la altura objetivo en la botella al porcentaje i de carbono, a la concentración j y a la velocidad k.
-
µ: Efecto constante, común a todos los niveles de los factores, denominado media global.
-
τi: Efecto medio producido por el tanto por ciento i de carbono.
-
βj: Efecto medio producido por la presión j.
-
γk: Efecto producido por la velocidad k.
-
(τβ)ij : Efecto medio producido por la interacción entre el porcentaje i de carbono y la presión j.
-
(τγ)ik: Efecto producido por la interacción entre el porcentaje i de carbono y la velocidad k.
-
(βγ)jk: Efecto producido por la interacción entre la presión j y la velocidad k.
-
(τβγ)ijk: Efecto producido por la interacción entre el porcentaje i de carbono, la presión j y la velocidad k.
-
Estos efectos son parámetros a estimar, con las condiciones ∑iτi = ∑j βj = ∑k γk = ∑i (τβ)ij = ∑j (τβ)ij = , …., = ∑k (βγ)jk = 0,
-
uijk son vv aa. independientes con distribución N(0,σ).
La variable respuesta de este experimento es la Desviación que se produce en la altura de llenado en las botellas de refresco, siendo dichas botellas las unidades experimentales. En estas desviaciones de la altura de llenado marcada como objetivo intervienen tres factores: Porcentaje de carbono que presenta tres niveles 10%, 12% y 14%; Presión, con dos niveles 25 psi y 30 psi y Velocidad, con dos niveles 200 y 250. Los niveles de los factores han sido fijados por el experimentador, por lo que todos los factores son de efectos fijos. Se trata de un diseño trifactorial de efectos fijos, donde el número de tratamientos es 3×2×2 = 12.
Para realizar este experimento mediante SPSS, se comienza definiendo las variables e introduciendo los datos:
-
Nombre: Desviación; Tipo: Numérico ; Anchura: 2 ; Decimales: 0
-
Nombre: Carbono; Tipo: Numérico ; Anchura: 1 ; Decimales: 0; Valores: { 1, 10 por ciento; 2, 12 por ciento; 3, 14 por ciento}
- Nombre: Presión; Tipo: Numérico ; Anchura: 1 ; Decimales: 0; Valores: { 1, 25 psi; 2, 30 psi}
-
Nombre: Velocidad; Tipo: Numérico ; Anchura: 1 ; Decimales: 0 ; Valores: { 1, Velocidad (200); 2, Velocidad (250)}
Para resolver los contrastes, se selecciona, en el menú principal, Analizar/Modelo lineal general/ Univariante… En la salida correspondiente, se introduce en el campo Variable dependiente: Desviación y en el campo Factores fijos: Carbono, Presión y Velocidad. Es un modelo de tres factores con 3, 2 y 2 niveles cada uno y un total de 12 observaciones por lo que no puede haber interacción entre los tres factores ya que si la hubiera el número de parámetros del modelo superaría al número de observaciones y como consecuencia los residuos del modelo serían nulos y no se podrían contrastar la significatividad de los efectos de los factores. Indicamos que se trata de un modelo sin interacción entre los tres factores, para ello se debe pinchar en Modelo e indicar en la salida correspondiente que consta de efectos principales y de interacciones de orden dos. Se pulsa Continuar y Aceptar.
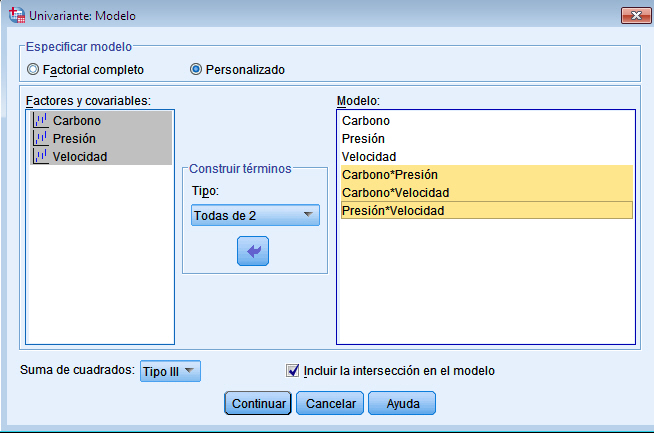
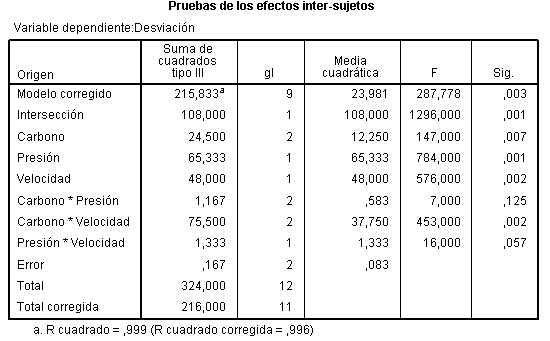
La Tabla ANOVA muestra las filas de Carbono, Presión, Velocidad, Carbono*Presión, Carbono*Velocidad y Presión*Velocidad que corresponden a la variabilidad debida a los efectos de cada uno de los factores y a las interacciones de orden dos entre ambos. En dicha Tabla se indica que para un nivel de significación del 5% los efectos que no son significativos del modelo planteado son las interacciones entre los factores Carbono*Presión y Presión*Velocidad ya que los p-valores correspondientes a estos efectos son 0.125 y 0.057 mayores que el nivel de significación.
Como consecuencia de este resultado, replanteamos el modelo suprimiendo en primer lugar el efecto Carbono*Presión, cuya significación es mayor, y resulta el siguiente modelo matemático:
![]() donde los efectos deben cumplir las condiciones expuestas anteriormente. Para resolverlo mediante SPSS, en la ventana Univariante: Modelo suprimimos la interacción Carbono*Presión. Se pulsa Continuar y Aceptar. La tabla ANOVA que corresponde a este modelo es la siguiente
donde los efectos deben cumplir las condiciones expuestas anteriormente. Para resolverlo mediante SPSS, en la ventana Univariante: Modelo suprimimos la interacción Carbono*Presión. Se pulsa Continuar y Aceptar. La tabla ANOVA que corresponde a este modelo es la siguiente
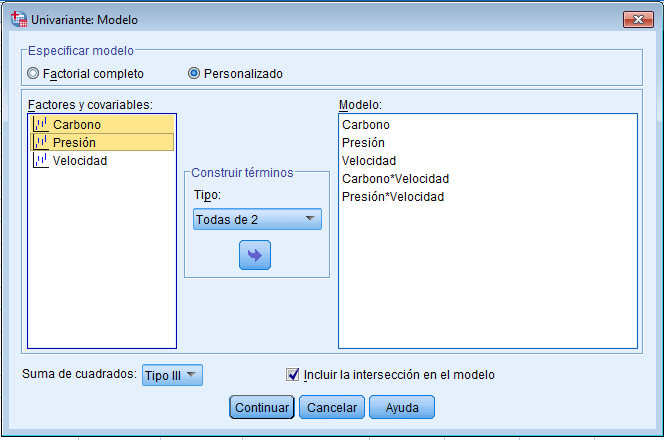

El efecto Presión*Velocidad sigue siendo no significativo por lo que lo suprimimos del modelo y replanteamos el siguiente modelo matemático
![]() donde los efectos deben cumplir las condiciones expuestas anteriormente. Para resolverlo mediante SPSS, en la ventana Univariante: Modelo suprimimos la interacción Presión*Velocidad. Se pulsa Continuar y Aceptar. La tabla ANOVA que corresponde a este modelo es la siguiente:
donde los efectos deben cumplir las condiciones expuestas anteriormente. Para resolverlo mediante SPSS, en la ventana Univariante: Modelo suprimimos la interacción Presión*Velocidad. Se pulsa Continuar y Aceptar. La tabla ANOVA que corresponde a este modelo es la siguiente:
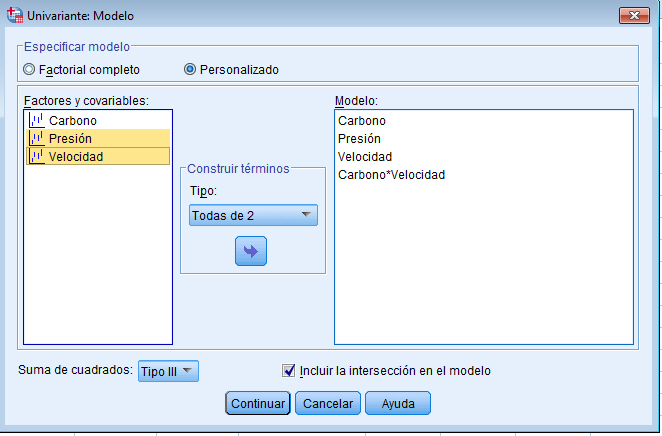
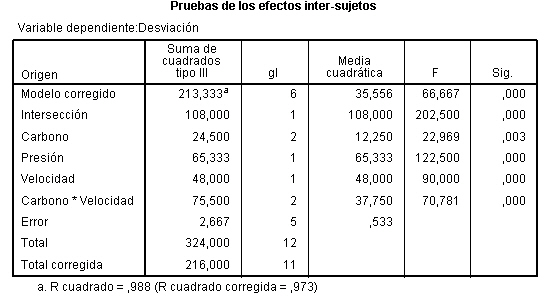
Todos los efectos de este último modelo planteado son significativos y por lo tanto es en este modelo donde vamos a realizar el estudio. Existen diferencias significativas entre los distintos porcentajes del Carbono, los dos tipos de presión, las dos velocidades de llenado y la interacción entre el porcentaje de Carbono y la Velocidad de llenado.
En primer lugar estudiamos qué porcentajes de carbono son significativamente diferentes mediante el método de Tukey. Para ello en la ventana Univariante seleccionamos Post_hoc…y, se pasa la variable Carbono al campo Pruebas posthoc para: y seleccionamos la prueba de Tukey. Se pulsa Continuar y Aceptar.
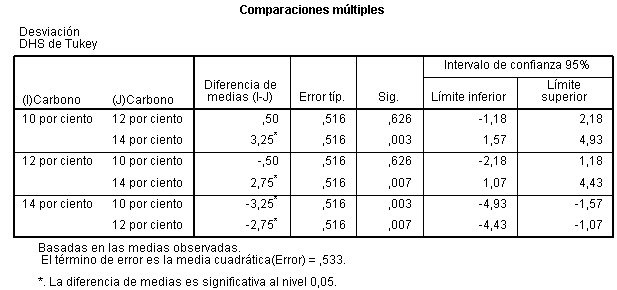

Comprobamos que el porcentaje de Carbono que produce mayores desviaciones en el llenado de las botellas es el 10% y el que produce la menor desviación es el 14%. También se observa que hay dos grupos muy diferenciados, siendo el porcentaje de Carbono del 14% el que presenta diferencias significativas con los otros dos porcentajes. No habiendo diferencias significativas entre los porcentajes 12% y 10%.
Los factores Presión y Velocidad tienen cada uno dos niveles por lo tanto no se puede aplicar ningún método de comparaciones múltiples para comprobar qué tipo de Presión y qué Velocidad de llenado produce mayor/menor desviación en el llenado de las botellas. Podemos resolverlo calculando los llenados medios de cada uno de los niveles de los factores, para ello seleccionamos Analizar/Estadísticos descriptivos/Explorar… y en la ventana resultante, se introduce en el campo Lista de dependiente: Desviación, en el campo Lista de f actores: Presión y Velocidad y en Visualizar se selecciona Estadísticos
Se pulsa Aceptar y se obtienen las siguientes salidas:
La Presión a 25 psi produce mayor desviación de llenado que a 30 psi ya que su desviación media es de 5.33 fente a 0.67 y respecto a la Velocidad observamos que a una Velocidad de 200 se produce mayor desviación en el llenado de las botellas de refresco (valor medio de desviación es de 5 frente a un valor medio de 1 para la Velocidad de 250).
A continuación analizamos el efecto de la interacción de los factores Carbono*Velocidad mediante el gráfico de medias. Para ello, en la ventana Univariante se selecciona Gráficos… En la salida correspondiente se especifica cuál de los dos factores se representa en el eje de abscisas y cuál se utiliza para dibujar las rectas. Seleccionamos en el campo Eje horizontal: la variable Carbono y en Líneas separadas: la variable Velocidad. Pinchamos Añadir y pulsando Continuar y Aceptar se obtiene el siguiente gráfico de medias.
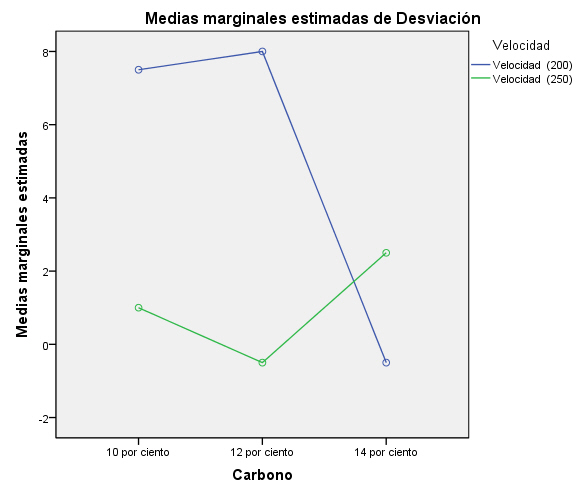
Al cruzarse las medias de las distintas velocidades se confirma la presencia de interacción entre los factores Carbono*Velocidad se observa que:
- Al variar el porcentaje de Carbono de 12 % al 14% y manteniendo una Velocidad de 200, la Desviación de llenado varía dependiendo del porcentaje de Carbono, produciéndose la mayor Desviación Media de llenado al porcentaje de Carbono del 12% y la menor al 14%.
- Manteniendo la Velocidad a 200, la Desviación de llenado aumenta levemente del porcentaje del 10% al 12% y disminuye bruscamente al 14%.
- Manteniendo la Velocidad a 250 la Desviación de llenado disminuye del porcentaje del 10% al 12% y aumenta al 14%.
- Lo que se desea averiguar en cuando se producen las menores Desviaciones de llenado y observando la gráfica comprobamos que dichas Desviaciones se producen al porcentaje del 12% y 250 de Velocidad y al 14% y Velocidad de 200.
También se puede realizar gráfico de medias Velocidad*Carbono, para ello seleccionamos en el campo Eje horizontal: la variable Velocidad y en Líneas separadas: la variable Carbono. Pinchamos Añadir y pulsando Continuar y Aceptar se obtiene el siguiente gráfico de medias
- Al variar la Velocidad de 200 a 250 y manteniendo el porcentaje de Carbono al 10%, la desviación de llenado varía dependiendo de la Velocidad, produciéndose la mayor Desviación media de llenado a la Velocidad de 200 y la menor a la Velocidad de 250.
- La Desviación de llenado desciende bruscamente de la Velocidad 200 a 250 tanto con el porcentaje de Carbono de 10% y de 12%. En cambio el comportamiento es diferente al 14 % de Carbono. A este último porcentaje la Desviación de llenado de las botellas es menor a una Velocidad de 200 y va aumentando a una Velocidad de 250.
- Concluyendo, la menor Desviación de llenado se produce a una Velocidad de 250 y una Concentración del 12%.
El modelo con replicación
El modelo estadístico para este diseño es: ![]() donde r es el número de replicaciones y N = abcr es el número de observaciones. El número de parámetros de este modelo es, como en el modelo de tres factores sin replicación, abc+1 pero en este caso el número de observaciones es abcr. El objetivo del análisis de este modelo es realizar los contrastes sobre los efectos principales, las interacciones de orden dos y la interacción de orden tres.
donde r es el número de replicaciones y N = abcr es el número de observaciones. El número de parámetros de este modelo es, como en el modelo de tres factores sin replicación, abc+1 pero en este caso el número de observaciones es abcr. El objetivo del análisis de este modelo es realizar los contrastes sobre los efectos principales, las interacciones de orden dos y la interacción de orden tres.
Supuesto práctico 11
Consideremos el supuesto práctico anterior en el que realizamos dos réplicas por cada tratamiento. En la Tabla adjunta se muestran los datos recogidos de la desviación de la altura objetivo de las botellas de refresco. En el proceso de llenado, la embotelladora puede controlar tres factores durante el proceso: El porcentaje de carbonato (factor A) con tres niveles (10%, 12%, 14%), la presión del llenado (factor B) con dos niveles (25psi, 30psi) y el número de botellas llenadas por minuto que llamaremos velocidad de la línea (factor C) con dos niveles (200bpm, 250bpm).
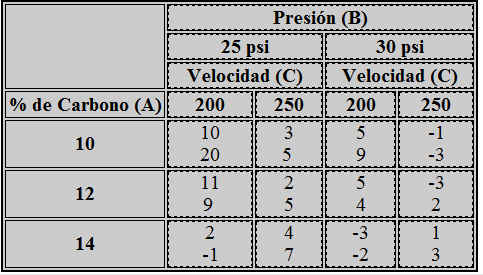
El modelo matemáticos del experimento que planteamos es el siguiente:
![]() La variable respuesta y los efectos de los factores se definieron en el Supuesto práctico 10. Las restricciones para este modelo son: ∑iτi = ∑j βj = ∑k γk = ∑i (τβ)ij = ∑j (τβ)ij = , …., = ∑k (τβγ)ijk = 0,
La variable respuesta y los efectos de los factores se definieron en el Supuesto práctico 10. Las restricciones para este modelo son: ∑iτi = ∑j βj = ∑k γk = ∑i (τβ)ij = ∑j (τβ)ij = , …., = ∑k (τβγ)ijk = 0,
La variable respuesta de este experimento es la Desviación que se produce de la altura objetivo en el llenado en las botellas de refresco. Los factores son: Porcentaje de Carbono que presenta tres niveles 10%, 12% y 14%; Presión, con dos niveles 25 psi y 30 psi y Velocidad, con dos niveles 200 y 250. Los niveles de los factores han sido fijados por el experimentador, por lo que todos los factores son de efectos fijos. Se trata de un diseño trifactorial de efectos fijos, donde el número de tratamientos es 3×2×2 = 12 y el número de observaciones 24.
Para realizar este experimento mediante SPSS, se comienza introduciendo las variables definidas anteriormente en el Supuesto práctico 10.
Para resolver los contrastes, se selecciona, en el menú principal, Analizar/Modelo lineal general/ Univariante… En la salida correspondiente, se introduce en el campo Variable dependiente: Desviación y en el campo Factores fijos: Carbono, Presión y Velocidad. Es un modelo de tres factores donde se quiere estudiar las posibles interacciones entre los factores, por lo que se realiza el modelo completo donde aparezcan todas las interacciones. Así que no es necesario especificar nada en la opción Modelo y se pulsa directamente Aceptar
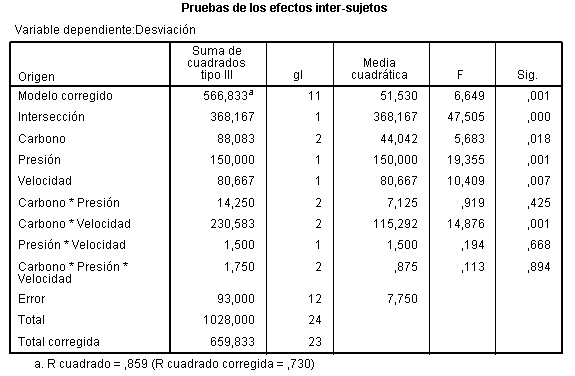
La Tabla ANOVA muestra las filas de Carbono, Presión, Velocidad, Carbono*Presión, Carbono*Velocidad, Presión*Velocidad y Carbono*Presión*Velocidad que corresponden a la variabilidad debida a los efectos de cada uno de los factores, a las interacciones de orden dos y orden tres entre los factores. En dicha Tabla se indica que para un nivel de significación del 5% los efectos que no son significativos del modelo planteado son las interacciones entre los factores, Carbono*Presión y Presión*Velocidad y Carbono*Presión*Velocidad ya que los p-valores correspondientes a estos efectos son 0.425, 0.668 y 0.894 mayores que el nivel de significación.
Como consecuencia de este resultado, replanteamos el modelo suprimiendo en primer lugar el efecto Carbono*Presión*Velocidad, cuya significación es mayor, y resulta el siguiente modelo matemático: ![]() donde los efectos deben cumplir las condiciones expuestas anteriormente. Para resolverlo mediante SPSS, en la ventana Univariante: Modelo suprimimos la interacción Carbono*Presión*Velocidad,. Se pulsa Continuar y Aceptar. La tabla ANOVA que corresponde a este modelo es la siguiente
donde los efectos deben cumplir las condiciones expuestas anteriormente. Para resolverlo mediante SPSS, en la ventana Univariante: Modelo suprimimos la interacción Carbono*Presión*Velocidad,. Se pulsa Continuar y Aceptar. La tabla ANOVA que corresponde a este modelo es la siguiente
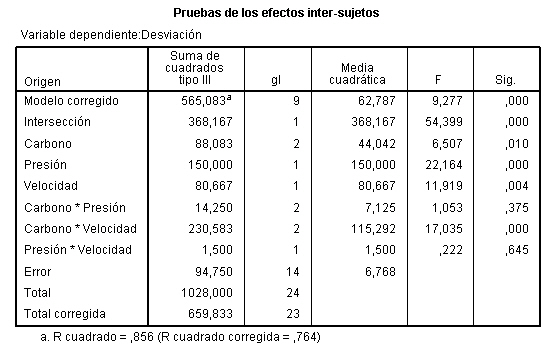
Los efectos Carbono*Presión y Presión*Velocidad siguen siendo no significativos. Suprimimos el efecto Presión*Velocidad que tiene una significatividad más alta y replanteamos el siguiente modelo matemático
![]() donde los efectos deben cumplir las condiciones expuestas anteriormente. Para resolverlo mediante SPSS, en la ventana Univariante: Modelo suprimimos la interacción Presión*Velocidad. Se pulsa Continuar y Aceptar. La tabla ANOVA que corresponde a este modelo es la siguiente:
donde los efectos deben cumplir las condiciones expuestas anteriormente. Para resolverlo mediante SPSS, en la ventana Univariante: Modelo suprimimos la interacción Presión*Velocidad. Se pulsa Continuar y Aceptar. La tabla ANOVA que corresponde a este modelo es la siguiente:
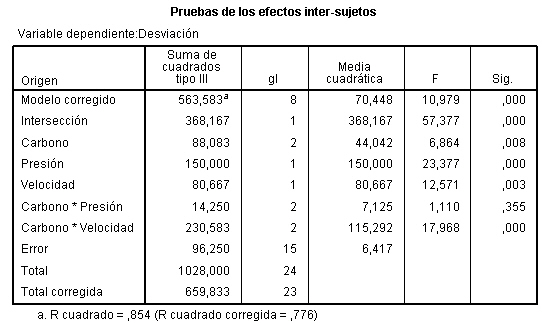
El efecto Carbono*Presión sigue siendo no significativo por lo tanto lo suprimimos y replanteamos el siguiente modelo matemático
![]() donde los efectos deben cumplir las condiciones expuestas anteriormente. Para resolverlo mediante SPSS, en la ventana Univariante: Modelo suprimimos la interacción Carbono*Presión. Se pulsa Continuar y Aceptar. La tabla ANOVA que corresponde a este modelo es la siguiente:
donde los efectos deben cumplir las condiciones expuestas anteriormente. Para resolverlo mediante SPSS, en la ventana Univariante: Modelo suprimimos la interacción Carbono*Presión. Se pulsa Continuar y Aceptar. La tabla ANOVA que corresponde a este modelo es la siguiente:
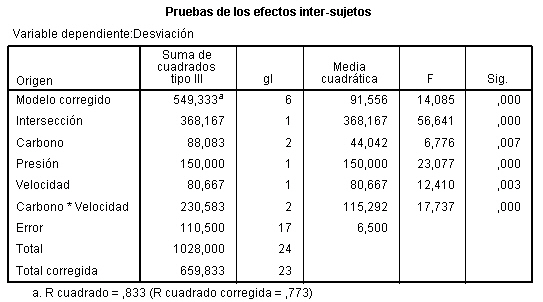
Todos los efectos de este último modelo planteado son significativos y por lo tanto es en este modelo donde vamos a realizar el estudio. Existen diferencias significativas entre los distintos porcentajes del Carbono, los dos tipos de presión, las dos velocidades de llenado y la interacción entre el porcentaje de Carbono y la Velocidad de llenado.
En primer lugar estudiamos qué porcentaje de carbono son significativamente diferentes mediante el método de Duncan. Para ello en la ventana Univariante seleccionamos Post_hoc…y, se pasa la variable Carbono al campo Pruebas posthoc para: y seleccionamos la prueba de Duncan. Se pulsa Continuar y Aceptar.

Comprobamos que el porcentaje de Carbono que produce mayores desviaciones en el llenado de las botellas es el 10% y el que produce la menor desviación es el 14%. También se observa que hay dos grupos muy diferenciados, siendo el porcentaje de Carbono del 14% el que presenta diferencias significativas con los otros dos porcentajes. No habiendo diferencias significativas entre los porcentajes 12% y 10%.
Los factores Presión y Velocidad tienen cada uno dos niveles por lo tanto no se puede aplicar ningún método de comparaciones múltiples para comprobar qué tipo de Presión y qué Velocidad de llenado produce mayor/menor desviación en el llenado de las botellas. Podemos resolverlo calculando los llenados medios de cada uno de los niveles de los factores, para ello seleccionamos Analizar/Estadísticos descriptivos/Explorar… y en la ventana resultante, se introduce en el campo Lista de dependiente: Desviación, en el campo Lista de f actores: Presión y Velocidad y en Visualizar se selecciona Estadísticos. Se pulsa Aceptar y se muestran las siguientes salidas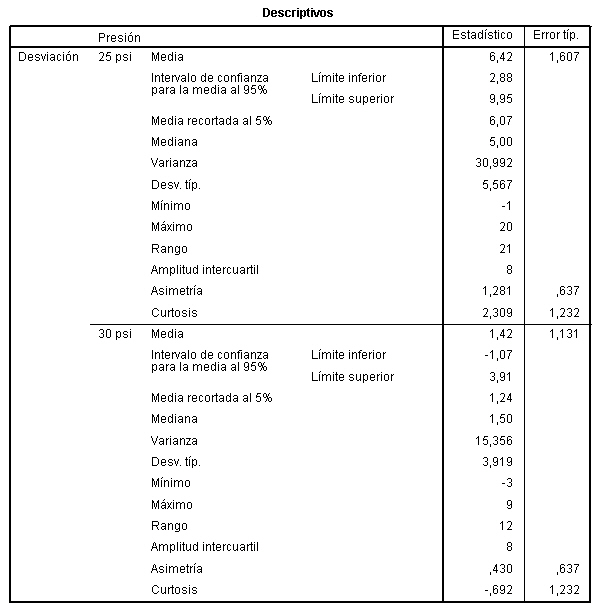
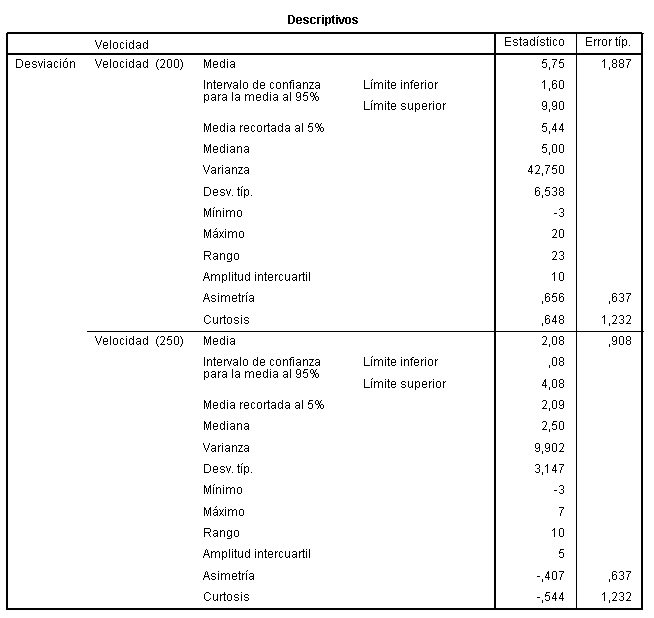 La Presión a 25 psi produce mayor desviación de llenado que a 30 psi ya que su desviación media es de 6.42 frente a 1.42 (desviación media de llenado a la presión 30 psi) y respecto a la Velocidad observamos que a una Velocidad de 200 se produce mayor desviación en el llenado de las botellas de refresco (valor medio de desviación es de 5.75 frente a un valor medio de 2.08 para la Velocidad de 250).
La Presión a 25 psi produce mayor desviación de llenado que a 30 psi ya que su desviación media es de 6.42 frente a 1.42 (desviación media de llenado a la presión 30 psi) y respecto a la Velocidad observamos que a una Velocidad de 200 se produce mayor desviación en el llenado de las botellas de refresco (valor medio de desviación es de 5.75 frente a un valor medio de 2.08 para la Velocidad de 250).
A continuación analizamos el efecto de la interacción de los factores Carbono*Velocidad mediante el gráfico de medias. Para ello, en la ventana Univariante se selecciona Gráficos… En la salida correspondiente se especifica cuál de los dos factores se representa en el eje de abscisas y cuál se utiliza para dibujar las rectas. Seleccionamos en el campo Eje horizontal: la variable Carbono y en Líneas separadas: la variable Velocidad. Pinchamos Añadir. De nuevo seleccionamos en el campo Eje horizontal: la variable Velocidad y en Líneas separadas: la variable Carbono. Pinchamos Añadir y pulsando Continuar y Aceptar se obtienen los siguientes gráficos de medias.
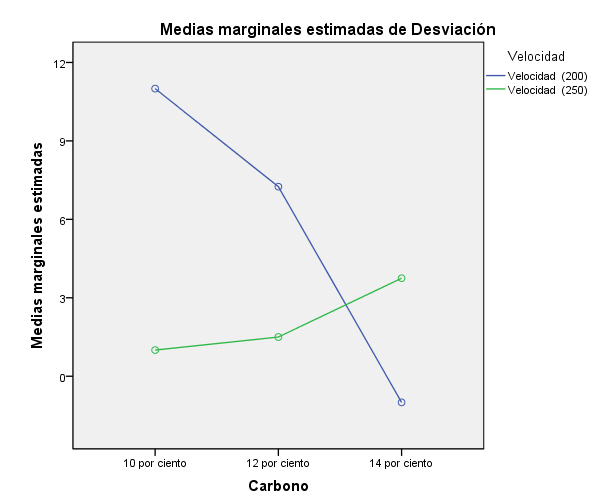
 En el primer gráfico:
En el primer gráfico:
Al cruzarse las medias de las distintas velocidades se confirma la presencia de interacción entre los factores Carbono*Velocidad se observa que:
-
Al variar el porcentaje de Carbono de 12 % al 14% y manteniendo una Velocidad de 200, la Desviación de llenado varía dependiendo del porcentaje de Carbono, produciéndose la mayor Desviación Media de llenado al porcentaje de Carbono del 12% y la menor al 14%.
-
Manteniendo la Velocidad a 200, la Desviación de llenado disminuye bruscamente conforme los porcentajes aumentan.
-
Manteniendo la Velocidad a 250 la Desviación de llenado aumenta conforme los porcentajes aumentan.
-
Lo que se desea averiguar en cuando se producen las menores Desviaciones de llenado y observando la gráfica comprobamos que dichas Desviaciones se producen al 14% de Carbono y 200 de Velocidad.
En el segundo gráfico:
Al cruzarse las medias de los distintos porcentajes se confirma la presencia de interacción entre los factores Velocidad*Carbono se observa que:
-
Al variar la Velocidad de 200 a 250 y manteniendo el porcentaje de Carbono al 10%, la desviación de llenado varía dependiendo de la Velocidad, produciéndose la mayor Desviación media de llenado a la Velocidad de 200 y la menor a la Velocidad de 250.
-
La Desviación de llenado desciende bruscamente de la Velocidad 200 a 250 tanto con el porcentaje de Carbono de 10% y de 12%. En cambio el comportamiento es diferente al 14 % de Carbono. A este último porcentaje la Desviación de llenado de las botellas es menor a una Velocidad de 200 y va aumentando a una Velocidad de 250.
-
Concluyendo, la menor Desviación de llenado se produce a una Velocidad de 200 y un porcentaje de Carbono del 14%.
Ejercicios
Ejercicios Guiados
| A continuación se va a proceder a iniciar una aplicación Java, comprueba que tengas instalada la Máquina Virtual Java para poder ejecutar aplicaciones en Java.Si no tienes instalada la Máquina Virtual Java (Java Runtime Environment – JRE) pincha en uno de los enlaces para descargarla: |
 java |
| Instalación directa de la JRE 7 para WindowsPágina oficial de Sun Microsystems, descarga de la JRE para cualquier plataforma |
| Si ya tienes instalada la Máquina Virtual Java pincha en el siguiente enlace para proceder a la ejecución de los ejercicios guiados | Ejercicio 1 |
IMPORTANTE: Si al descargar el archivo *.JAR del ejercicio tu gestor de descargas intenta guardarlo como *.ZIP debes cambiar la extensión a .JAR para poder ejecutarlo.
Enunciado del Ejercicio 1
Se realiza un estudio del contenido de azufre en cinco yacimientos de carbón. Se toman muestras aleatoriamente de cada uno de los yacimientos y se analizan. Los datos del porcentaje de azufre por muestra se indican en la tabla adjunta.
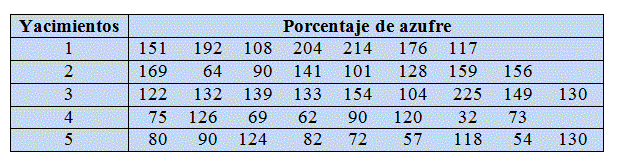
Para un nivel de significación del 5%.
-
¿Se puede confirmar que el porcentaje de azufre es el mismo en los cinco yacimientos?
-
Si se rechaza la hipótesis nula que las medias de porcentaje de azufre en los cinco yacimientos es la misma, determinar que medias difieren entre sí utilizando el método de comparaciones múltiples de Tukey.
- Estudiar las hipótesis de modelo: Homocedasticidad (Homogeneidad de las varianzas por grupo), Independencia y Normalidad.
Enunciado del Ejercicio 2
Se realiza un estudio sobre el efecto del fotoperiodo y del genotipo en el periodo latente de infección del moho de cebada aislado AB3. Se obtienen cincuenta hojas de cuatro genotipos distintos. Cada grupo es infectado y posteriormente expuesto a diferente fotoperiodo. Los distintos fotoperiodos se trataron como bloques y se obtuvieron los siguientes datos de los totales para los bloques y tratamientos. La respuesta anotada es el número de días hasta la aparición de síntomas visibles.

-
¿Se puede afirmar que los diferentes genotipos no influyen en el número de días hasta la aparición de la infección? ¿Se puede concluir que los distintos fotoperiodos no afectan al tiempo de aparición de los síntomas de infección del moho?
-
En caso de que influyan significativamente alguno de los dos factores, extraer conclusiones utilizando el método de Duncan.
-
Comprobar gráficamente si existe o no interacción entre los genotipos y los fotoperiodos.
- Estudiar las hipótesis de modelo: Homocedasticidad, Independencia y Normalidad.
Enunciado del Ejercicio 3
Se realiza un estudio para determinar el efecto del nivel del agua y del tipo de planta sobre la longitud global del tallo de las plantas de guisantes. Para ello, se utilizan tres niveles de agua (bajo, medio y alto) y dos tipos de plantas (sin hojas y convencional). Se dispone para el estudio de dieciocho plantas sin hojas y dieciocho plantas convencionales. Se dividen aleatoriamente los dos tipos de plantas en tres subgrupos y después se asignan los niveles de agua aleatoriamente a los dos grupos de plantas. Los datos sobre la longitud del tallo de los guisantes (en centímetros) se muestran en la siguiente tabla:
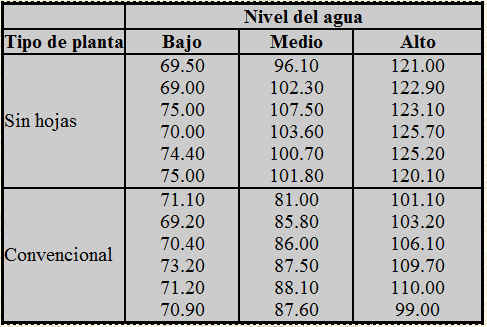 Para un nivel de significación del 5%.
Para un nivel de significación del 5%.
-
¿Se puede afirmar que los distintos niveles de agua influyen en la longitud del tallo de los guisantes? ¿Y el tipo de planta?
-
¿La efectividad del nivel del agua es la misma para los dos tipos de plantas?
-
Interpretar el gráfico de medias para analizar en qué sentido se producen las interacciones.
-
Estudia, utilizando el método de Newman- Keuls, qué nivel de agua es más efectivo.
Ejercicios Propuestos
Ejercicio Propuesto 1
La convección es una forma de transferencia de calor por los fluidos debido a sus variaciones de densidad por la temperatura; las partes calientes ascienden y las frías descienden formando las corrientes de convección que hacen uniforme la temperatura del fluido. Se ha realizado un experimento para determinar las modificaciones de la densidad de fluido al elevar la temperatura en una determinada zona. Los resultados obtenidos han sido los siguientes:
Responder a las siguientes cuestiones:
- ¿Afecta la temperatura a la densidad del fluído?
-
Determinar qué temperaturas producen modificaciones significativas en la densidad media del fluido.
- Estudiar las hipótesis del modelo: Homocedasticidad, independencia y normalidad.
-
¿Se puede afirmar que las temperaturas de 100 y 125 producen menos densidades de fluido en promedio que las temperaturas de 150 y 175?
Ejercicio Propuesto 2
Un laboratorio de reciclaje controla la calidad de los plásticos utilizados en bolsas. Se desea contrastar si existe variabilidad en la calidad de los plásticos que hay en el mercado. Para ello, se eligen al azar cuatro plásticos y se les somete a una prueba para medir el grado de resistencia a la degradación ambiental. De cada plástico elegido se han seleccionado ocho muestras y los resultados de la variable que mide la resistencia son los de la tabla adjunta.

¿Qué conclusiones se deducen de este experimento?
Ejercicio Propuesto 3
Debido a la proliferación de los campos de golf y a la gran cantidad de agua que necesitan, un grupo de científicos estudia la calidad de varios tipos de césped para implantarlo en invierno en los campos de golf. Para ello, miden la distancia recorrida por una pelota de golf, en el campo, después de bajar por una rampa (para proporcionar a la pelota una velocidad inicial constante). El terreno del que disponen tiene mayor pendiente en la dirección norte-sur, por lo que se aconseja dividir el terreno en cinco bloques de manera que las pendientes de las parcelas individuales dentro de cada bloque sean las mismas. Se utilizó el mismo método para la siembra y las mismas cantidades de semilla. Las mediciones son las distancias desde la base de la rampa al punto donde se pararon las pelotas. En el estudio se incluyeron las variedades: Agrostis Tenuis (Césped muy fino y denso, de hojas cortas y larga duración), Agrostis Canina (Hoja muy fina, estolonífera. Forma una cubierta muy tupida), Paspalum Notatum (Hojas gruesas, bastas y con rizomas. Forma una cubierta poco densa), Paspalum Vaginatum (Césped fino, perenne, con rizomas y estolones).
 Se pide:
Se pide:
-
Identificar los elementos del estudio (factores, unidades experimentales, variable respuesta, etc.) y plantear detalladamente el modelo matemático utilizado en el experimento.
- ¿Son los bloques fuente de variación?
- Existen diferencias reales entre las distancias medias recorridas por una pelota de golf en los distintos tipos de césped?
- Estudiar las interacciones de los factores.
- Comprobar que se cumplen las hipótesis del modelo.
-
Utilizando el método de Newman-Keuls, ¿qué tipo de cesped ofrece menor resistencia al recorrido de las pelotas?
Ejercicio Propuesto 4
Consideremos de nuevo el ejercicio propuesto 3 sobre un grupo de científicos que estudia la calidad de varios tipos de césped para implantarlo en invierno en los campos de golf. Para ello, miden la distancia recorrida por una pelota de golf, en el campo, después de bajar por una rampa (para proporcionar a la pelota una velocidad inicial constante). El terreno del que disponen tiene mayor pendiente en la dirección norte-sur, por lo que se aconseja dividir el terreno en cinco bloques de manera que las pendientes de las parcelas individuales dentro de cada bloque sean las mismas. Se utilizó el mismo método para la siembra y las mismas cantidades de semilla. Las mediciones son las distancias desde la base de la rampa al punto donde se pararon las pelotas, y al realizar dichas mediciones no se han podido obtener una para cada combinación de tipo de césped y tipo de terreno, sino que sólo se han podido realizar con tres de las variedades del césped en cada uno de los bloques de terreno. Para controlar el efecto del tipo de terreno deciden utilizar un diseño en bloques incompletos. En el estudio se incluyeron las variedades: Agrostis Tenuis (Césped muy fino y denso, de hojas cortas y larga duración), Agrostis Canina (Hoja muy fina, estolonífera. Forma una cubierta muy tupida), Paspalum Notatum (Hojas gruesas, bastas y con rizomas. Forma una cubierta poco densa), Paspalum Vaginatum (Césped fino, perenne, con rizomas y estolones).
 Se pide:
Se pide:
-
Identificar los elementos del estudio (factores, unidades experimentales, variable respuesta, etc.) y plantear detalladamente el modelo matemático utilizado en el experimento.
- ¿Son los bloques fuente de variación?
- Existen diferencias reales entre las distancias medias recorridas por una pelota de golf en los distintos tipos de césped?
- Comprobar que se cumplen las hipótesis del modelo.
-
Utilizando el método de Newman-Keuls, ¿qué tipo de cesped ofrece menor resistencia al recorrido de las pelotas?
Ejercicio Propuesto 5
Un investigador quiere evaluar la productividad de cuatro variedades de aguacates, A, B, C y D. Para ello decide realizar el ensayo en un terreno que posee un gradiente de pendiente de oriente a occidente y además, diferencias en la disponibilidad de Nitrógeno de norte a sur, para controlar los efectos de la pendiente y la disponibilidad de Nitrógeno, utilizó un diseño de cuadrado latino, los datos corresponden a la producción en kg/parcela.
 Responder a las siguientes cuestiones:
Responder a las siguientes cuestiones:
-
¿Se puede afirmar que la productividad media de las cuatro variedades de aguacate es la misma?
-
¿Qué supuestos han de verificarse?
- ¿Se obtiene la misma producción con las cuatro variedades de aguacate? En caso negativo, analizar mediante el procedimiento de Tukey, con qué variedad de aguacate hay mayor producción.
Ejercicio Propuesto 6
Consideremos de nuevo el ejercicio propuesto 5 del investigador que quiere evaluar la productividad de cuatro variedades de aguacate, A, B, C y D. Para ello, decide realizar el ensayo en un terreno que posee un gradiente de pendiente de oriente a occidente y además, diferencias en la disponibilidad de Nitrógeno de norte a sur. Se seleccionan cuatro disponibilidades de nitrógeno, pero sólo dispone de tres gradientes de pendiente. Para controlar estas posibles fuentes de variabilidad, el investigador decide utilizar un diseño en cuadrado de Youden con cuatro filas, las cuatro disponibilidades de Nitrógeno (NI, N2, N3, N4), tres columnas, los tres gradientes de pendientes (P1, P2, P3) y cuatro letras latinas, las variedades de aguacates (A, B, C, D). Los datos corresponden a la producción en kg/parcela.
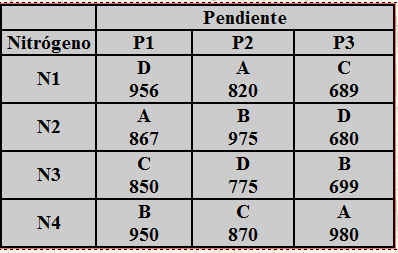 Responder a las siguientes cuestiones:
Responder a las siguientes cuestiones:
-
Estudiar cuál es el tipo de diseño adecuado a este experimento y escribir el modelo matemático asociado.
-
¿Se puede afirmar qué la productividad media de las cuatro variedades de aguacate es la misma?
-
¿Qué supuestos han de verificarse?
- ¿Se obtiene la misma producción con las cuatro variedades de aguacate? En caso negativo, analizar mediante el procedimiento de Duncan, con qué variedad de aguacate hay mayor producción.
Ejercicio Propuesto 7
En un invernadero se está estudiando el crecimiento de determinadas plantas, para ello se quiere controlar los efectos del terreno, abono, insecticida y semilla. El estudio se realiza con cuatro tipos de semillas diferentes que se plantan en cuatro tipos de terreno, se les aplican cuatro tipos de abonos y cuatro tipos de insecticidas. La asignación de los tratamientos a las plantas se realiza de forma aleatoria. Para controlar estas posibles fuentes de variabilidad se decide plantear un diseño por cuadrados greco-latinos como el que se muestra en la siguiente tabla, donde las letras griegas corresponden a los cuatro tipos de semilla y las latinas a los abonos.
 Responder a las siguientes cuestiones:
Responder a las siguientes cuestiones:
-
Estudiar cuál es el tipo de diseño adecuado a este experimento y escribir el modelo matemático asociado.
- ¿Qué supuestos han de verificarse?
- ¿Se puede afirmar que el crecimiento de las plantas es el mismo para los cuatro tipos de abonos?¿Y con los distintos insecticidas?
-
¿Existen diferencias significativas en el crecimiento de las plantas con las distintas semillas? ¿Y el tipo de tierra influye en dicho crecimiento?
-
¿Con qué tipo de semilla se produce el mayor crecimiento de las plantas?
- ¿El crecimiento de las plantas es el mismo utilizando al mismo tiempo los abonos A y B que utilizando los abonos C y D?
Ejercicio Propuesto 8
Se realiza un estudio sobre el efecto que produce la descarga de aguas residuales de una planta sobre la ecología del agua natural de un río. En el estudio se utilizaron dos lugares de muestreo. Un lugar está aguas arriba del punto en el que la planta introduce aguas residuales en la corriente; el otro está aguas abajo. Se tomaron muestras durante un periodo de cuatro semanas y se obtuvieron los datos sobre el número de diatomeas halladas. Los datos se muestran en la tabla adjunta:
 Responder a las siguientes cuestiones:
Responder a las siguientes cuestiones:
-
Identificar el diseño adecuado a este experimento, escribir el modelo matemático y explicar los distintos elementos que intervienen.
-
Estudiar si la semana y el lugar son factores determinantes en el número de diatomeas halladas en el agua del río. ¿Hay posibilidad que una semana sea más recomendable en un lugar del río en concreto y no lo sea en el otro lugar?
-
Estudiar en qué semana se producen menos contaminación en el río, utilizando el método de Duncan.
-
Estudiar en qué lugar del río se producen menos diatomeas.
Ejercicio Propuesto 9
La cotinina es uno de los principales metabolitos de la nicotina. Actualmente se le considera el mejor indicador de la exposición al humo de tabaco. Se ha realizado un estudio con distintas marcas de tabaco distinguiendo principalmente entre negro y rubio para detectar las posibles diferencias en el nivel de nicotina de personas expuestas al humo de tabaco. Para ello, se han analizado personas de distintas edades (niños, jóvenes y adultos) y se ha distinguido entre mujeres y hombres. Se han obtenido los datos de la siguiente tabla sobre el nivel de nicotina en miligramos por mililitro.
 Responder a las siguientes cuestiones:
Responder a las siguientes cuestiones:
-
Identificar el diseño adecuado a este experimento, escribir el modelo matemático y explicar los distintos elementos que intervienen.
-
Contrastar la hipótesis nula de no interacción entre los factores. Adecuar el modelo al resultado de las interacciones y contrastar los efectos principales.
-
¿Hay diferencias significativas en el nivel de nicotina en las distintas edades?¿En qué edad el nivel de nicotina es mayor?
- ¿El tipo de tabaco es un factor determinante en el nivel de nicotina?
-
Comparar el nivel medio de nicotina entre las mujeres y los hombres. ¿Se detectan diferencias significativas?
Ejercicio Propuesto 1 (Resuelto)
La convección es una forma de transferencia de calor por los fluidos debido a sus variaciones de densidad por la temperatura; las partes calientes ascienden y las frías descienden formando las corrientes de convección que hacen uniforme la temperatura del fluido. Se ha realizado un experimento para determinar las modificaciones de la densidad de fluido al elevar la temperatura en una determinada zona. Los resultados obtenidos han sido los siguientes:
Responder a las siguientes cuestiones:
- ¿Afecta la temperatura a la densidad del fluído?
-
Determinar qué temperaturas producen modificaciones significativas en la densidad media del fluido.
- Estudiar las hipótesis del modelo: Homocedasticidad, independencia y normalidad.
-
Se puede afirmar que las temperaturas de 100 y 125 producen menos densidades de fluido en promedio que las temperaturas de 150 y 175.
Solución:
El problema planteado se modeliza a través de un diseño unifactorial totalmente aleatorizado de efectos fijos no-equilibrado.
- Variable respuesta: Densidad del fluido.
- Factor: Temperatura: Es un factor de Efectos fijos.
- Modelo no-equilibrado: Los niveles de los factores tienen distinto número de elementos.
-
¿Afecta la temperatura a la densidad del fluído?
Para responder a este apartado, se plantea el siguiente contraste de igualdad de medias:
![]() Se selecciona Analizar/Modelo lineal general/Univariante. En la salida correspondiente, se introduce en el campo Variable dependiente: La variable respuesta Densidad del fluido y en el campo Factores fijos: el factor Temperatura. Pulsando Aceptar se obtiene la Tabla ANOVA
Se selecciona Analizar/Modelo lineal general/Univariante. En la salida correspondiente, se introduce en el campo Variable dependiente: La variable respuesta Densidad del fluido y en el campo Factores fijos: el factor Temperatura. Pulsando Aceptar se obtiene la Tabla ANOVA
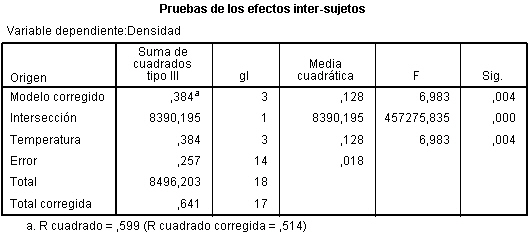
En la tabla ANOVA el valor del estadístico de contrates de igualdad de medias F = 6.983, deja a su derecha un p-valor = 0.004 inferior a 0.05, por lo que se rechaza la hipótesis nula de igualdad de medias. Concluyendo que existen diferencias significativas en la densidad del fluido en función de la modificación de la temperatura.
-
Determinar qué temperaturas producen modificaciones significativas en la densidad media del fluido.
Se plantea la pregunta de si la densidad media del fluido es significativamente diferente para las 4 temperaturas analizadas o sólo para alguna de ellas. Esta cuestión se resuelve mediante los contrastes de comparaciones múltiples. Utilizando la prueba de Tukey,se obtienen los siguientes resultados:
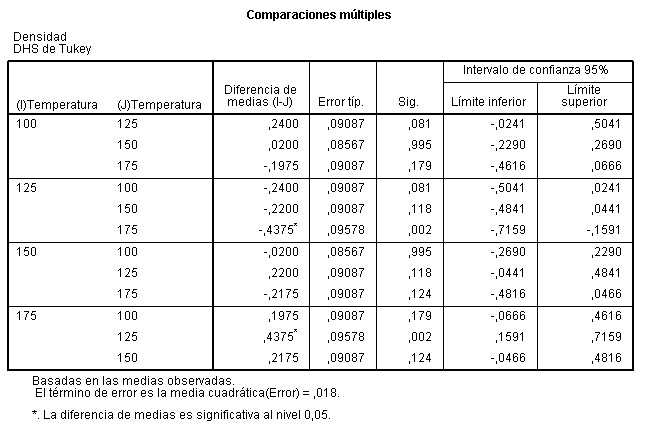
La tabla de comparaciones múltiples muestra los intervalos simultáneos construidos por el método de Tukey para cada posible combinación de temperaturas. Como se puede observar todos los intervalos de confianza construidos para las diferencias entre las densidades medias contienen al 0, excepto el correspondiente a la pareja de temperatura125 y 175. Lo que significa que todas las densidades medias no pueden considerarse distintas estadísticamente excepto las densidades medias correspondientes a las temperaturas de 125 y 175. Así mismo se observa que la significación asociada al contraste de las densidades medias correspondientes a estas temperaturas es inferior a 0.05, lo que se traduce en que existe evidencia empírica de que ambas densidades medias son diferentes significativamente.
Para poder analizar esta tabla más fácilmente la ponemos de la siguiente forma
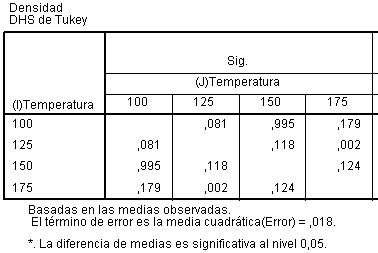
En esta tabla es más cómodo comparar cualquier pareja de temperaturas para saber si hay diferencias significativas. Se deduce que sólo se observan diferencias significativas entre las densidades de los fluidos cuando se ha modificado la temperatura a 125 y 175 grados (significación inferior a 0.05).
En la tabla Subconjuntos homogéneos asociada al contraste de Tukey se muestra por columnas los subgrupos de medias iguales. En nuestro estudio sobre las densidades de los fluidos se observan que las densidades medias del fluido analizado pueden considerarse similares cuando las temperaturas son 100, 125 y 150 y cuando son 100, 150 y 175 grados.
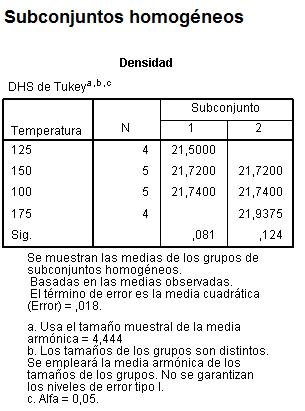
Tal y como se observa en la tabla, el p-valor asociado al primer grupo de temperaturas (100, 125 y 150) es 0.081, mayor que 0.05 lo que significa que no se puede rechazar la hipótesis de igualdad en las densidades medias para este subgrupo. Análogamente ocurre con el otro subgrupo formado, con un p-valor igual a 0.124. También se deduce qué subconjuntos difieren entre si, las densidades medias del primer grupo difieren de las del segundo. Y se observa que la densidad media mayor (21.9375) se obtiene para la temperatura de 175 y la menor (21.5) para la tremperatura de 125.
-
Estudiar las hipótesis del modelo: Homocedasticidad, independencia y normalidad.
Validar el modelo propuesto consiste en estudiar si las hipótesis básicas del modelo están o no en contradicción con los datos observados. Es decir, si se satisfacen los supuestos del modelo: Normalidad, Independencia y Homocedasticidad.
Hipótesis de Homocedasticidad
El primer aspecto que vamos a considerar es el de la homocedasticidad, la igualdad de varianzas. Para ello, a través del botón Opciones del menú Analizar/Modelo lineal general/Univariante, pulsando en Pruebas de homogeneidad se obtiene:
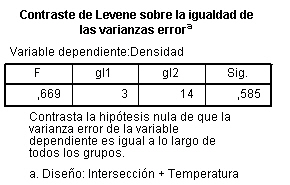
De donde se deduce a partir del valor de la significación, 0.585, que se puede asumir la igualdad de varianzas entre las densidades registradas para las diferentes temperaturas.
Gráficamente, representamos las barras de error para la desviación típica seleccionando en el menú principal Gráficos/Cuadros de diálogo antiguos/Barras de error
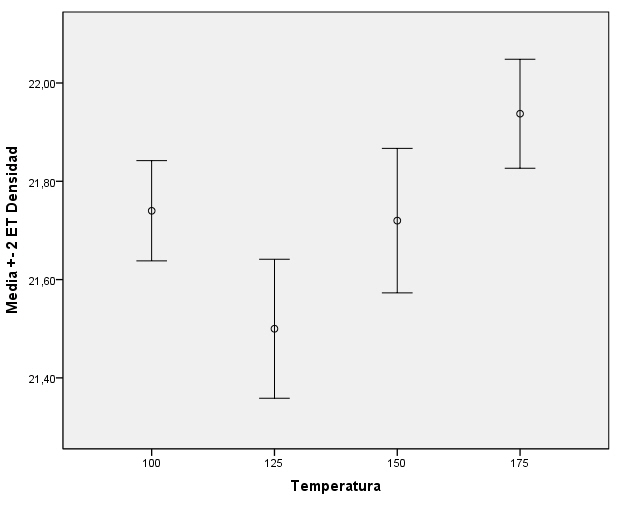 Se obtiene para cada grupo de temperaturas una representación gráfica de la densidad media (círculo de cada una de las barras) y dos desviaciones típicas a izquierda y derecha del promedio. Se observa una mayor dispersión en la densidad para las temperaturas 125 y 150. Este gráfico no aporta evidencias sobre la homogeneidad de las varianzas, por lo que siempre habrá que recurrir al contraste de Levene para dicha comparación.
Se obtiene para cada grupo de temperaturas una representación gráfica de la densidad media (círculo de cada una de las barras) y dos desviaciones típicas a izquierda y derecha del promedio. Se observa una mayor dispersión en la densidad para las temperaturas 125 y 150. Este gráfico no aporta evidencias sobre la homogeneidad de las varianzas, por lo que siempre habrá que recurrir al contraste de Levene para dicha comparación.
Hipótesis de Independencia
Para comprobar que se satisface el supuesto de independencia entre los residuos, representamos gráficamente los residuos frente a los valores pronosticados. La presencia de alguna tendencia en el gráfico puede indicar la alteración de dicha hipótesis. Seleccionando Opciones en el cuadro de diálogo de Análisis Univariante, se selecciona la casilla Gráfico de los residuos y se obtienen los gráficos de residuos asociados al análisis
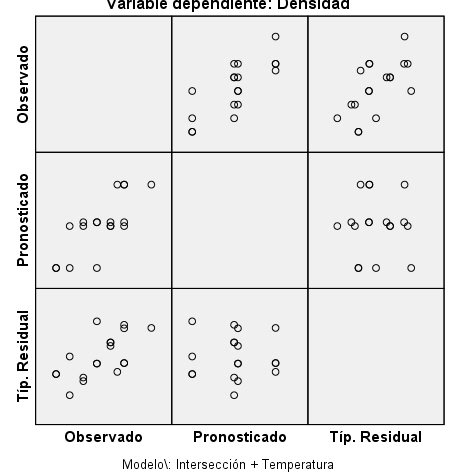
En el gráfico de la tercera fila y la segunda columna (residuos frente a valores pronosticados) no se observa ninguna tendencia concreta lo que muestra la no existencia de relación de dependencia.
Hipótesis de Normalidad
En primer lugar analizamos la normalidad de las densidades y continuaremos con el análisis de la normalidad de los residuos. Se selecciona en SPSS Analizar/Estadísticos descriptivos/Explorar y se obtienen los ajustes de normalidad
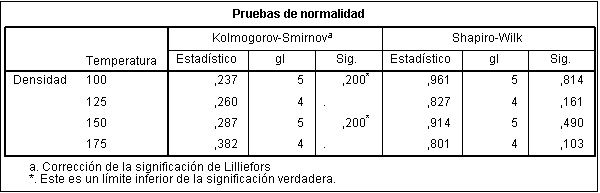
El contraste de Shapiro-Wilk (apropiado dado que el número total de datos es inferior a 50), muestra p-valores siempre superiores a 0.05, por lo que podemos concluir que las densidades se distribuyen según una normal para cada temperatura considerada en el estudio.
Para contrastar la hipótesis de Normalidad de los residuos recurriremos a procedimientos gráficos y analíticos. Para ello, en primer lugar se calculan los residuos tipificados asociados al ajuste univariante.
Para obtener el histograma de los residuos se selecciona en el menú principal de SPSS, Gráficos/Cuadros de diálogo antiguos/Histograma. Aunque podemos observar algunas desviaciones de la normalidad en el histograma, estas no implican la ausencia de normalidad de los residuos como se comprueba con el gráfico probabilístico normal (Analizar/Estadísticos Descriptivos/Gráficos QQ ).
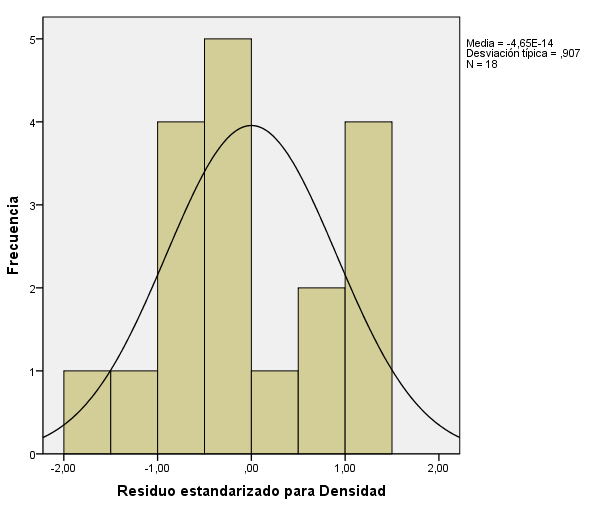
 El análisis numérico se llevará a cabo a través del contraste de Kolmogorov-Smirnov, Analizar/Pruebas no paramétricas/Cuadros de diálogo antiguos/K-S de 1 muestra
El análisis numérico se llevará a cabo a través del contraste de Kolmogorov-Smirnov, Analizar/Pruebas no paramétricas/Cuadros de diálogo antiguos/K-S de 1 muestra
 El valor del p- valor (significación = 0.637) es mayor que el nivel de significación, 0.05, por lo que se puede confirmar la normalidad de los residuos.
El valor del p- valor (significación = 0.637) es mayor que el nivel de significación, 0.05, por lo que se puede confirmar la normalidad de los residuos.
-
¿Se puede afirmar que las temperaturas de 100 y 125 producen menos densidades de fluido en promedio que las temperaturas de 150 y 175?
El contraste de hipótesis que se debe resolver para contestar este apartado es:
![]() Para realizarlo con SPSS, en Analizar/Comparar medias/Anova de un factor… pulsamos Contrastes. Introduciendo los correspondientes coeficientes se obtiene la siguiente salida
Para realizarlo con SPSS, en Analizar/Comparar medias/Anova de un factor… pulsamos Contrastes. Introduciendo los correspondientes coeficientes se obtiene la siguiente salida

 Para interpretar la tabla, asumimos en todos los contrastes la homocedasticidad, observamos que el p-valor vale 0.006 menor que el nivel de significación 0.05. Por lo tanto, se rechaza la hipótesis nula y se deduce que las temperaturas de 100 y 125 conjuntamente producen menos densidades de fluido en promedio que las temperaturas de 150 y 175 conjuntamente.
Para interpretar la tabla, asumimos en todos los contrastes la homocedasticidad, observamos que el p-valor vale 0.006 menor que el nivel de significación 0.05. Por lo tanto, se rechaza la hipótesis nula y se deduce que las temperaturas de 100 y 125 conjuntamente producen menos densidades de fluido en promedio que las temperaturas de 150 y 175 conjuntamente.
Ejercicio Propuesto 2 (Resuelto)
Un laboratorio de reciclaje controla la calidad de los plásticos utilizados en bolsas. Se desea contrastar si existe variabilidad en la calidad de los plásticos que hay en el mercado. Para ello, se eligen al azar cuatro plásticos y se les somete a una prueba para medir el grado de resistencia a la degradación ambiental. De cada plástico elegido se han seleccionado ocho muestras y los resultados de la variable que mide la resistencia son los de la tabla adjunta.
Figura 35: Tabla de datos del Ejercicio Propuesto2.doc
¿Qué conclusiones se deducen de este experimento?
Solución:
En este modelo, se supone que las variables τi son variables aleatorias normales independientes con media 0 y varianza común ![]() .
.
Dado que trabajamos con el modelo de efectos aleatorios, analizar si las medias poblacionales son iguales será equivalente a contrastar:
![]()
No rechazar H0 será equivalente a afirmar que no hay variedad en los efectos de los tratamientos, es decir, que la resistencia que ofrecen los plásticos empleados en la fabricación de bolsas de cara a la degradación ambiental es la misma.
Plantearemos el contraste a partir de la información de que disponemos:
- Variable respuesta: Resistencia a la degradación ambiental.
- Factor: Tipo de plástico.
- Modelo equilibrado: Cada uno de los niveles del factor tienen el mismo número de observaciones.
- Tamaño del experimento: Número total de observaciones (40 unidades experimentales).
Comenzaremos definiendo las variables e introduciendo los datos:
Para formular el contraste, en el menú principal se selecciona Analizar/Modelo lineal general/Univariante … En la ventana resultante introducimos Resitencia en la Variable dependiente: y Tipo de plástico como Factor aleatorio. Pulsando Aceptar, obtenemos la tabla ANOVA:
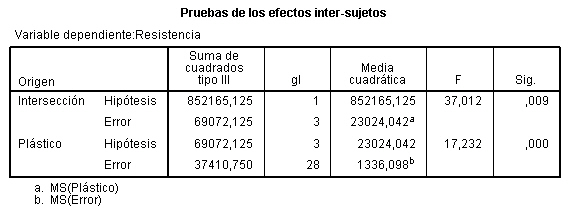
El valor del estadístico de contraste 17.232 deja a su derecha un p-valor menor que 0.001, rechazando la Hipótesis nula tanto a un nivel de significación del 5% como del 1%. Podemos concluir que los datos muestran evidencias de variabilidad en la resistencia para la degradación ambiental según el tipo de plástico empleado en la fabricación de la bolsa.
Dado que estamos ante un modelo de efectos aleatorios, no tenemos que realizar contrastes adicionales para comprobar qué medias son diferentes, ya que la respuesta es generalizada a todos los tipos de plásticos.
La media cuadrática esperada, así como los cálculos necesarios para la obtención de las esperanzas de los cuadrados medios del factor y del error vienen dados en la tabla:
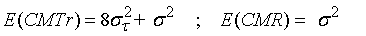
![]() A partir de estas expresiones se pueden estimar las componentes de la varianza
A partir de estas expresiones se pueden estimar las componentes de la varianza ![]() y σ2
y σ2
Para determinar el valor concreto de estas estimaciones se selecciona, Analizar/Modelo lineal general/Componentes de la varianza. En la ventana Opciones se selecciona ANOVA en Método y Tipo III en Sumas de Cuadrados. Pulsando en Continuar y Aceptar, se obtienen las estimaciones de las componentes de la varianza:

![]() La varianza total, 4047.091, se descompone en una parte atribuible a la diferencia entre los plásticos, 2710.993, y otra debida a la variabilidad existente dentro de ellos, 1336.098.
La varianza total, 4047.091, se descompone en una parte atribuible a la diferencia entre los plásticos, 2710.993, y otra debida a la variabilidad existente dentro de ellos, 1336.098.
En la varianza total, tiene mayor peso la variación debida al tipo de plástico empleado en la fabricación de la bolsa (66.98%) que la originada dentro de los plásticos (33.013%).
Ejercicio Propuesto 3 (Resuelto)
Debido a la proliferación de los campos de golf y a la gran cantidad de agua que necesitan, un grupo de científicos estudia la calidad de varios tipos de césped para implantarlo en invierno en los campos de golf. Para ello, miden la distancia recorrida por una pelota de golf, en el campo, después de bajar por una rampa (para proporcionar a la pelota una velocidad inicial constante). El terreno del que disponen tiene mayor pendiente en la dirección norte-sur, por lo que se aconseja dividir el terreno en cinco bloques de manera que las pendientes de las parcelas individuales dentro de cada bloque sean las mismas. Se utilizó el mismo método para la siembra y las mismas cantidades de semilla. Las mediciones son las distancias desde la base de la rampa al punto donde se pararon las pelotas. En el estudio se incluyeron las variedades: Agrostis Tenuis (Césped muy fino y denso, de hojas cortas y larga duración), Agrostis Canina (Hoja muy fina, estolonífera. Forma una cubierta muy tupida), Paspalum Notatum (Hojas gruesas, bastas y con rizomas. Forma una cubierta poco densa), Paspalum Vaginatum (Césped fino, perenne, con rizomas y estolones).
Se pide:
-
Identificar los elementos del estudio (factores, unidades experimentales, variable respuesta, etc.) y plantear detalladamente el modelo matemático utilizado en el experimento.
- ¿Son los bloques fuente de variación?
- Existen diferencias reales entre las distancias medias recorridas por una pelota de golf en los distintos tipos de césped?
- Estudiar las interacciones de los factores.
- Comprobar que se cumplen las hipótesis del modelo.
-
Utilizando el método de Newman-Keuls, ¿qué tipo de cesped ofrece menor resistencia al recorrido de las pelotas?
Solución:
- Identificar los elementos del estudio (factores, unidades experimentales, variable respuesta, etc.) y plantear detalladamente el modelo matemático utilizado en el experimento.
- Variable respuesta: Distancia.
- Factor: Tipo_Cesped que tiene cuatro niveles. Es un factor de efectos fijos ya que viene decidido qué niveles concretos se van a utilizar.
- Bloque: Bloques que tiene cinco niveles. Es un factor de efectos fijos ya que viene decidido qué niveles concretos se van a utilizar.
- Modelo completo: Los cuatro tratamientos se prueban en cada bloque exactamente una vez.
- Tamaño del experimento: Número total de observaciones (20).
Este experimento se modeliza mediante un diseño en Bloques completos al azar. El modelo matemático es:
![]()
- ¿Son los bloques fuente de variación?
Para resolver la cuestión planteada. Se selecciona, en el menú principal, Analizar/Modelo lineal general/ Univariante… En la salida correspondiente, se introduce en el campo Variable dependiente: La variable respuesta Distancia y en el campo Factores fijos: el factor Tipo_Cesped y el bloque Bloques. Para indicar que se trata de un modelo sin interacción entre los tratamientos y los bloques, se debe pinchar en Modelo e indicar en la salida correspondiente que es un modelo aditivo.
Por defecto, SPSS tiene marcado un modelo Factorial completo, por lo que hay que señalar Personalizado. En el modelo que estamos estudiando sólo aparecen los efectos principales de los dos factores, por lo tanto se selecciona en Tipo: Efectos principales y se pasan los dos factores, Tipo_Cesped y Bloque, al campo Modelo: Se pulsa Continuar y Aceptar.
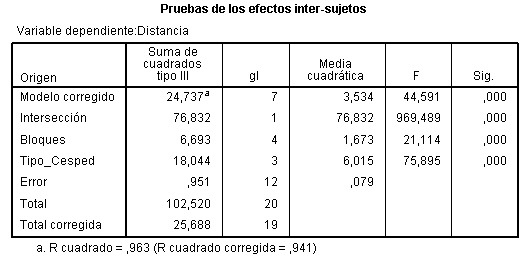
Puesto que la construcción de bloques se ha diseñado para comprobar el efecto de una variable, nos preguntamos si ha sido eficaz su construcción. En caso afirmativo, la suma de cuadrados de bloques explicaría una parte sustancial de la suma total de cuadrados. También se reduce la suma de cuadrados del error dando lugar a un aumento del valor del estadístico de contraste experimental utilizado para contrastar la igualdad de medias de los tratamientos y posibilitando que se rechace la Hipótesis nula, mejorándose la potencia del contraste.
La construcción de bloques puede ayudar cuando se comprueba su eficacia pero debe evitarse su construcción indiscriminada. Ya que, la inclusión de bloques en un diseño da lugar a una disminución del número de grados de libertad para el error, aumenta el punto crítico para contrastar la Hipótesis nula y es más difícil rechazarla. La potencia del contraste es menor.
La Tabla ANOVA, muestra que:
-
El valor del estadístico de contraste de igualdad de bloques, F = 21.114 deja a su derecha un p-valor menor que 0.001, inferior que el nivel de significación del 5%, por lo que se rechaza la Hipótesis nula de igualdad de bloques. La eficacia de este diseño depende de los efectos de los bloques. En este caso este diseño es más eficaz que el diseño completamente aleatorizado y el contraste principal de las medias de los tratamientos será más sensible a las diferencias entre tratamientos. Por lo tanto la inclusión del factor bloque en el modelo es acertada. Así, las distancias recorridas por las pelotas dependen del tipo de terreno.
-
El valor del estadístico de contraste de igualdad de tratamiento, F = 75.895 deja a su derecha un p-valor menor que 0.001, menor que el nivel de significación del 5%, por lo que se rechaza la Hipótesis nula de igualdad de tratamientos. Así, los tipos de césped influyen en las distancias recorridas por las pelotas. Es decir, existen diferencias significativas en las distancias recorridas por las pelotas entre los cuatro tipos de césped.
La salida de SPSS también nos muestra que R cuadrado vale 0.963, indicándonos que el modelo explica el 96.30% de la variabilidad de los datos.
-
¿Existen diferencias reales entre las distancias medias recorridas por una pelota de golf en los distintos tipos de cesped?
Esta cuestión está contestada afirmativamente en el apartado anterior, en el que la tabla ANOVA nos muestra un valor de F = 75.895 y un Sig. menor que 0.001.
- Estudiar las interacciones de los factores.
La interacción entre el factor bloque y los tratamientos se puede estudiar gráficamente de diversas formas:
Gráfico de residuos frente a los valores predichos por el modelo. Si este gráfico no presenta ningún aspecto curvilíneo se admite que el modelo es aditivo. Seleccionamos Opciones en el cuadro de diálogo de Univariante y marcamos la casilla Gráfico de los residuos. Se pulsa, Continuar y Aceptar
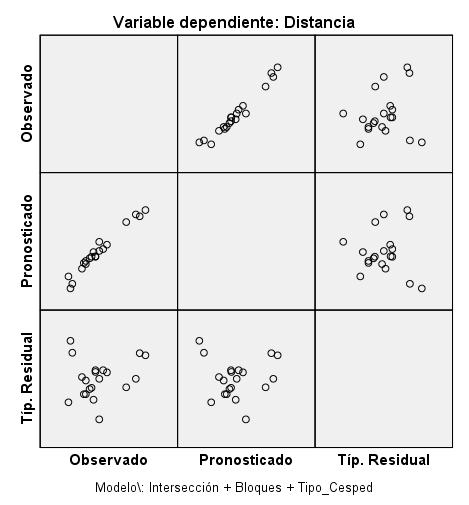 Interpretamos el gráfico que aparece en la fila 3 columna 2, es decir aquel gráfico que se representan los residuos en el eje de ordenadas y los valores pronosticados en el eje de abscisas. No observamos, en dicho gráfico, ninguna tendencia curvilínea, es decir no muestra evidencia de interacción entre el factor bloque y los tratamientos.
Interpretamos el gráfico que aparece en la fila 3 columna 2, es decir aquel gráfico que se representan los residuos en el eje de ordenadas y los valores pronosticados en el eje de abscisas. No observamos, en dicho gráfico, ninguna tendencia curvilínea, es decir no muestra evidencia de interacción entre el factor bloque y los tratamientos.
Gráfico de perfil.
Es un gráfico de las medias de los tratamientos, para realizarlo se selecciona, en el menú principal, Analizar/Modelo lineal general/ Univariante/Gráficos… se introduce en el Eje horizontal: Tipo_Cesped y en Líneas separadas: Bloques. Se pulsa Añadir, Continuar y Aceptar.
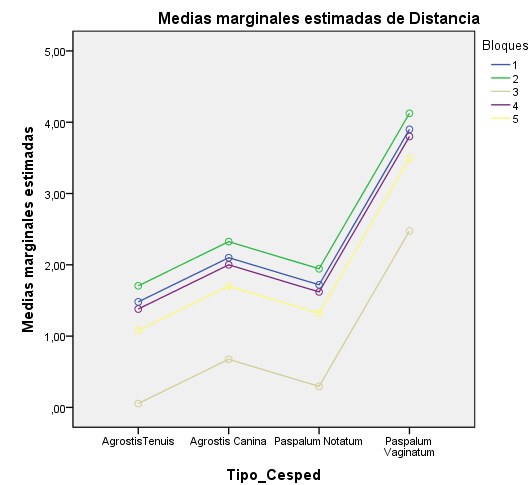
La figura representa el gráfico de las medias de los tratamientos. Cuando no existe interacción, los segmentos lineales que unen dos medias cualesquiera serán paralelos a través de los bloques. Es decir, es posible hacer consideraciones generales relativas a los tratamientos sin tener que especificar el bloque implicado. Podemos deducir, por ejemplo, que el césped Agrostis Tenuis presenta más resistencia al recorrido de las pelotas que los otros tipos de céspedes. Cuando estos segmentos no son paralelos se deduce que hay interacción entre los bloques y tratamientos. Esto significa que debemos tener cuidado cuando hagamos declaraciones relativas a los tratamientos, porque el bloque implicado es también importante.
-
Comprobar que se cumplen las hipótesis del modelo
Hipótesis de normalidad
En primer lugar se deben salvar los residuos y a continuación realizamos el estudio de la normalidad mediante el Gráfico probabilístico Normal y el Contraste de Kolmogorov-Smirnov.
Gráfico probabilístico Normal: Se selecciona en el menú principal, Analizar/Estadísticos descriptivos/Gráficos Q-Q. Se introduce en el campo Variables: la variable que recoge los residuos RES_1. Se pulsa Aceptar
 Podemos apreciar en este gráfico que los puntos aparecen próximos a la línea diagonal. Esta gráfica no muestra una desviación marcada de la normalidad.
Podemos apreciar en este gráfico que los puntos aparecen próximos a la línea diagonal. Esta gráfica no muestra una desviación marcada de la normalidad.
Contraste de Kolmogorov-Smirnov: Se selecciona en el menú principal, Analizar/Pruebas no paramétricas/ Cuadros de diálogos antiguos/K-S de 1 muestra. Se introduce en el campo Lista Contrastar variables: la variable que recoge los residuos RES_1. Se pulsa Aceptar
 El valor del p-valor, 0.901, es mayor que el nivel de significación 0.05, aceptándose la hipótesis de normalidad.
El valor del p-valor, 0.901, es mayor que el nivel de significación 0.05, aceptándose la hipótesis de normalidad.
Independencia de los residuos
En el gráfico de los residuos realizado anteriormente, interpretamos el gráfico que aparece en la fila 3 columna 2, es decir aquel gráfico que se representan los residuos en el eje de ordenadas y los valores pronosticados en el eje de abscisas. No observamos, en dicho gráfico, ninguna tendencia sistemática que haga sospechar del incumplimiento de la suposición de independencia. Este gráfico también lo podemos realizar mediante un diagrama de dispersión de los residuos y las predicciones.
Homogeneidad de varianzas
En primer lugar comprobamos la homocedasticidad gráficamente, para ello se selecciona en el menú principal, Gráficos/Cuadros de diálogos antiguos/Barras de error… Y en la salida correspondiente seleccionar Simple y pulsar Definir. Se introduce en el campo Variable: La variable respuesta Distancia y en el campo Eje de categorías: el factor Tipo_Cesped. En Las barras representan se selecciona Desviación típica, en Multiplicador: 2 (nos interesa que la desviación típica esté multiplicada por dos). Se pulsa Aceptar 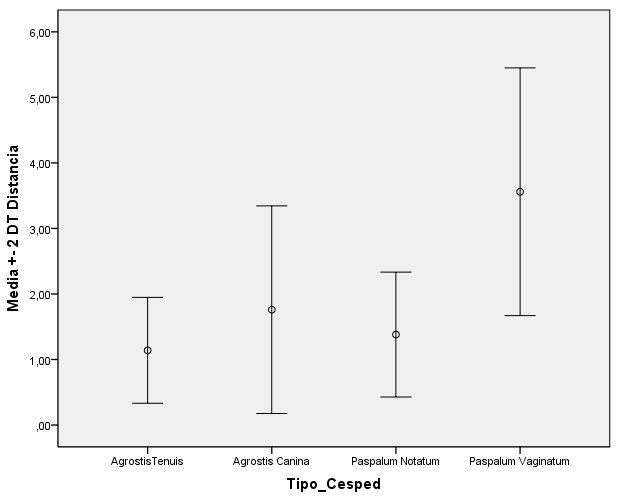 Cada grupo tiene su promedio (el círculo en cada una de las barras), dos desviaciones típicas a la izquierda y dos desviaciones típicas a la derecha del promedio. Observamos que en los tipos de césped Agrostis Canina y Paspalum Vaginatum hay mucha más dispersión que en los otros dos. Del gráfico no se deduce directamente si hay homogeneidad en las varianzas, por lo que recurrimos a analizarlo numéricamente mediante una prueba, el test de Levene.
Cada grupo tiene su promedio (el círculo en cada una de las barras), dos desviaciones típicas a la izquierda y dos desviaciones típicas a la derecha del promedio. Observamos que en los tipos de césped Agrostis Canina y Paspalum Vaginatum hay mucha más dispersión que en los otros dos. Del gráfico no se deduce directamente si hay homogeneidad en las varianzas, por lo que recurrimos a analizarlo numéricamente mediante una prueba, el test de Levene.
Realizamos el mismo gráfico para el factor bloque, para ello introducimos en el campo Eje de categorías: el factor Bloques.
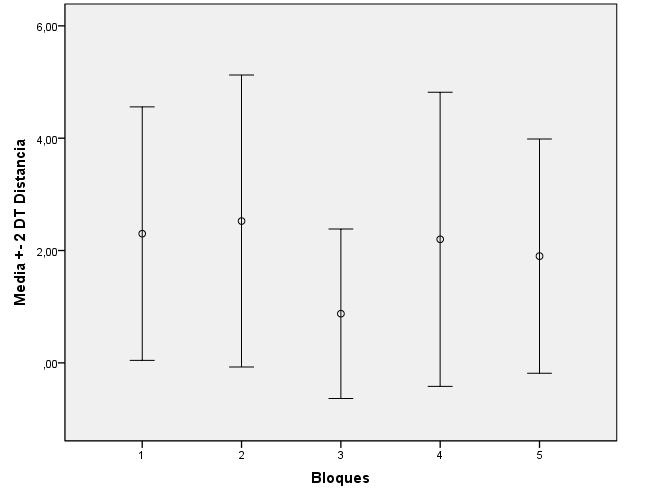 Observamos que en el Bloque 2 parece que hay mayor dispersión pero seguido a muy poca distancia del los Bloques 4, 1 y 5 y donde hay menos dispersión es en el Bloque 3. Como en el gráfico anterior, no se deduce directamente si hay homogeneidad en estas varianzas, por lo que recurrimos a analizarlo numéricamente mediante el test de Levene.
Observamos que en el Bloque 2 parece que hay mayor dispersión pero seguido a muy poca distancia del los Bloques 4, 1 y 5 y donde hay menos dispersión es en el Bloque 3. Como en el gráfico anterior, no se deduce directamente si hay homogeneidad en estas varianzas, por lo que recurrimos a analizarlo numéricamente mediante el test de Levene.
Para realizar el test de Levene mediante SPSS, se selecciona, en el menú principal, Analizar/Comparar medias/ANOVA de un factor. En la salida correspondiente, se introduce en el campo Lista de dependientes: La variable respuesta Distancia y en el campo Factor: el factor Tipo_Cesped. Se pulsa Opciones. Se selecciona Pruebas de homogeneidad de las varianzas y Gráfico de medias. Se pulsa Continuar y Aceptar

 El p-valor es 0.412 por lo tanto no se puede rechazar la hipótesis de homogeneidad de las varianzas y se concluye que los tres grupos tienen varianzas homogéneas.
El p-valor es 0.412 por lo tanto no se puede rechazar la hipótesis de homogeneidad de las varianzas y se concluye que los tres grupos tienen varianzas homogéneas.
En el gráfico de medias, donde en el eje de ordenadas figuran las medias de las distancias recorridas por las pelotas y en el eje de abscisas los tipos de césped. En esta gráfica observamos que la mayor distancia recorrida se produce en el tratamiento 4 (Paspalum Vaginatum) y el número más bajo se produce con el tratamiento1 (Agrostis Tenuis). Para saber entre que parejas de tratamientos estas diferencias son significativas se realiza una prueba Post-hoc.
Realizamos el mismo contraste para los bloques, ya que hay que comprobar la homocedasticidad tanto en los tratamientos como en los bloques. En este caso se introduce en el campo Factor: Bloques.

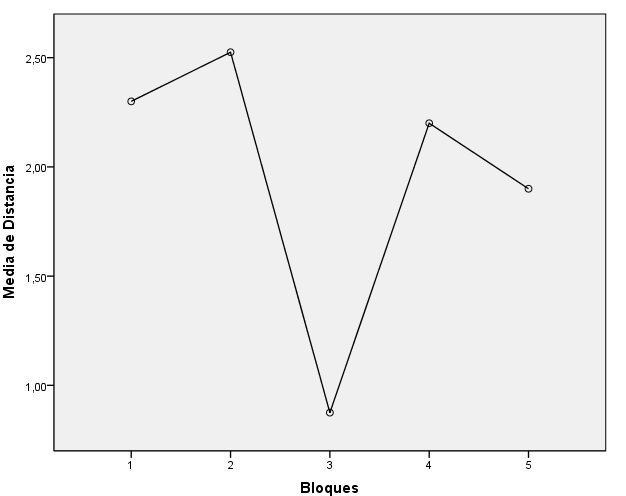 El p-valor es 0.899 por lo tanto no se puede rechazar la hipótesis de homogeneidad de las varianzas entre los bloques y se concluye que los diez grupos tienen varianzas homogéneas.
El p-valor es 0.899 por lo tanto no se puede rechazar la hipótesis de homogeneidad de las varianzas entre los bloques y se concluye que los diez grupos tienen varianzas homogéneas.
En esta gráfica observamos que la mayor distancia recorrida se produce en el Bloque 2 y el número más bajo se produce en el Bloque 3. Para saber entre que parejas de Bloques estas diferencias son significativas, aplicamos una prueba Post-hoc.
-
Utilizando el métdodo de Newman-Keuls, ¿qué tipo de cesped ofrece menor resistencia al recorrido de las pelotas?
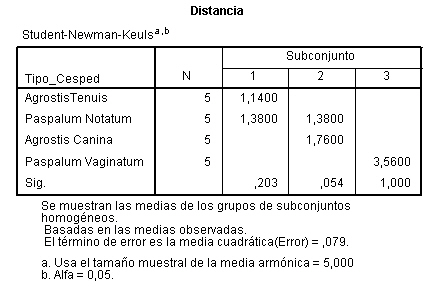 A partir de los resultados obtenidos, se deduce que las distancias medias recorridas por las pelotas son similares para los céspedes Agrostis Tenuis y Paspalum Notatum por una parte, también son similares en el Paspalum Notatum y Agrostis Canina, y en ambos grupos dichas distancias medias difieren significativamente de las recorridas en el césped Paspalum Vaginatum. Por lo tanto, se pueden establecer tres agrupaciones con características similares para las distancias medias recorridas. El tipo de césped que ofrece menor resistencia al recorrido de las pelotas es el Paspalum Vaginatum, donde las pelotas tienen un recorrido medio de 3.56 u.d.
A partir de los resultados obtenidos, se deduce que las distancias medias recorridas por las pelotas son similares para los céspedes Agrostis Tenuis y Paspalum Notatum por una parte, también son similares en el Paspalum Notatum y Agrostis Canina, y en ambos grupos dichas distancias medias difieren significativamente de las recorridas en el césped Paspalum Vaginatum. Por lo tanto, se pueden establecer tres agrupaciones con características similares para las distancias medias recorridas. El tipo de césped que ofrece menor resistencia al recorrido de las pelotas es el Paspalum Vaginatum, donde las pelotas tienen un recorrido medio de 3.56 u.d.
Ejercicio Propuesto 4 (Resuelto)
Consideremos de nuevo el ejercicio propuesto 3 sobre un grupo de científicos que estudia la calidad de varios tipos de césped para implantarlo en invierno en los campos de golf. Para ello, miden la distancia recorrida por una pelota de golf, en el campo, después de bajar por una rampa (para proporcionar a la pelota una velocidad inicial constante). El terreno del que disponen tiene mayor pendiente en la dirección norte-sur, por lo que se aconseja dividir el terreno en cinco bloques de manera que las pendientes de las parcelas individuales dentro de cada bloque sean las mismas. Se utilizó el mismo método para la siembra y las mismas cantidades de semilla. Las mediciones son las distancias desde la base de la rampa al punto donde se pararon las pelotas, y al realizar dichas mediciones no se han podido obtener una para cada combinación de tipo de césped y tipo de terreno, sino que sólo se han podido realizar con tres de las variedades del césped en cada uno de los bloques de terreno. Para controlar el efecto del tipo de terreno deciden utilizar un diseño en bloques incompletos. En el estudio se incluyeron las variedades: Agrostis Tenuis (Césped muy fino y denso, de hojas cortas y larga duración), Agrostis Canina (Hoja muy fina, estolonífera. Forma una cubierta muy tupida), Paspalum Notatum (Hojas gruesas, bastas y con rizomas. Forma una cubierta poco densa), Paspalum Vaginatum (Césped fino, perenne, con rizomas y estolones).
Se pide:
-
Identificar los elementos del estudio (factores, unidades experimentales, variable respuesta, etc.) y plantear detalladamente el modelo matemático utilizado en el experimento.
- ¿Son los bloques fuente de variación?
- Existen diferencias reales entre las distancias medias recorridas por una pelota de golf en los distintos tipos de césped?
- Comprobar que se cumplen las hipótesis del modelo.
-
Utilizando el método de Newman-Keuls, ¿qué tipo de cesped ofrece menor resistencia al recorrido de las pelotas?
Solución:
Para resolver las cuestiones planteadas sobre los tratamientos y los bloques, en el menú principal se selecciona: Analizar\Modelo lineal general\Univariante… Introduciendo la información relativa al diseño en la ventana de análisis: La variable dependiente es la Distancia y el resto de variables, Tipo_Cesped y Bloques corresponden a los factores fijos del modelo. En la opción Modelo, hay que indicar al programa que se trata de un modelo sin interacción entre los tratamientos y los bloques. Además hay que tener en cuenta que se trata de un diseño en bloques incompletos. En este tipo de diseño los tratamientos no están en todos los bloques, entonces los bloques y tratamientos no son ortogonales (como lo son en el diseño de bloques completos al azar), por lo tanto no es posible realizar una descomposición de la variabilidad del experimento como en el diseño en bloques completos. Para resolver está cuestión, SPSS utiliza las Sumas de cuadrados de tipo I.
- Para evaluar el efecto de los bloques, la suma de cuadrados de bloques debe ajustarse por tratamientos, por lo tanto primero se introducen los tratamientos y después los bloques.
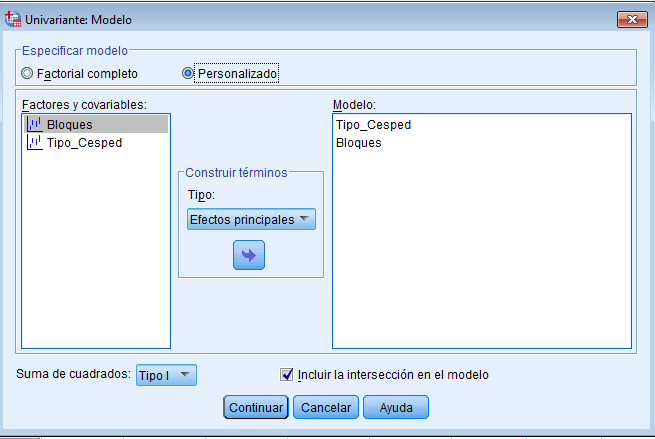
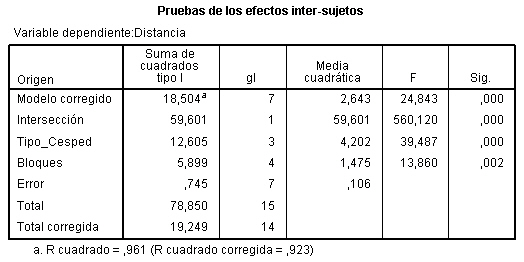 De la tabla ANOVA se deduce que los bloques son una fuente de variación.
De la tabla ANOVA se deduce que los bloques son una fuente de variación.
- Para evaluar el efecto de los tratamientos, la suma de cuadrados de tratamientos debe ajustarse por bloques, por lo tanto primero se introducen los bloques y después los tratamientos
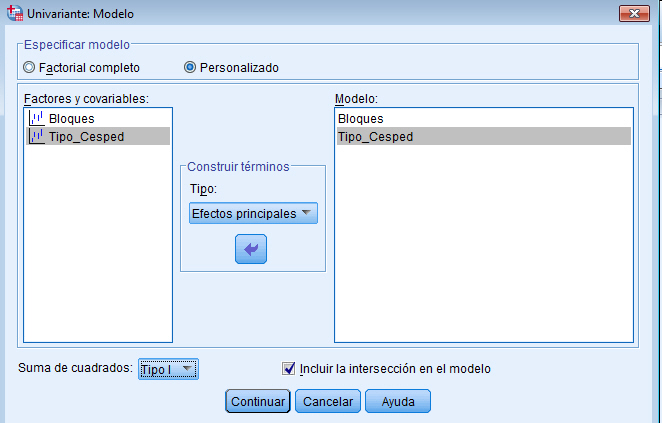
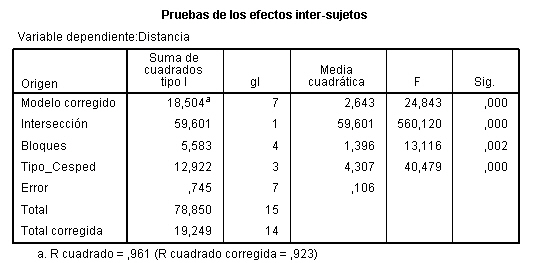
Se observa en la tabla ANOVA que hay diferencias reales entre las distancias medias recorridas por una pelota de golf en los distintos tipos de césped ya que el p-valor es menor que 0.001.
Ejercicio Propuesto 5 (Resuelto)
Un investigador quiere evaluar la productividad de cuatro variedades de aguacates, A, B, C y D. Para ello decide realizar el ensayo en un terreno que posee un gradiente de pendiente de oriente a occidente y además, diferencias en la disponibilidad de Nitrógeno de norte a sur, para controlar los efectos de la pendiente y la disponibilidad de Nitrógeno, utilizó un diseño de cuadrado latino, los datos corresponden a la producción en kg/parcela.
Responder a las siguientes cuestiones:
-
¿Se puede afirmar que la productividad media de las cuatro variedades de aguacate es la misma?
-
¿Qué supuestos han de verificarse?
- ¿Se obtiene la misma producción con las cuatro variedades de aguacate? En caso negativo, analizar mediante el procedimiento de Tukey, con qué variedad de aguacate hay mayor producción.
Solución:
-
¿Se puede afirmar que la productividad media de las cuatro variedades de aguacate es la misma?
El análisis de la productividad de las variedades de aguacate corresponde al análisis de un factor con 4 niveles. Dado que en el estudio intervienen dos fuentes de variación: la Disponibilidad de Nitrógeno y la Pendiente, se consideran dos factores de bloque, cada uno de ellos con 4 niveles.
Se pretende, entonces dar respuesta al contraste:
![]()
- Variable respuesta: Productividad
- Factor: Variedad de aguacate. Es un factor de efectos fijos ya que desde el principio se establecen los niveles concretos que se van a analizar.
- Bloques: Disponibilidad de Nitrógeno y Pendiente, ambos con 4 niveles y ambos de efectos fijos.
- Tamaño del experimento: Número total de observaciones (42) .
Para resolver el contraste planteado, en el menú principal se selecciona: Analizar\Modelo lineal general\Univariante… Introduciendo la información relativa al diseño en la ventana de análisis: La variable dependiente es la Productividad y el resto de variables, Nitrógeno, Pendiente y Variedad corresponden a los factores fijos del modelo. En la opción Modelo, hay que indicar al programa que se trata de un modelo sin interacción entre los tratamientos y los bloques
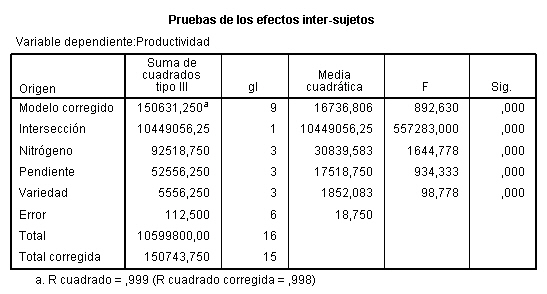 A la vista de los p-valores, todos ellos inferiores a 0.05, podemos afirmar que todos los efectos son significativos. Tanto las variedades de aguacates utilizadas, como la pendiente del terreno y la disponibilidad de nitrógeno influyen en la productividad de los aguacates.
A la vista de los p-valores, todos ellos inferiores a 0.05, podemos afirmar que todos los efectos son significativos. Tanto las variedades de aguacates utilizadas, como la pendiente del terreno y la disponibilidad de nitrógeno influyen en la productividad de los aguacates.
-
¿Qué supuestos han de verificarse?
Los supuestos que han de verificarse en un diseño de cuadrados latinos son Normalidad, Homocedasticidad e Independencia además del supuesto de aditividad entre filas, columnas y tratamientos (es decir, que no haya interacciones entre los mismos).
Hipótesis de normalidad
Gráfico probabilístico Normal: Se selecciona en el menú principal, Analizar/Estadísticos descriptivos/Gráficos Q-Q. Se introduce en el campo Variables: la variable que recoge los residuos RES_1. Se pulsa Aceptar
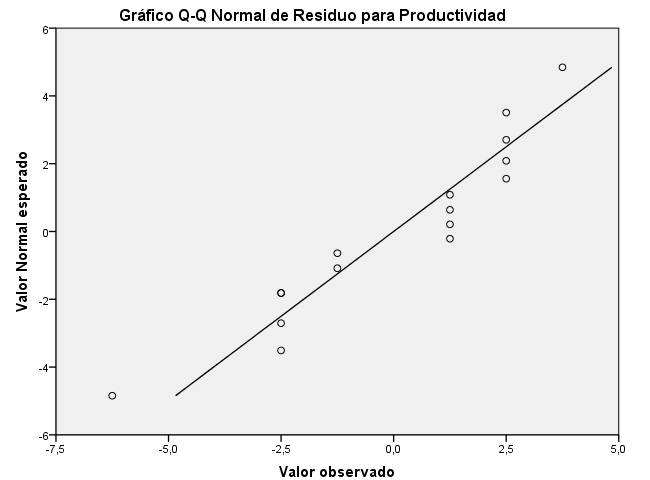 Contraste de Kolmogorov-Smirnov: Se selecciona en el menú principal, Analizar/Pruebas no paramétricas/ Cuadros de diálogos antiguos/K-S de 1 muestra. Se introduce en el campo Lista Contrastar variables: la variable que recoge los residuos RES_1. Se pulsa Aceptar
Contraste de Kolmogorov-Smirnov: Se selecciona en el menú principal, Analizar/Pruebas no paramétricas/ Cuadros de diálogos antiguos/K-S de 1 muestra. Se introduce en el campo Lista Contrastar variables: la variable que recoge los residuos RES_1. Se pulsa Aceptar
 El valor del p-valor, 0.323, es mayor que el nivel de significación 0.05, aceptándose la hipótesis de normalidad.
El valor del p-valor, 0.323, es mayor que el nivel de significación 0.05, aceptándose la hipótesis de normalidad.
Independencia entre los residuos
En el gráfico de los residuos
interpretamos el gráfico que aparece en la fila 3 columna 2. No observamos, en dicho gráfico, ninguna tendencia sistemática que haga sospechar del incumplimiento de la suposición de independencia.
Homogeneidad de varianzas
En primer lugar comprobamos la homocedasticidad gráficamente, para ello se selecciona en el menú principal, Gráficos/Cuadros de diálogos antiguos/Barras de error… Y en la salida correspondiente seleccionar Simple y pulsar Definir. Se introduce en el campo Variable: La variable respuesta Productividad y en el campo Eje de categorías: el factor Variedad. En Las barras representan se selecciona Desviación típica, en Multiplicador: 2 (nos interesa que la desviación típica esté multiplicada por dos). Se pulsa Aceptar
 Observamos que en las variedades de aguacates B y C hay mucha más dispersión que en las otras dos. Del gráfico no se deduce directamente si hay homogeneidad en estas varianzas, por lo que recurrimos analizarlo numéricamente mediante una prueba, el test de Levene.
Observamos que en las variedades de aguacates B y C hay mucha más dispersión que en las otras dos. Del gráfico no se deduce directamente si hay homogeneidad en estas varianzas, por lo que recurrimos analizarlo numéricamente mediante una prueba, el test de Levene.
Se debe realizar el mismo gráfico para cada uno de los factores de bloque.
Contraste de Levene: Se selecciona, en el menú principal, Analizar/Comparar medias/ANOVA de un factor. En la salida correspondiente, se introduce en el campo Lista de dependientes: La variable respuesta Productividad y en el campo Factor: el factor Variedad. Se pulsa Opciones. Se selecciona Pruebas de homogeneidad de las varianzas y Gráfico de medias. Se pulsa Continuar y Aceptar

 El p-valor es 0.167 por lo tanto no se puede rechazar la hipótesis de homogeneidad de las varianzas y se concluye que la cuatro variedades tienen varianzas homogéneas.
El p-valor es 0.167 por lo tanto no se puede rechazar la hipótesis de homogeneidad de las varianzas y se concluye que la cuatro variedades tienen varianzas homogéneas.
En el gráfico de medias, donde en el eje de ordenadas figuran las producciones medias de aguacates y en el eje de abscisas las cuatro variedades de aguacate. En esta gráfica observamos que la producción mayor se obtiene con la Variedad C y la producción más baja es la de la Variedad de aguacate B . Para saber entre qué parejas de tratamientos estas diferencias son significativas, se debe realizar una prueba Post-hoc.
Realizamos el mismo contraste para los bloques, ya que hay que comprobar la homocedasticidad tanto en los tratamientos como en los bloque

 Los p-valores son mayores que 0.05, por lo tanto no se puede rechazar la hipótesis de homogeneidad de las varianzas.
Los p-valores son mayores que 0.05, por lo tanto no se puede rechazar la hipótesis de homogeneidad de las varianzas.
Aditividad de los factores
Gráfico de residuos frente a los valores predichos por el modelo. Si el gráfico que aparece en la fila 3 columna 2 no presenta ningún aspecto curvilíneo se admite que el modelo es aditivo.
Gráfico de perfil. Es un gráfico de las medias de los tratamientos, realizamos los siguientes gráficos para comprobar la no interacción entre los factores
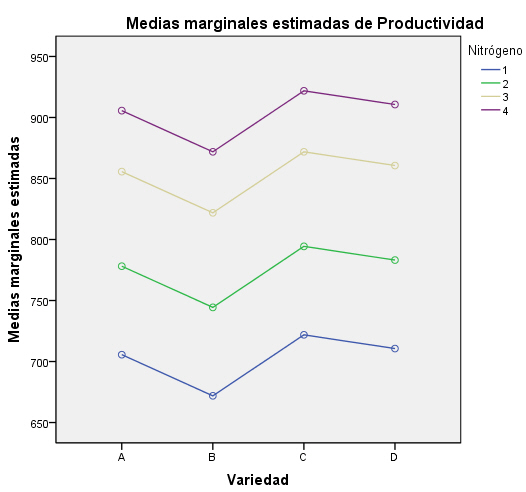 Cuando no existe interacción, los segmentos lineales que unen dos medias cualesquiera serán paralelos a través de los bloques. Es decir, es posible hacer consideraciones generales relativas a los tratamientos sin tener que especificar el bloque implicado. Cuando estos segmentos no son paralelos se deduce que hay interacción entre los bloques y tratamientos. Esto significa que debemos tener cuidado cuando hagamos declaraciones relativas a los tratamientos, porque el bloque implicado es también importante.
Cuando no existe interacción, los segmentos lineales que unen dos medias cualesquiera serán paralelos a través de los bloques. Es decir, es posible hacer consideraciones generales relativas a los tratamientos sin tener que especificar el bloque implicado. Cuando estos segmentos no son paralelos se deduce que hay interacción entre los bloques y tratamientos. Esto significa que debemos tener cuidado cuando hagamos declaraciones relativas a los tratamientos, porque el bloque implicado es también importante.
-
¿Se obtiene la misma producción con las cuatro variedades de aguacate? En caso negativo, analizar mediante el procedimiento de Tukey, con qué variedad de aguacate hay mayor producción.
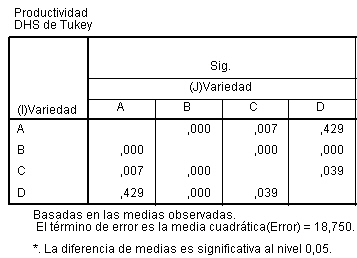 La tabla de comparaciones múltiples muestra los intervalos simultáneos construidos por el método de Tukey para cada posible combinación de variedades de aguacates. Como se puede observar, todos los intervalos de confianza construidos para las diferencias entre las producciones medias de las variedades no contienen al 0, excepto el correspondiente a la pareja de variedades de aguacates A y D. Lo que significa que todas las producciones medias pueden considerarse distintas estadísticamente excepto las producciones medias correspondientes a las variedades A y D. En la tabla de la derecha es más cómodo comparar cualquier pareja de variedades de aguacates para saber si hay diferencias significativas. Se deduce que únicamente no se observan diferencias significativas entre las producciones de las variedades de aguacates A y D (P-valor = 0.429).
La tabla de comparaciones múltiples muestra los intervalos simultáneos construidos por el método de Tukey para cada posible combinación de variedades de aguacates. Como se puede observar, todos los intervalos de confianza construidos para las diferencias entre las producciones medias de las variedades no contienen al 0, excepto el correspondiente a la pareja de variedades de aguacates A y D. Lo que significa que todas las producciones medias pueden considerarse distintas estadísticamente excepto las producciones medias correspondientes a las variedades A y D. En la tabla de la derecha es más cómodo comparar cualquier pareja de variedades de aguacates para saber si hay diferencias significativas. Se deduce que únicamente no se observan diferencias significativas entre las producciones de las variedades de aguacates A y D (P-valor = 0.429).
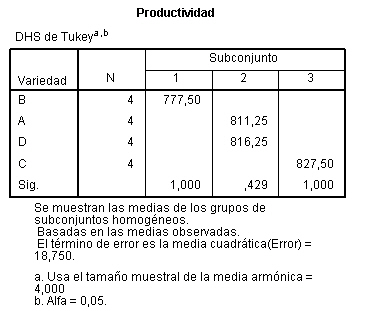 En la tabla Subconjuntos homogéneos asociada al contraste de Tukey se muestra por columnas los subgrupos de medias iguales. En nuestro estudio sobre las producciones de aguacates se observan que hay tres subgrupos homogéneos, al primer subgrupo pertenece la Variedad B, al segundo las variedades A y D y al tercero la Variedad C. Y se observa que la producción media mayor se obtiene con la Variedad C (827.5 Kg/ parcela) y la menor con la Variedad B (777.50 Kg/parcela).
En la tabla Subconjuntos homogéneos asociada al contraste de Tukey se muestra por columnas los subgrupos de medias iguales. En nuestro estudio sobre las producciones de aguacates se observan que hay tres subgrupos homogéneos, al primer subgrupo pertenece la Variedad B, al segundo las variedades A y D y al tercero la Variedad C. Y se observa que la producción media mayor se obtiene con la Variedad C (827.5 Kg/ parcela) y la menor con la Variedad B (777.50 Kg/parcela).
Ejercicio Propuesto 6 (Resuelto)
Consideremos de nuevo el ejercicio propuesto 5 del investigador que quiere evaluar la productividad de cuatro variedades de aguacate, A, B, C y D. Para ello, decide realizar el ensayo en un terreno que posee un gradiente de pendiente de oriente a occidente y además, diferencias en la disponibilidad de Nitrógeno de norte a sur. Se seleccionan cuatro disponibilidades de nitrógeno, pero sólo dispone de tres gradientes de pendiente. Para controlar estas posibles fuentes de variabilidad, el investigador decide utilizar un diseño en cuadrado de Youden con cuatro filas, las cuatro disponibilidades de Nitrógeno (NI, N2, N3, N4), tres columnas, los tres gradientes de pendientes (P1, P2, P3) y cuatro letras latinas, las variedades de aguacates (A, B, C, D). Los datos corresponden a la producción en kg/parcela.
Responder a las siguientes cuestiones:
-
Estudiar cuál es el tipo de diseño adecuado a este experimento y escribir el modelo matemático asociado.
-
¿Se puede afirmar qué la productividad media de las cuatro variedades de aguacate es la misma?
-
¿Qué supuestos han de verificarse?
- ¿Se obtiene la misma producción con las cuatro variedades de aguacate? En caso negativo, analizar mediante el procedimiento de Duncan, con qué variedad de aguacate hay mayor producción.
Solución:
El análisis de la productividad de las variedades de aguacate corresponde al análisis de un factor con 4 niveles. Dado que en el estudio intervienen dos fuentes de variación: la Disponibilidad de Nitrógeno y la Pendiente, se consideran dos factores de bloque, el primero con 4 niveles y el segundo con tres niveles.
Se pretende, entonces dar respuesta al contraste:
![]()
- Variable respuesta: Productividad.
- Factor: Variedad de aguacate. Es un factor de efectos fijos ya que desde el principio se establecen los niveles concretos que se van a analizar.
- Bloques: Disponibilidad de Nitrógeno y Pendiente, con 4 y 3 niveles, respectivamente y ambos de efectos fijos.
- Tamaño del experimento: Número total de observaciones: 12 .
Para resolver el contraste planteado, en el menú principal se selecciona: Analizar\Modelo lineal general\Univariante… Introduciendo la información relativa al diseño en la ventana de análisis: La variable dependiente es la Productividad y el resto de variables, Nitrógeno, Pendiente y Variedad corresponden a los factores fijos del modelo. En la opción Modelo, hay que indicar al programa que se trata de un modelo sin interacción entre los tratamientos y los bloques. Además hay que tener en cuenta que el diseño en cuadrados de Youden es un diseño en bloques incompletos por lo que hay que utilizar, para realizarlo mediante SPSS, las Sumas de cuadrados de Tipo I y tener en cuenta que para analizar un determinado factor hay que introducirlo en último lugar.
Los resultados del ANOVA dependerán del orden en que se introduzcan los factores.
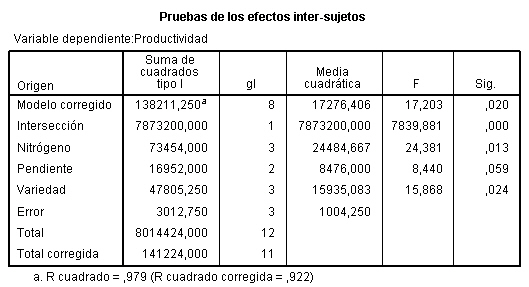 A la vista del valor de Sig. (0.024), podemos afirmar que en la productividad del aguacate influyen las distintas variedades utilizadas.
A la vista del valor de Sig. (0.024), podemos afirmar que en la productividad del aguacate influyen las distintas variedades utilizadas.
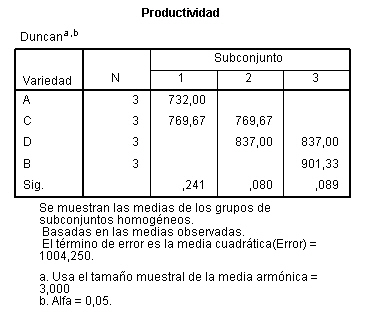 La mayor productividad de aguacates se obtiene con la Variedad B, con un productividad media de 901.33 Kg/parcela.
La mayor productividad de aguacates se obtiene con la Variedad B, con un productividad media de 901.33 Kg/parcela.
Ejercicio Propuesto 7 (Resuelto)
En un invernadero se está estudiando el crecimiento de determinadas plantas, para ello se quiere controlar los efectos del terreno, abono, insecticida y semilla. El estudio se realiza con cuatro tipos de semillas diferentes que se plantan en cuatro tipos de terreno, se les aplican cuatro tipos de abonos y cuatro tipos de insecticidas. La asignación de los tratamientos a las plantas se realiza de forma aleatoria. Para controlar estas posibles fuentes de variabilidad se decide plantear un diseño por cuadrados greco-latinos como el que se muestra en la siguiente tabla, donde las letras griegas corresponden a los cuatro tipos de semilla y las latinas a los abonos.
Responder a las siguientes cuestiones:
-
Estudiar cuál es el tipo de diseño adecuado a este experimento y escribir el modelo matemático asociado.
- ¿Qué supuestos han de verificarse?
- ¿Se puede afirmar que el crecimiento de las plantas es el mismo para los cuatro tipos de abonos?¿Y con los distintos insecticidas?
-
¿Existen diferencias significativas en el crecimiento de las plantas con las distintas semillas? ¿Y el tipo de tierra influye en dicho crecimiento?
-
¿Con qué tipo de semilla se produce el mayor crecimiento de las plantas?
- ¿El crecimiento de las plantas es el mismo utilizando al mismo tiempo los abonos A y B que utilizando los abonos C y D?
Solución:
 Son significativos todos los efectos de los factores y el mayor crecimiento de las plantas se produce con el Abono A siendo la altura que alcanza de 11.65 y la altura menor de 7.65 la alcanza cuando se le suministra el Abono C.
Son significativos todos los efectos de los factores y el mayor crecimiento de las plantas se produce con el Abono A siendo la altura que alcanza de 11.65 y la altura menor de 7.65 la alcanza cuando se le suministra el Abono C.
Para comprobar si el crecimiento de la planta es el mismo utilizando al mismo tiempo los abonos A y B que utilizando los abonos C y D, se debe realizar el siguiente contraste de hipótesis:
![]()
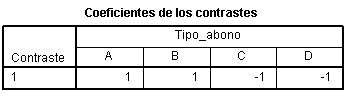

Suponiendo que se cumple la hipótesis de homocedasticidad, observamos un p-valor de 0.715 que indica que el contraste realizado no es significativo, por lo tanto se rechaza la hipótesis nula en el contraste planteado.
Ejercicio Propuesto 8 (Resuelto)
Se realiza un estudio sobre el efecto que produce la descarga de aguas residuales de una planta sobre la ecología del agua natural de un río. En el estudio se utilizaron dos lugares de muestreo. Un lugar está aguas arriba del punto en el que la planta introduce aguas residuales en la corriente; el otro está aguas abajo. Se tomaron muestras durante un periodo de cuatro semanas y se obtuvieron los datos sobre el número de diatomeas halladas. Los datos se muestran en la tabla adjunta:
Responder a las siguientes cuestiones:
-
Identificar el diseño adecuado a este experimento, escribir el modelo matemático y explicar los distintos elementos que intervienen.
-
Estudiar si la semana y el lugar son factores determinantes en el número de diatomeas halladas en el agua del río. ¿Hay posibilidad que una semana sea más recomendable en un lugar del río en concreto y no lo sea en el otro lugar?
-
Estudiar en qué semana se producen menos contaminación en el río, utilizando el método de Duncan.
-
Estudiar en qué lugar del río se producen menos diatomeas.
Solución:
-
Identificar el diseño adecuado a este experimento, escribir el modelo matemático y explicar los distintos elementos que intervienen.
![]()
-
-
Estudiar si la semana y el lugar son factores determinantes en el número de diatomeas halladas en el agua del río. ¿Hay posibilidad que una semana sea más recomendable en un lugar del río en concreto y no lo sea en el otro lugar?
-
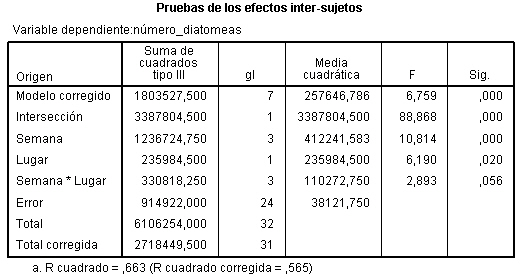
- Estudiar en qué semana se producen menos contaminación en el río, utilizando el método de Duncan.

- Estudiar en qué lugar del río se producen menos diatomeas..
Ejercicio Propuesto 9 (Resuelto)
La cotinina es uno de los principales metabolitos de la nicotina. Actualmente se le considera el mejor indicador de la exposición al humo de tabaco. Se ha realizado un estudio con distintas marcas de tabaco distinguiendo principalmente entre negro y rubio para detectar las posibles diferencias en el nivel de nicotina de personas expuestas al humo de tabaco. Para ello, se han analizado personas de distintas edades (niños, jóvenes y adultos) y se ha distinguido entre mujeres y hombres. Se han obtenido los datos de la siguiente tabla sobre el nivel de nicotina en miligramos por mililitro.
Responder a las siguientes cuestiones:
-
Identificar el diseño adecuado a este experimento, escribir el modelo matemático y explicar los distintos elementos que intervienen.
-
Contrastar la hipótesis nula de no interacción entre los factores. Adecuar el modelo al resultado de las interacciones y contrastar los efectos principales.
-
¿Hay diferencias significativas en el nivel de nicotina en las distintas edades?¿En qué edad el nivel de nicotina es mayor?
- ¿El tipo de tabaco es un factor determinante en el nivel de nicotina?
-
Comparar el nivel medio de nicotina entre las mujeres y los hombres. ¿Se detectan diferencias significativas?
Solución:
 El único efecto significativo son las distintas edades. Hay que seguir analizando el diseño suprimiendo una a una las interacciones, empezando por las de mayor orden.
El único efecto significativo son las distintas edades. Hay que seguir analizando el diseño suprimiendo una a una las interacciones, empezando por las de mayor orden.